 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOCOLA: Coherence-Oriented Contrastive Learning of Musical Audio Representations
Apr 29, 2024



We present COCOLA (Coherence-Oriented Contrastive Learning for Audio), a contrastive learning method for musical audio representations that captures the harmonic and rhythmic coherence between samples. Our method operates at the level of stems (or their combinations) composing music tracks and allows the objective evaluation of compositional models for music in the task of accompaniment generation. We also introduce a new baseline for compositional music generation called CompoNet, based on ControlNet, generalizing the tasks of MSDM, and quantify it against the latter using COCOLA. We release all models trained on public datasets containing separate stems (MUSDB18-HQ, MoisesDB, Slakh2100, and CocoChorales).
Generalized Multi-Source Inference for Text Conditioned Music Diffusion Models
Mar 18, 2024



Multi-Source Diffusion Models (MSDM) allow for compositional musical generation tasks: generating a set of coherent sources, creating accompaniments, and performing source separation. Despite their versatility, they require estimating the joint distribution over the sources, necessitating pre-separated musical data, which is rarely available, and fixing the number and type of sources at training time. This paper generalizes MSDM to arbitrary time-domain diffusion models conditioned on text embeddings. These models do not require separated data as they are trained on mixtures, can parameterize an arbitrary number of sources, and allow for rich semantic control. We propose an inference procedure enabling the coherent generation of sources and accompaniments. Additionally, we adapt the Dirac separator of MSDM to perform source separation. We experiment with diffusion models trained on Slakh2100 and MTG-Jamendo, showcasing competitive generation and separation results in a relaxed data setting.
Multi-Source Diffusion Models for Simultaneous Music Generation and Separation
Feb 07, 2023



In this work, we define a diffusion-based generative model capable of both music synthesis and source separation by learning the score of the joint probability density of sources sharing a context. Alongside the classic total inference tasks (i.e. generating a mixture, separating the sources), we also introduce and experiment on the partial inference task of source imputation, where we generate a subset of the sources given the others (e.g., play a piano track that goes well with the drums). Additionally, we introduce a novel inference method for the separation task. We train our model on Slakh2100, a standard dataset for musical source separation, provide qualitative results in the generation settings, and showcase competitive quantitative results in the separation setting. Our method is the first example of a single model that can handle both generation and separation tasks, thus representing a step toward general audio models.
Latent Autoregressive Source Separation
Jan 09, 2023Autoregressive models have achieved impressive results over a wide range of domains in terms of generation quality and downstream task performance. In the continuous domain, a key factor behind this success is the usage of quantized latent spaces (e.g., obtained via VQ-VAE autoencoders), which allow for dimensionality reduction and faster inference times. However, using existing pre-trained models to perform new non-trivial tasks is difficult since it requires additional fine-tuning or extensive training to elicit prompting. This paper introduces LASS as a way to perform vector-quantized Latent Autoregressive Source Separation (i.e., de-mixing an input signal into its constituent sources) without requiring additional gradient-based optimization or modifications of existing models. Our separation method relies on the Bayesian formulation in which the autoregressive models are the priors, and a discrete (non-parametric) likelihood function is constructed by performing frequency counts over latent sums of addend tokens. We test our method on images and audio with several sampling strategies (e.g., ancestral, beam search) showing competitive results with existing approaches in terms of separation quality while offering at the same time significant speedups in terms of inference time and scalability to higher dimensional data.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Explanatory Learning: Beyond Empiricism in Neural Networks
Jan 25, 2022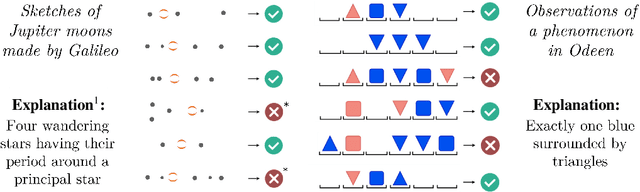
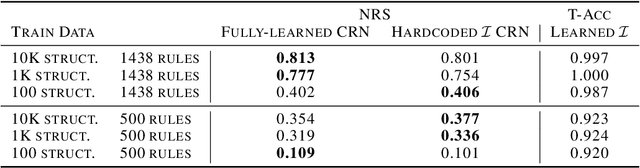
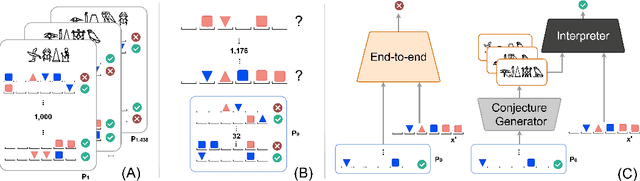
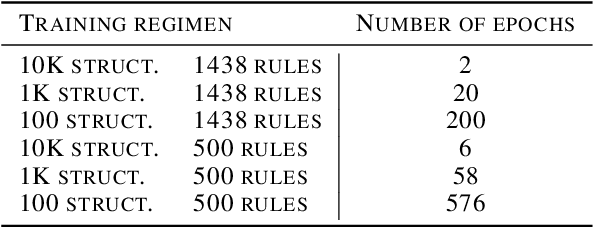
We introduce Explanatory Learning (EL), a framework to let machines use existing knowledge buried in symbolic sequences -- e.g. explanations written in hieroglyphic -- by autonomously learning to interpret them. In EL, the burden of interpreting symbols is not left to humans or rigid human-coded compilers, as done in Program Synthesis. Rather, EL calls for a learned interpreter, built upon a limited collection of symbolic sequences paired with observations of several phenomena. This interpreter can be used to make predictions on a novel phenomenon given its explanation, and even to find that explanation using only a handful of observations, like human scientists do. We formulate the EL problem as a simple binary classification task, so that common end-to-end approaches aligned with the dominant empiricist view of machine learning could, in principle, solve it. To these models, we oppose Critical Rationalist Networks (CRNs), which instead embrace a rationalist view on the acquisition of knowledge. CRNs express several desired properties by construction, they are truly explainable, can adjust their processing at test-time for harder inferences, and can offer strong confidence guarantees on their predictions. As a final contribution, we introduce Odeen, a basic EL environment that simulates a small flatland-style universe full of phenomena to explain. Using Odeen as a testbed, we show how CRNs outperform empiricist end-to-end approaches of similar size and architecture (Transformers) in discovering explanations for novel phenomena.