 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Predicting Ordinary Differential Equations with Transformers
Jul 24, 2023We develop a transformer-based sequence-to-sequence model that recovers scalar ordinary differential equations (ODEs) in symbolic form from irregularly sampled and noisy observations of a single solution trajectory. We demonstrate in extensive empirical evaluations that our model performs better or on par with existing methods in terms of accurate recovery across various settings. Moreover, our method is efficiently scalable: after one-time pretraining on a large set of ODEs, we can infer the governing law of a new observed solution in a few forward passes of the model.
Discovering ordinary differential equations that govern time-series
Nov 05, 2022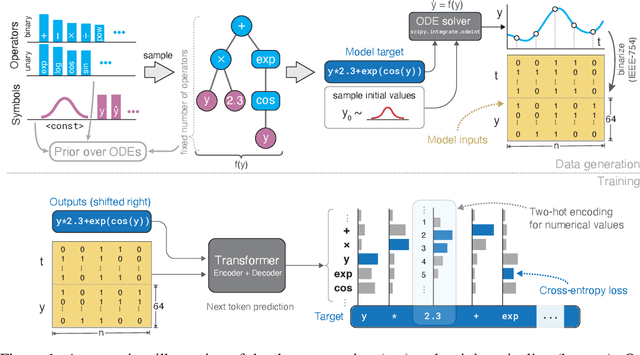
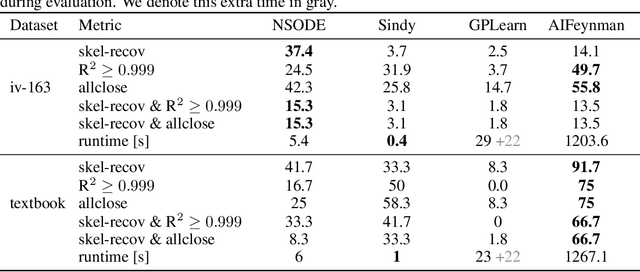
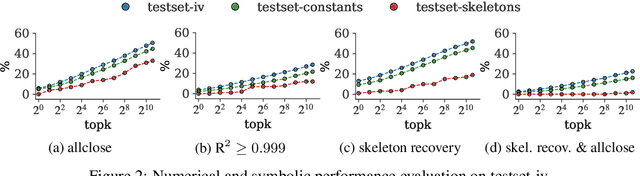
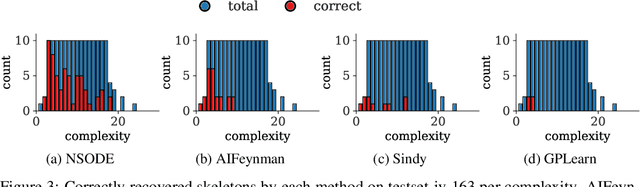
Natural laws are often described through differential equations yet finding a differential equation that describes the governing law underlying observed data is a challenging and still mostly manual task. In this paper we make a step towards the automation of this process: we propose a transformer-based sequence-to-sequence model that recovers scalar autonomous ordinary differential equations (ODEs) in symbolic form from time-series data of a single observed solution of the ODE. Our method is efficiently scalable: after one-time pretraining on a large set of ODEs, we can infer the governing laws of a new observed solution in a few forward passes of the model. Then we show that our model performs better or on par with existing methods in various test cases in terms of accurate symbolic recovery of the ODE, especially for more complex expressions.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Explanatory Learning: Beyond Empiricism in Neural Networks
Jan 25, 2022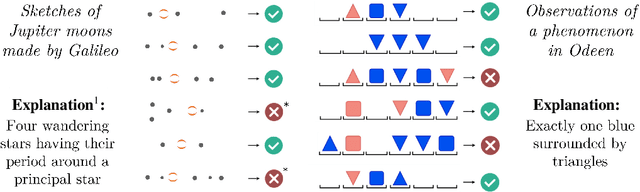
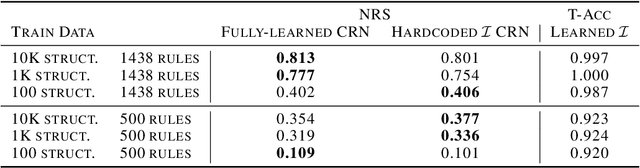
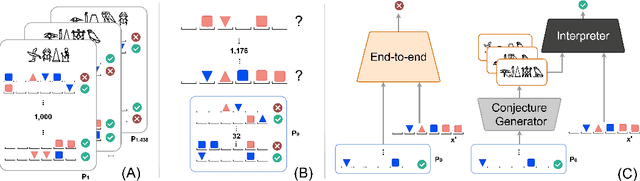
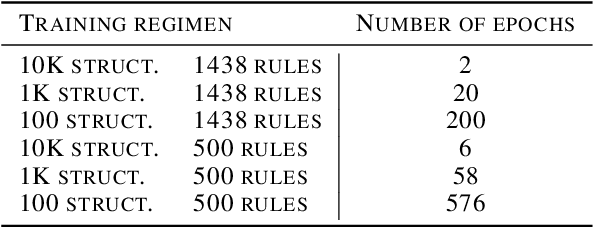
We introduce Explanatory Learning (EL), a framework to let machines use existing knowledge buried in symbolic sequences -- e.g. explanations written in hieroglyphic -- by autonomously learning to interpret them. In EL, the burden of interpreting symbols is not left to humans or rigid human-coded compilers, as done in Program Synthesis. Rather, EL calls for a learned interpreter, built upon a limited collection of symbolic sequences paired with observations of several phenomena. This interpreter can be used to make predictions on a novel phenomenon given its explanation, and even to find that explanation using only a handful of observations, like human scientists do. We formulate the EL problem as a simple binary classification task, so that common end-to-end approaches aligned with the dominant empiricist view of machine learning could, in principle, solve it. To these models, we oppose Critical Rationalist Networks (CRNs), which instead embrace a rationalist view on the acquisition of knowledge. CRNs express several desired properties by construction, they are truly explainable, can adjust their processing at test-time for harder inferences, and can offer strong confidence guarantees on their predictions. As a final contribution, we introduce Odeen, a basic EL environment that simulates a small flatland-style universe full of phenomena to explain. Using Odeen as a testbed, we show how CRNs outperform empiricist end-to-end approaches of similar size and architecture (Transformers) in discovering explanations for novel phenomena.
Neural Symbolic Regression that Scales
Jun 11, 2021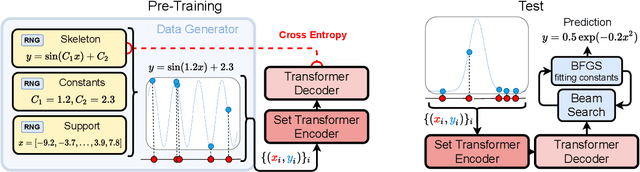
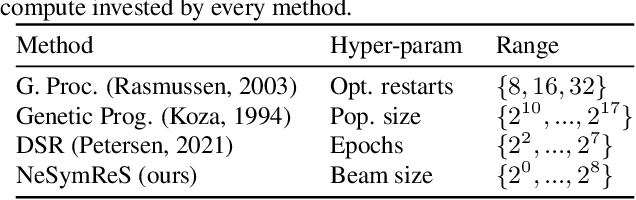
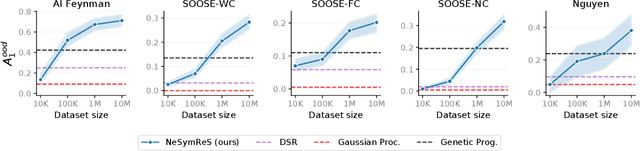
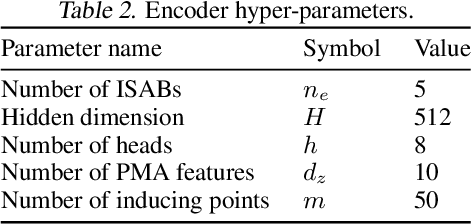
Symbolic equations are at the core of scientific discovery. The task of discovering the underlying equation from a set of input-output pairs is called symbolic regression. Traditionally, symbolic regression methods use hand-designed strategies that do not improve with experience. In this paper, we introduce the first symbolic regression method that leverages large scale pre-training. We procedurally generate an unbounded set of equations, and simultaneously pre-train a Transformer to predict the symbolic equation from a corresponding set of input-output-pairs. At test time, we query the model on a new set of points and use its output to guide the search for the equation. We show empirically that this approach can re-discover a set of well-known physical equations, and that it improves over time with more data and compute.
Learning explanations that are hard to vary
Sep 05, 2020



In this paper, we investigate the principle that `good explanations are hard to vary' in the context of deep learning. We show that averaging gradients across examples -- akin to a logical OR of patterns -- can favor memorization and `patchwork' solutions that sew together different strategies, instead of identifying invariances. To inspect this, we first formalize a notion of consistency for minima of the loss surface, which measures to what extent a minimum appears only when examples are pooled. We then propose and experimentally validate a simple alternative algorithm based on a logical AND, that focuses on invariances and prevents memorization in a set of real-world tasks. Finally, using a synthetic dataset with a clear distinction between invariant and spurious mechanisms, we dissect learning signals and compare this approach to well-established regularizers.
Divide-and-Conquer Monte Carlo Tree Search For Goal-Directed Planning
Apr 23, 2020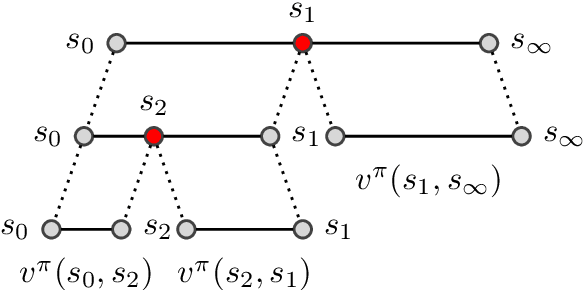


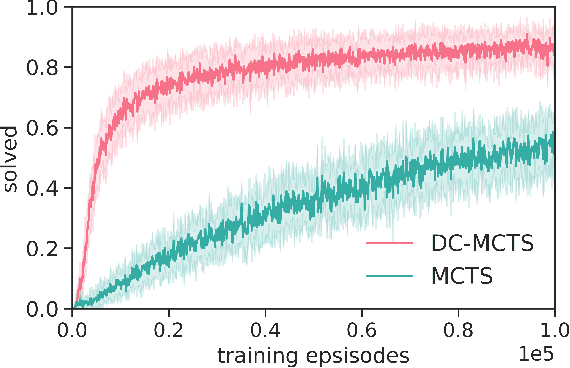
Standard planners for sequential decision making (including Monte Carlo planning, tree search, dynamic programming, etc.) are constrained by an implicit sequential planning assumption: The order in which a plan is constructed is the same in which it is executed. We consider alternatives to this assumption for the class of goal-directed Reinforcement Learning (RL) problems. Instead of an environment transition model, we assume an imperfect, goal-directed policy. This low-level policy can be improved by a plan, consisting of an appropriate sequence of sub-goals that guide it from the start to the goal state. We propose a planning algorithm, Divide-and-Conquer Monte Carlo Tree Search (DC-MCTS), for approximating the optimal plan by means of proposing intermediate sub-goals which hierarchically partition the initial tasks into simpler ones that are then solved independently and recursively. The algorithm critically makes use of a learned sub-goal proposal for finding appropriate partitions trees of new tasks based on prior experience. Different strategies for learning sub-goal proposals give rise to different planning strategies that strictly generalize sequential planning. We show that this algorithmic flexibility over planning order leads to improved results in navigation tasks in grid-worlds as well as in challenging continuous control environments.
Generalization in anti-causal learning
Dec 03, 2018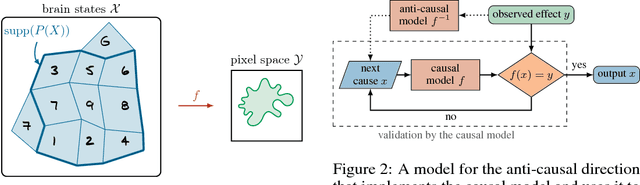
The ability to learn and act in novel situations is still a prerogative of animate intelligence, as current machine learning methods mostly fail when moving beyond the standard i.i.d. setting. What is the reason for this discrepancy? Most machine learning tasks are anti-causal, i.e., we infer causes (labels) from effects (observations). Typically, in supervised learning we build systems that try to directly invert causal mechanisms. Instead, in this paper we argue that strong generalization capabilities crucially hinge on searching and validating meaningful hypotheses, requiring access to a causal model. In such a framework, we want to find a cause that leads to the observed effect. Anti-causal models are used to drive this search, but a causal model is required for validation. We investigate the fundamental differences between causal and anti-causal tasks, discuss implications for topics ranging from adversarial attacks to disentangling factors of variation, and provide extensive evidence from the literature to substantiate our view. We advocate for incorporating causal models in supervised learning to shift the paradigm from inference only, to search and validation.