 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunPhase: A Periodic Functional Autoencoder for Motion Generation via Phase Manifolds
Dec 10, 2025Learning natural body motion remains challenging due to the strong coupling between spatial geometry and temporal dynamics. Embedding motion in phase manifolds, latent spaces that capture local periodicity, has proven effective for motion prediction; however, existing approaches lack scalability and remain confined to specific settings. We introduce FunPhase, a functional periodic autoencoder that learns a phase manifold for motion and replaces discrete temporal decoding with a function-space formulation, enabling smooth trajectories that can be sampled at arbitrary temporal resolutions. FunPhase supports downstream tasks such as super-resolution and partial-body motion completion, generalizes across skeletons and datasets, and unifies motion prediction and generation within a single interpretable manifold. Our model achieves substantially lower reconstruction error than prior periodic autoencoder baselines while enabling a broader range of applications and performing on par with state-of-the-art motion generation methods.
Latent Functional Maps
Jun 21, 2024



Neural models learn data representations that lie on low-dimensional manifolds, yet modeling the relation between these representational spaces is an ongoing challenge. By integrating spectral geometry principles into neural modeling, we show that this problem can be better addressed in the functional domain, mitigating complexity, while enhancing interpretability and performances on downstream tasks. To this end, we introduce a multi-purpose framework to the representation learning community, which allows to: (i) compare different spaces in an interpretable way and measure their intrinsic similarity; (ii) find correspondences between them, both in unsupervised and weakly supervised settings, and (iii) to effectively transfer representations between distinct spaces. We validate our framework on various applications, ranging from stitching to retrieval tasks, demonstrating that latent functional maps can serve as a swiss-army knife for representation alignment.
Latent. Functional Map
Jun 20, 2024Neural models learn data representations that lie on low-dimensional manifolds, yet modeling the relation between these representational spaces is an ongoing challenge. By integrating spectral geometry principles into neural modeling, we show that this problem can be better addressed in the functional domain, mitigating complexity, while enhancing interpretability and performances on downstream tasks. To this end, we introduce a multi-purpose framework to the representation learning community, which allows to: (i) compare different spaces in an interpretable way and measure their intrinsic similarity; (ii) find correspondences between them, both in unsupervised and weakly supervised settings, and (iii) to effectively transfer representations between distinct spaces. We validate our framework on various applications, ranging from stitching to retrieval tasks, demonstrating that latent functional maps can serve as a swiss-army knife for representation alignment.
Process-Aware Analysis of Treatment Paths in Heart Failure Patients: A Case Study
Mar 11, 2024Process mining in healthcare presents a range of challenges when working with different types of data within the healthcare domain. There is high diversity considering the variety of data collected from healthcare processes: operational processes given by claims data, a collection of events during surgery, data related to pre-operative and post-operative care, and high-level data collections based on regular ambulant visits with no apparent events. In this case study, a data set from the last category is analyzed. We apply process-mining techniques on sparse patient heart failure data and investigate whether an information gain towards several research questions is achievable. Here, available data are transformed into an event log format, and process discovery and conformance checking are applied. Additionally, patients are split into different cohorts based on comorbidities, such as diabetes and chronic kidney disease, and multiple statistics are compared between the cohorts. Conclusively, we apply decision mining to determine whether a patient will have a cardiovascular outcome and whether a patient will die.
Vector Quantile Regression on Manifolds
Jul 03, 2023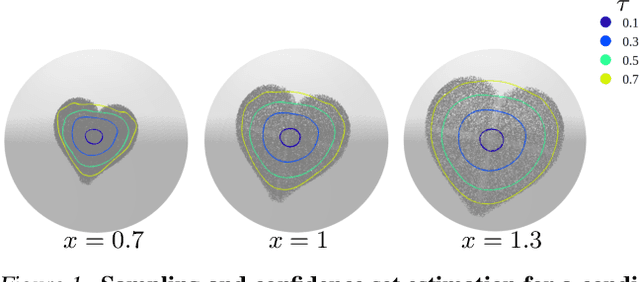
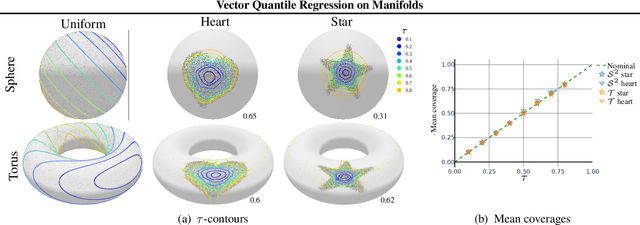
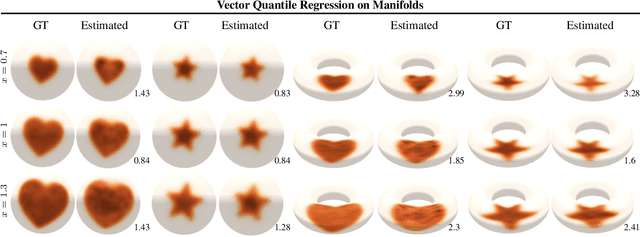
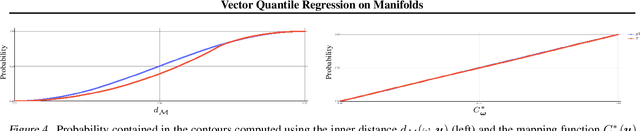
Quantile regression (QR) is a statistical tool for distribution-free estimation of conditional quantiles of a target variable given explanatory features. QR is limited by the assumption that the target distribution is univariate and defined on an Euclidean domain. Although the notion of quantiles was recently extended to multi-variate distributions, QR for multi-variate distributions on manifolds remains underexplored, even though many important applications inherently involve data distributed on, e.g., spheres (climate measurements), tori (dihedral angles in proteins), or Lie groups (attitude in navigation). By leveraging optimal transport theory and the notion of $c$-concave functions, we meaningfully define conditional vector quantile functions of high-dimensional variables on manifolds (M-CVQFs). Our approach allows for quantile estimation, regression, and computation of conditional confidence sets. We demonstrate the approach's efficacy and provide insights regarding the meaning of non-Euclidean quantiles through preliminary synthetic data experiments.
Performance-Preserving Event Log Sampling for Predictive Monitoring
Jan 18, 2023Predictive process monitoring is a subfield of process mining that aims to estimate case or event features for running process instances. Such predictions are of significant interest to the process stakeholders. However, most of the state-of-the-art methods for predictive monitoring require the training of complex machine learning models, which is often inefficient. Moreover, most of these methods require a hyper-parameter optimization that requires several repetitions of the training process which is not feasible in many real-life applications. In this paper, we propose an instance selection procedure that allows sampling training process instances for prediction models. We show that our instance selection procedure allows for a significant increase of training speed for next activity and remaining time prediction methods while maintaining reliable levels of prediction accuracy.
Resolving Uncertain Case Identifiers in Interaction Logs: A User Study
Nov 21, 2022



Modern software systems are able to record vast amounts of user actions, stored for later analysis. One of the main types of such user interaction data is click data: the digital trace of the actions of a user through the graphical elements of an application, website or software. While readily available, click data is often missing a case notion: an attribute linking events from user interactions to a specific process instance in the software. In this paper, we propose a neural network-based technique to determine a case notion for click data, thus enabling process mining and other process analysis techniques on user interaction data. We describe our method, show its scalability to datasets of large dimensions, and we validate its efficacy through a user study based on the segmented event log resulting from interaction data of a mobility sharing company. Interviews with domain experts in the company demonstrate that the case notion obtained by our method can lead to actionable process insights.
Process Modeling and Conformance Checking in Healthcare: A COVID-19 Case Study
Sep 22, 2022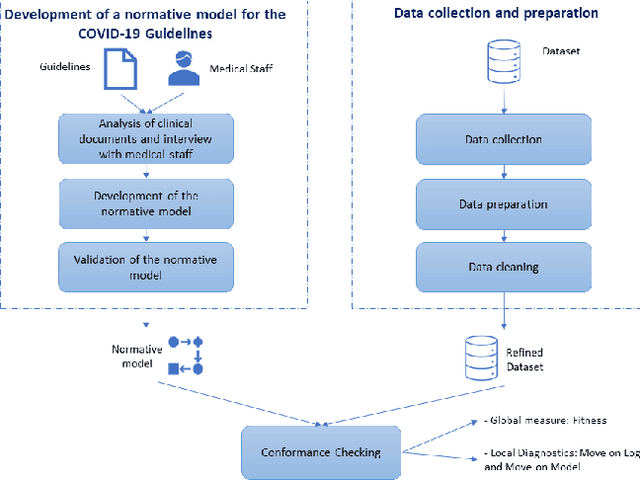


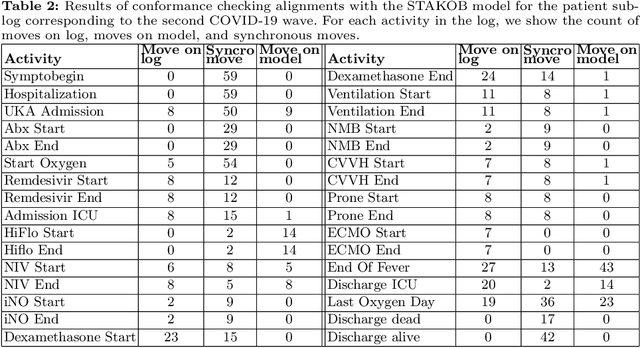
The discipline of process mining has a solid track record of successful applications to the healthcare domain. Within such research space, we conducted a case study related to the Intensive Care Unit (ICU) ward of the Uniklinik Aachen hospital in Germany. The aim of this work is twofold: developing a normative model representing the clinical guidelines for the treatment of COVID-19 patients, and analyzing the adherence of the observed behavior (recorded in the information system of the hospital) to such guidelines. We show that, through conformance checking techniques, it is possible to analyze the care process for COVID-19 patients, highlighting the main deviations from the clinical guidelines. The results provide physicians with useful indications for improving the process and ensuring service quality and patient satisfaction. We share the resulting model as an open-source BPMN file.
Harnessing spectral representations for subgraph alignment
Jun 06, 2022
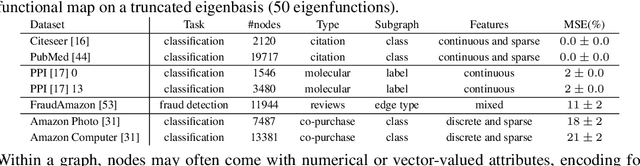
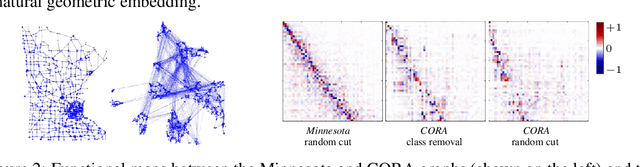

With the rise and advent of graph learning techniques, graph data has become ubiquitous. However, while several efforts are being devoted to the design of new convolutional architectures, pooling or positional encoding schemes, less effort is being spent on problems involving maps between (possibly very large) graphs, such as signal transfer, graph isomorphism and subgraph correspondence. With this paper, we anticipate the need for a convenient framework to deal with such problems, and focus in particular on the challenging subgraph alignment scenario. We claim that, first and foremost, the representation of a map plays a central role on how these problems should be modeled. Taking the hint from recent work in geometry processing, we propose the adoption of a spectral representation for maps that is compact, easy to compute, robust to topological changes, easy to plug into existing pipelines, and is especially effective for subgraph alignment problems. We report for the first time a surprising phenomenon where the partiality arising in the subgraph alignment task is manifested as a special structure of the map coefficients, even in the absence of exact subgraph isomorphism, and which is consistently observed over different families of graphs up to several thousand nodes.
Probabilistic and Non-Deterministic Event Data in Process Mining: Embedding Uncertainty in Process Analysis Techniques
May 11, 2022

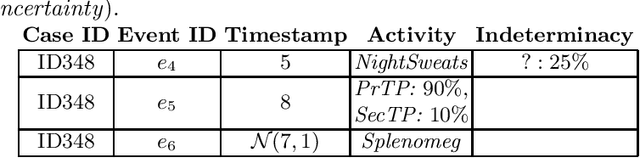

Process mining is a subfield of process science that analyzes event data collected in databases called event logs. Recently, novel types of event data have become of interest due to the wide industrial application of process mining analyses. In this paper, we examine uncertain event data. Such data contain meta-attributes describing the amount of imprecision tied with attributes recorded in an event log. We provide examples of uncertain event data, present the state of the art in regard of uncertainty in process mining, and illustrate open challenges related to this research direction.