 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAGE: Stemmed Accompaniment Generation through Prefix-Based Conditioning
Apr 09, 2025Recent advances in generative models have made it possible to create high-quality, coherent music, with some systems delivering production-level output. Yet, most existing models focus solely on generating music from scratch, limiting their usefulness for musicians who want to integrate such models into a human, iterative composition workflow. In this paper we introduce STAGE, our STemmed Accompaniment GEneration model, fine-tuned from the state-of-the-art MusicGen to generate single-stem instrumental accompaniments conditioned on a given mixture. Inspired by instruction-tuning methods for language models, we extend the transformer's embedding matrix with a context token, enabling the model to attend to a musical context through prefix-based conditioning. Compared to the baselines, STAGE yields accompaniments that exhibit stronger coherence with the input mixture, higher audio quality, and closer alignment with textual prompts. Moreover, by conditioning on a metronome-like track, our framework naturally supports tempo-constrained generation, achieving state-of-the-art alignment with the target rhythmic structure--all without requiring any additional tempo-specific module. As a result, STAGE offers a practical, versatile tool for interactive music creation that can be readily adopted by musicians in real-world workflows.
Stable-V2A: Synthesis of Synchronized Sound Effects with Temporal and Semantic Controls
Dec 19, 2024



Sound designers and Foley artists usually sonorize a scene, such as from a movie or video game, by manually annotating and sonorizing each action of interest in the video. In our case, the intent is to leave full creative control to sound designers with a tool that allows them to bypass the more repetitive parts of their work, thus being able to focus on the creative aspects of sound production. We achieve this presenting Stable-V2A, a two-stage model consisting of: an RMS-Mapper that estimates an envelope representative of the audio characteristics associated with the input video; and Stable-Foley, a diffusion model based on Stable Audio Open that generates audio semantically and temporally aligned with the target video. Temporal alignment is guaranteed by the use of the envelope as a ControlNet input, while semantic alignment is achieved through the use of sound representations chosen by the designer as cross-attention conditioning of the diffusion process. We train and test our model on Greatest Hits, a dataset commonly used to evaluate V2A models. In addition, to test our model on a case study of interest, we introduce Walking The Maps, a dataset of videos extracted from video games depicting animated characters walking in different locations. Samples and code available on our demo page at https://ispamm.github.io/Stable-V2A.
SelfGeo: Self-supervised and Geodesic-consistent Estimation of Keypoints on Deformable Shapes
Aug 05, 2024Unsupervised 3D keypoints estimation from Point Cloud Data (PCD) is a complex task, even more challenging when an object shape is deforming. As keypoints should be semantically and geometrically consistent across all the 3D frames - each keypoint should be anchored to a specific part of the deforming shape irrespective of intrinsic and extrinsic motion. This paper presents, "SelfGeo", a self-supervised method that computes persistent 3D keypoints of non-rigid objects from arbitrary PCDs without the need of human annotations. The gist of SelfGeo is to estimate keypoints between frames that respect invariant properties of deforming bodies. Our main contribution is to enforce that keypoints deform along with the shape while keeping constant geodesic distances among them. This principle is then propagated to the design of a set of losses which minimization let emerge repeatable keypoints in specific semantic locations of the non-rigid shape. We show experimentally that the use of geodesic has a clear advantage in challenging dynamic scenes and with different classes of deforming shapes (humans and animals). Code and data are available at: https://github.com/IIT-PAVIS/SelfGeo
* This paper has been accepted in ECCV 2024
COCOLA: Coherence-Oriented Contrastive Learning of Musical Audio Representations
Apr 29, 2024



We present COCOLA (Coherence-Oriented Contrastive Learning for Audio), a contrastive learning method for musical audio representations that captures the harmonic and rhythmic coherence between samples. Our method operates at the level of stems (or their combinations) composing music tracks and allows the objective evaluation of compositional models for music in the task of accompaniment generation. We also introduce a new baseline for compositional music generation called CompoNet, based on ControlNet, generalizing the tasks of MSDM, and quantify it against the latter using COCOLA. We release all models trained on public datasets containing separate stems (MUSDB18-HQ, MoisesDB, Slakh2100, and CocoChorales).
Generalized Multi-Source Inference for Text Conditioned Music Diffusion Models
Mar 18, 2024



Multi-Source Diffusion Models (MSDM) allow for compositional musical generation tasks: generating a set of coherent sources, creating accompaniments, and performing source separation. Despite their versatility, they require estimating the joint distribution over the sources, necessitating pre-separated musical data, which is rarely available, and fixing the number and type of sources at training time. This paper generalizes MSDM to arbitrary time-domain diffusion models conditioned on text embeddings. These models do not require separated data as they are trained on mixtures, can parameterize an arbitrary number of sources, and allow for rich semantic control. We propose an inference procedure enabling the coherent generation of sources and accompaniments. Additionally, we adapt the Dirac separator of MSDM to perform source separation. We experiment with diffusion models trained on Slakh2100 and MTG-Jamendo, showcasing competitive generation and separation results in a relaxed data setting.
Graph Generation via Spectral Diffusion
Feb 29, 2024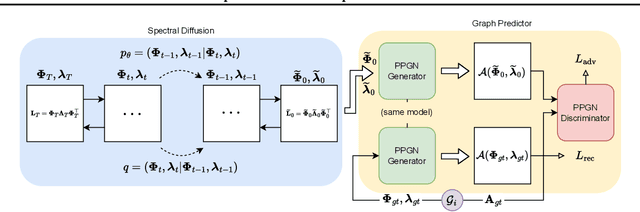
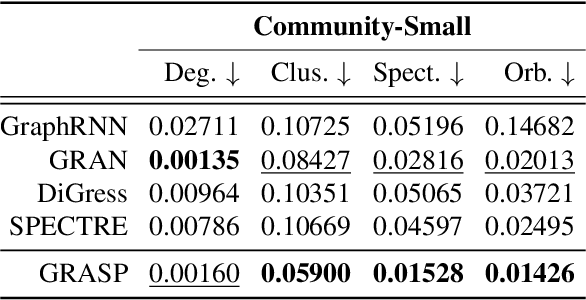
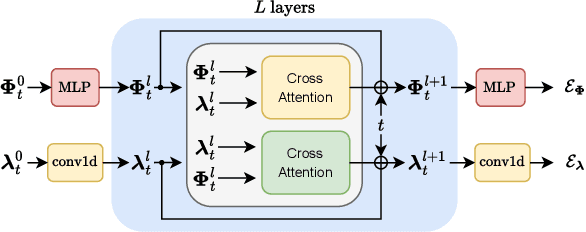
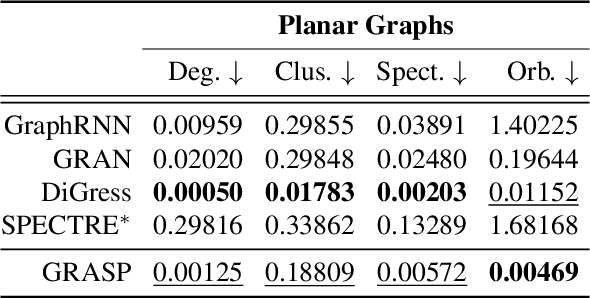
In this paper, we present GRASP, a novel graph generative model based on 1) the spectral decomposition of the graph Laplacian matrix and 2) a diffusion process. Specifically, we propose to use a denoising model to sample eigenvectors and eigenvalues from which we can reconstruct the graph Laplacian and adjacency matrix. Our permutation invariant model can also handle node features by concatenating them to the eigenvectors of each node. Using the Laplacian spectrum allows us to naturally capture the structural characteristics of the graph and work directly in the node space while avoiding the quadratic complexity bottleneck that limits the applicability of other methods. This is achieved by truncating the spectrum, which as we show in our experiments results in a faster yet accurate generative process. An extensive set of experiments on both synthetic and real world graphs demonstrates the strengths of our model against state-of-the-art alternatives.
GNN-LoFI: a Novel Graph Neural Network through Localized Feature-based Histogram Intersection
Jan 17, 2024Graph neural networks are increasingly becoming the framework of choice for graph-based machine learning. In this paper, we propose a new graph neural network architecture that substitutes classical message passing with an analysis of the local distribution of node features. To this end, we extract the distribution of features in the egonet for each local neighbourhood and compare them against a set of learned label distributions by taking the histogram intersection kernel. The similarity information is then propagated to other nodes in the network, effectively creating a message passing-like mechanism where the message is determined by the ensemble of the features. We perform an ablation study to evaluate the network's performance under different choices of its hyper-parameters. Finally, we test our model on standard graph classification and regression benchmarks, and we find that it outperforms widely used alternative approaches, including both graph kernels and graph neural networks.
Multi-Source Diffusion Models for Simultaneous Music Generation and Separation
Feb 07, 2023



In this work, we define a diffusion-based generative model capable of both music synthesis and source separation by learning the score of the joint probability density of sources sharing a context. Alongside the classic total inference tasks (i.e. generating a mixture, separating the sources), we also introduce and experiment on the partial inference task of source imputation, where we generate a subset of the sources given the others (e.g., play a piano track that goes well with the drums). Additionally, we introduce a novel inference method for the separation task. We train our model on Slakh2100, a standard dataset for musical source separation, provide qualitative results in the generation settings, and showcase competitive quantitative results in the separation setting. Our method is the first example of a single model that can handle both generation and separation tasks, thus representing a step toward general audio models.
Latent Autoregressive Source Separation
Jan 09, 2023Autoregressive models have achieved impressive results over a wide range of domains in terms of generation quality and downstream task performance. In the continuous domain, a key factor behind this success is the usage of quantized latent spaces (e.g., obtained via VQ-VAE autoencoders), which allow for dimensionality reduction and faster inference times. However, using existing pre-trained models to perform new non-trivial tasks is difficult since it requires additional fine-tuning or extensive training to elicit prompting. This paper introduces LASS as a way to perform vector-quantized Latent Autoregressive Source Separation (i.e., de-mixing an input signal into its constituent sources) without requiring additional gradient-based optimization or modifications of existing models. Our separation method relies on the Bayesian formulation in which the autoregressive models are the priors, and a discrete (non-parametric) likelihood function is constructed by performing frequency counts over latent sums of addend tokens. We test our method on images and audio with several sampling strategies (e.g., ancestral, beam search) showing competitive results with existing approaches in terms of separation quality while offering at the same time significant speedups in terms of inference time and scalability to higher dimensional data.
Harnessing spectral representations for subgraph alignment
Jun 06, 2022
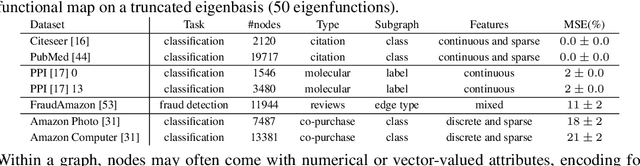
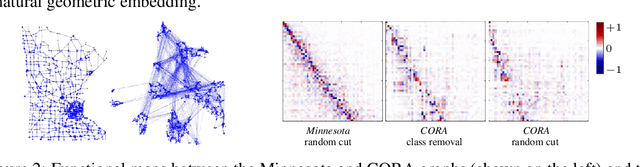

With the rise and advent of graph learning techniques, graph data has become ubiquitous. However, while several efforts are being devoted to the design of new convolutional architectures, pooling or positional encoding schemes, less effort is being spent on problems involving maps between (possibly very large) graphs, such as signal transfer, graph isomorphism and subgraph correspondence. With this paper, we anticipate the need for a convenient framework to deal with such problems, and focus in particular on the challenging subgraph alignment scenario. We claim that, first and foremost, the representation of a map plays a central role on how these problems should be modeled. Taking the hint from recent work in geometry processing, we propose the adoption of a spectral representation for maps that is compact, easy to compute, robust to topological changes, easy to plug into existing pipelines, and is especially effective for subgraph alignment problems. We report for the first time a surprising phenomenon where the partiality arising in the subgraph alignment task is manifested as a special structure of the map coefficients, even in the absence of exact subgraph isomorphism, and which is consistently observed over different families of graphs up to several thousand nodes.