 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuleroDec: A Complex-Valued RVQ-VAE for Efficient and Robust Audio Coding
Jan 24, 2026Audio codecs power discrete music generative modelling, music streaming, and immersive media by shrinking PCM audio to bandwidth-friendly bitrates. Recent works have gravitated towards processing in the spectral domain; however, spectrogram domains typically struggle with phase modeling, which is naturally complex-valued. Most frequency-domain neural codecs either disregard phase information or encode it as two separate real-valued channels, limiting spatial fidelity. This entails the need to introduce adversarial discriminators at the expense of convergence speed and training stability to compensate for the inadequate representation power of the audio signal. In this work we introduce an end-to-end complex-valued RVQ-VAE audio codec that preserves magnitude-phase coupling across the entire analysis-quantization-synthesis pipeline and removes adversarial discriminators and diffusion post-filters. Without GANs or diffusion, we match or surpass much longer-trained baselines in-domain and reach SOTA out-of-domain performance on phase coherence and waveform fidelity. Compared to standard baselines that train for hundreds of thousands of steps, our model, which reduces the training budget by an order of magnitude, is markedly more compute-efficient while preserving high perceptual quality.
SteerMusic: Enhanced Musical Consistency for Zero-shot Text-Guided and Personalized Music Editing
Apr 15, 2025Music editing is an important step in music production, which has broad applications, including game development and film production. Most existing zero-shot text-guided methods rely on pretrained diffusion models by involving forward-backward diffusion processes for editing. However, these methods often struggle to maintain the music content consistency. Additionally, text instructions alone usually fail to accurately describe the desired music. In this paper, we propose two music editing methods that enhance the consistency between the original and edited music by leveraging score distillation. The first method, SteerMusic, is a coarse-grained zero-shot editing approach using delta denoising score. The second method, SteerMusic+, enables fine-grained personalized music editing by manipulating a concept token that represents a user-defined musical style. SteerMusic+ allows for the editing of music into any user-defined musical styles that cannot be achieved by the text instructions alone. Experimental results show that our methods outperform existing approaches in preserving both music content consistency and editing fidelity. User studies further validate that our methods achieve superior music editing quality. Audio examples are available on https://steermusic.pages.dev/.
STAGE: Stemmed Accompaniment Generation through Prefix-Based Conditioning
Apr 09, 2025Recent advances in generative models have made it possible to create high-quality, coherent music, with some systems delivering production-level output. Yet, most existing models focus solely on generating music from scratch, limiting their usefulness for musicians who want to integrate such models into a human, iterative composition workflow. In this paper we introduce STAGE, our STemmed Accompaniment GEneration model, fine-tuned from the state-of-the-art MusicGen to generate single-stem instrumental accompaniments conditioned on a given mixture. Inspired by instruction-tuning methods for language models, we extend the transformer's embedding matrix with a context token, enabling the model to attend to a musical context through prefix-based conditioning. Compared to the baselines, STAGE yields accompaniments that exhibit stronger coherence with the input mixture, higher audio quality, and closer alignment with textual prompts. Moreover, by conditioning on a metronome-like track, our framework naturally supports tempo-constrained generation, achieving state-of-the-art alignment with the target rhythmic structure--all without requiring any additional tempo-specific module. As a result, STAGE offers a practical, versatile tool for interactive music creation that can be readily adopted by musicians in real-world workflows.
High-Resolution Speech Restoration with Latent Diffusion Model
Sep 17, 2024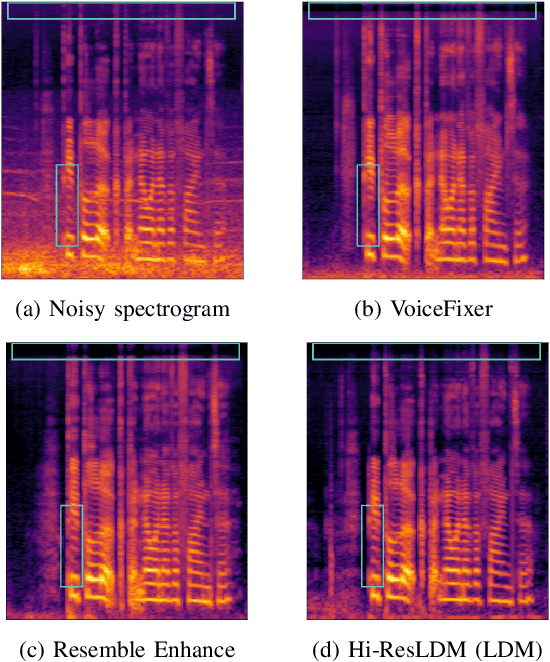
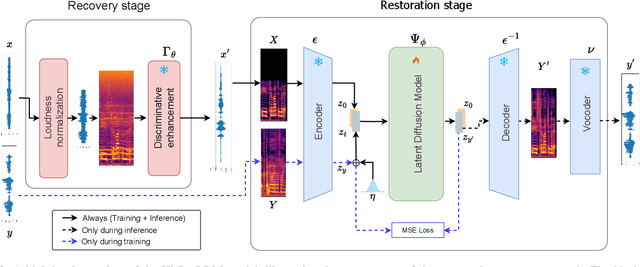
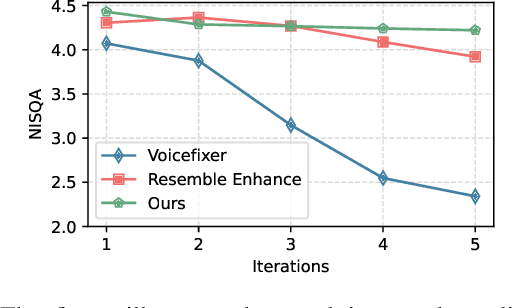
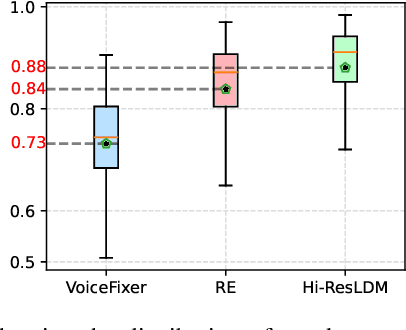
Traditional speech enhancement methods often oversimplify the task of restoration by focusing on a single type of distortion. Generative models that handle multiple distortions frequently struggle with phone reconstruction and high-frequency harmonics, leading to breathing and gasping artifacts that reduce the intelligibility of reconstructed speech. These models are also computationally demanding, and many solutions are restricted to producing outputs in the wide-band frequency range, which limits their suitability for professional applications. To address these challenges, we propose Hi-ResLDM, a novel generative model based on latent diffusion designed to remove multiple distortions and restore speech recordings to studio quality, sampled at 48kHz. We benchmark Hi-ResLDM against state-of-the-art methods that leverage GAN and Conditional Flow Matching (CFM) components, demonstrating superior performance in regenerating high-frequency-band details. Hi-ResLDM not only excels in non-instrusive metrics but is also consistently preferred in human evaluation and performs competitively on intrusive evaluations, making it ideal for high-resolution speech restoration.
Latent Diffusion Bridges for Unsupervised Musical Audio Timbre Transfer
Sep 09, 2024Music timbre transfer is a challenging task that involves modifying the timbral characteristics of an audio signal while preserving its melodic structure. In this paper, we propose a novel method based on dual diffusion bridges, trained using the CocoChorales Dataset, which consists of unpaired monophonic single-instrument audio data. Each diffusion model is trained on a specific instrument with a Gaussian prior. During inference, a model is designated as the source model to map the input audio to its corresponding Gaussian prior, and another model is designated as the target model to reconstruct the target audio from this Gaussian prior, thereby facilitating timbre transfer. We compare our approach against existing unsupervised timbre transfer models such as VAEGAN and Gaussian Flow Bridges (GFB). Experimental results demonstrate that our method achieves both better Fr\'echet Audio Distance (FAD) and melody preservation, as reflected by lower pitch distances (DPD) compared to VAEGAN and GFB. Additionally, we discover that the noise level from the Gaussian prior, $\sigma$, can be adjusted to control the degree of melody preservation and amount of timbre transferred.
COCOLA: Coherence-Oriented Contrastive Learning of Musical Audio Representations
Apr 29, 2024



We present COCOLA (Coherence-Oriented Contrastive Learning for Audio), a contrastive learning method for musical audio representations that captures the harmonic and rhythmic coherence between samples. Our method operates at the level of stems (or their combinations) composing music tracks and allows the objective evaluation of compositional models for music in the task of accompaniment generation. We also introduce a new baseline for compositional music generation called CompoNet, based on ControlNet, generalizing the tasks of MSDM, and quantify it against the latter using COCOLA. We release all models trained on public datasets containing separate stems (MUSDB18-HQ, MoisesDB, Slakh2100, and CocoChorales).
Accelerating Transformer Inference for Translation via Parallel Decoding
May 17, 2023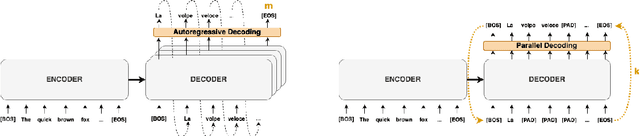
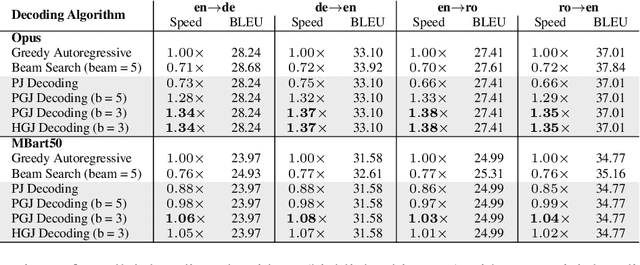

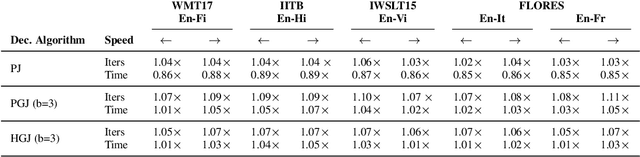
Autoregressive decoding limits the efficiency of transformers for Machine Translation (MT). The community proposed specific network architectures and learning-based methods to solve this issue, which are expensive and require changes to the MT model, trading inference speed at the cost of the translation quality. In this paper, we propose to address the problem from the point of view of decoding algorithms, as a less explored but rather compelling direction. We propose to reframe the standard greedy autoregressive decoding of MT with a parallel formulation leveraging Jacobi and Gauss-Seidel fixed-point iteration methods for fast inference. This formulation allows to speed up existing models without training or modifications while retaining translation quality. We present three parallel decoding algorithms and test them on different languages and models showing how the parallelization introduces a speedup up to 38% w.r.t. the standard autoregressive decoding and nearly 2x when scaling the method on parallel resources. Finally, we introduce a decoding dependency graph visualizer (DDGviz) that let us see how the model has learned the conditional dependence between tokens and inspect the decoding procedure.
Multi-Source Diffusion Models for Simultaneous Music Generation and Separation
Feb 07, 2023



In this work, we define a diffusion-based generative model capable of both music synthesis and source separation by learning the score of the joint probability density of sources sharing a context. Alongside the classic total inference tasks (i.e. generating a mixture, separating the sources), we also introduce and experiment on the partial inference task of source imputation, where we generate a subset of the sources given the others (e.g., play a piano track that goes well with the drums). Additionally, we introduce a novel inference method for the separation task. We train our model on Slakh2100, a standard dataset for musical source separation, provide qualitative results in the generation settings, and showcase competitive quantitative results in the separation setting. Our method is the first example of a single model that can handle both generation and separation tasks, thus representing a step toward general audio models.
Latent Autoregressive Source Separation
Jan 09, 2023Autoregressive models have achieved impressive results over a wide range of domains in terms of generation quality and downstream task performance. In the continuous domain, a key factor behind this success is the usage of quantized latent spaces (e.g., obtained via VQ-VAE autoencoders), which allow for dimensionality reduction and faster inference times. However, using existing pre-trained models to perform new non-trivial tasks is difficult since it requires additional fine-tuning or extensive training to elicit prompting. This paper introduces LASS as a way to perform vector-quantized Latent Autoregressive Source Separation (i.e., de-mixing an input signal into its constituent sources) without requiring additional gradient-based optimization or modifications of existing models. Our separation method relies on the Bayesian formulation in which the autoregressive models are the priors, and a discrete (non-parametric) likelihood function is constructed by performing frequency counts over latent sums of addend tokens. We test our method on images and audio with several sampling strategies (e.g., ancestral, beam search) showing competitive results with existing approaches in terms of separation quality while offering at the same time significant speedups in terms of inference time and scalability to higher dimensional data.
Fish sounds: towards the evaluation of marine acoustic biodiversity through data-driven audio source separation
Jan 14, 2022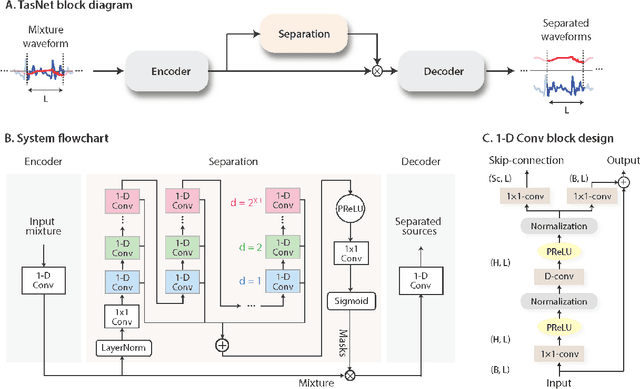
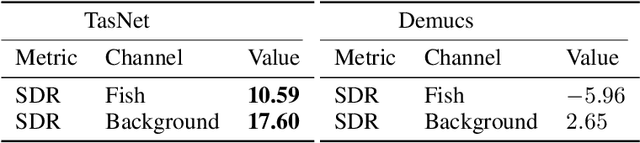
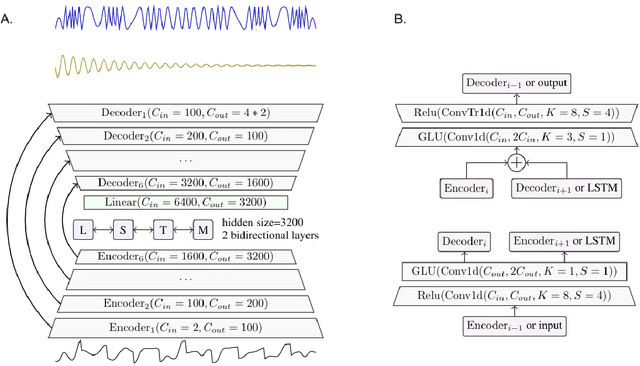
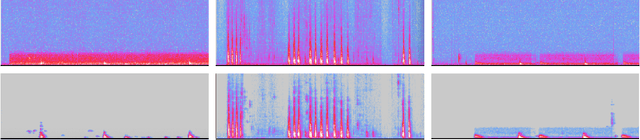
The marine ecosystem is changing at an alarming rate, exhibiting biodiversity loss and the migration of tropical species to temperate basins. Monitoring the underwater environments and their inhabitants is of fundamental importance to understand the evolution of these systems and implement safeguard policies. However, assessing and tracking biodiversity is often a complex task, especially in large and uncontrolled environments, such as the oceans. One of the most popular and effective methods for monitoring marine biodiversity is passive acoustics monitoring (PAM), which employs hydrophones to capture underwater sound. Many aquatic animals produce sounds characteristic of their own species; these signals travel efficiently underwater and can be detected even at great distances. Furthermore, modern technologies are becoming more and more convenient and precise, allowing for very accurate and careful data acquisition. To date, audio captured with PAM devices is frequently manually processed by marine biologists and interpreted with traditional signal processing techniques for the detection of animal vocalizations. This is a challenging task, as PAM recordings are often over long periods of time. Moreover, one of the causes of biodiversity loss is sound pollution; in data obtained from regions with loud anthropic noise, it is hard to separate the artificial from the fish sound manually. Nowadays, machine learning and, in particular, deep learning represents the state of the art for processing audio signals. Specifically, sound separation networks are able to identify and separate human voices and musical instruments. In this work, we show that the same techniques can be successfully used to automatically extract fish vocalizations in PAM recordings, opening up the possibility for biodiversity monitoring at a large scale.