 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Transformer Inference for Translation via Parallel Decoding
May 17, 2023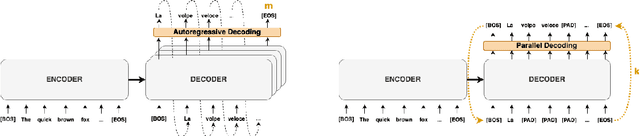
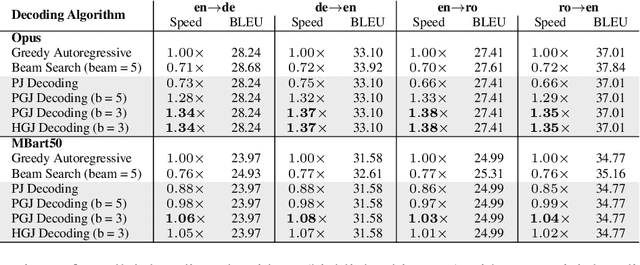

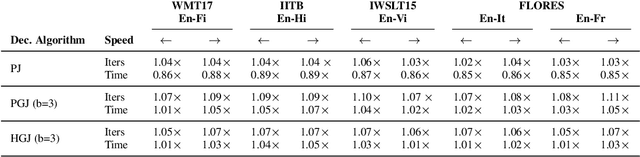
Autoregressive decoding limits the efficiency of transformers for Machine Translation (MT). The community proposed specific network architectures and learning-based methods to solve this issue, which are expensive and require changes to the MT model, trading inference speed at the cost of the translation quality. In this paper, we propose to address the problem from the point of view of decoding algorithms, as a less explored but rather compelling direction. We propose to reframe the standard greedy autoregressive decoding of MT with a parallel formulation leveraging Jacobi and Gauss-Seidel fixed-point iteration methods for fast inference. This formulation allows to speed up existing models without training or modifications while retaining translation quality. We present three parallel decoding algorithms and test them on different languages and models showing how the parallelization introduces a speedup up to 38% w.r.t. the standard autoregressive decoding and nearly 2x when scaling the method on parallel resources. Finally, we introduce a decoding dependency graph visualizer (DDGviz) that let us see how the model has learned the conditional dependence between tokens and inspect the decoding procedure.
Sparse Vicious Attacks on Graph Neural Networks
Sep 20, 2022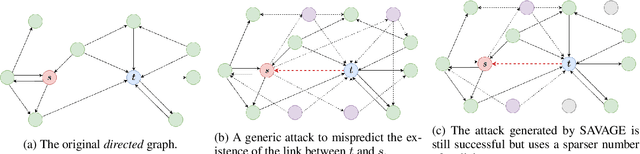
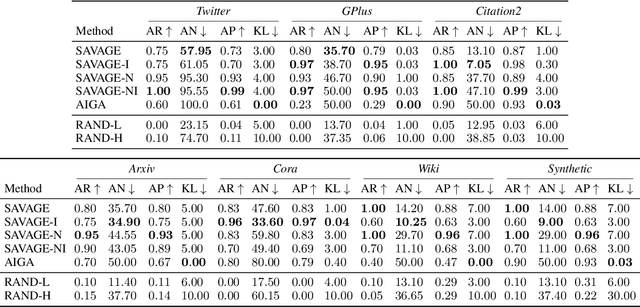

Graph Neural Networks (GNNs) have proven to be successful in several predictive modeling tasks for graph-structured data. Amongst those tasks, link prediction is one of the fundamental problems for many real-world applications, such as recommender systems. However, GNNs are not immune to adversarial attacks, i.e., carefully crafted malicious examples that are designed to fool the predictive model. In this work, we focus on a specific, white-box attack to GNN-based link prediction models, where a malicious node aims to appear in the list of recommended nodes for a given target victim. To achieve this goal, the attacker node may also count on the cooperation of other existing peers that it directly controls, namely on the ability to inject a number of ``vicious'' nodes in the network. Specifically, all these malicious nodes can add new edges or remove existing ones, thereby perturbing the original graph. Thus, we propose SAVAGE, a novel framework and a method to mount this type of link prediction attacks. SAVAGE formulates the adversary's goal as an optimization task, striking the balance between the effectiveness of the attack and the sparsity of malicious resources required. Extensive experiments conducted on real-world and synthetic datasets demonstrate that adversarial attacks implemented through SAVAGE indeed achieve high attack success rate yet using a small amount of vicious nodes. Finally, despite those attacks require full knowledge of the target model, we show that they are successfully transferable to other black-box methods for link prediction.