 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Label Resynthesized Audio: The Dual Role of Neural Audio Codecs in Audio Deepfake Detection
Feb 18, 2026Since Text-to-Speech systems typically don't produce waveforms directly, recent spoof detection studies use resynthesized waveforms from vocoders and neural audio codecs to simulate an attacker. Unlike vocoders, which are specifically designed for speech synthesis, neural audio codecs were originally developed for compressing audio for storage and transmission. However, their ability to discretize speech also sparked interest in language-modeling-based speech synthesis. Owing to this dual functionality, codec resynthesized data may be labeled as either bonafide or spoof. So far, very little research has addressed this issue. In this study, we present a challenging extension of the ASVspoof 5 dataset constructed for this purpose. We examine how different labeling choices affect detection performance and provide insights into labeling strategies.
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025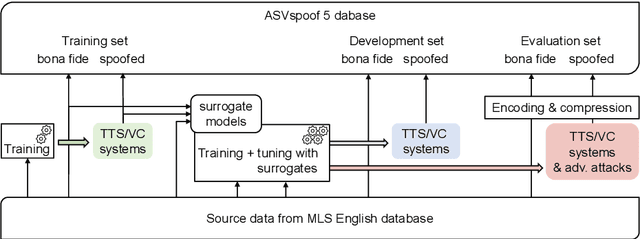

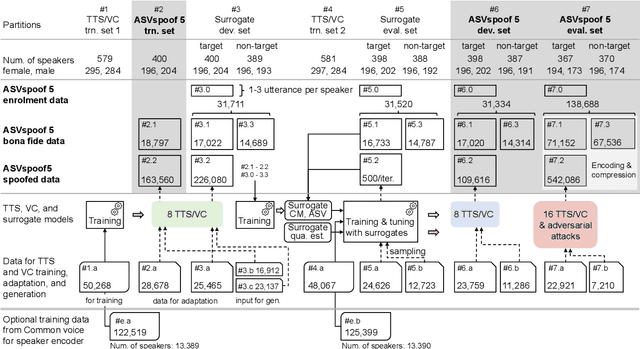
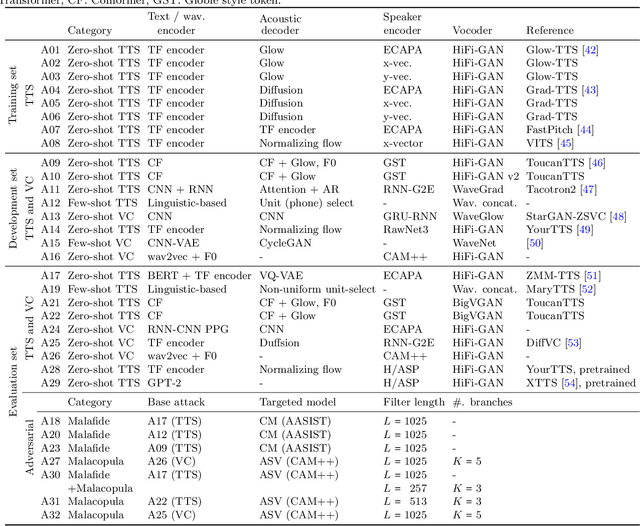
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
High-Resolution Speech Restoration with Latent Diffusion Model
Sep 17, 2024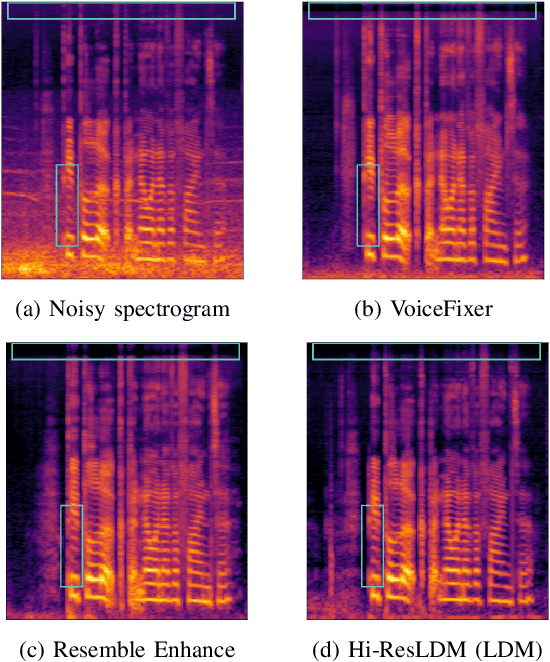
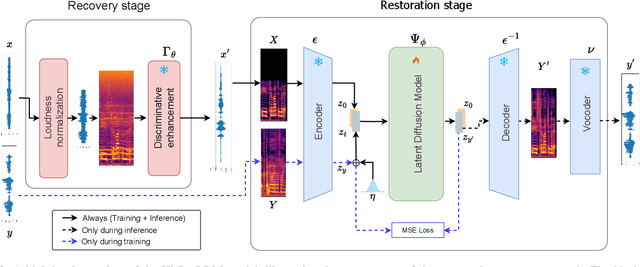
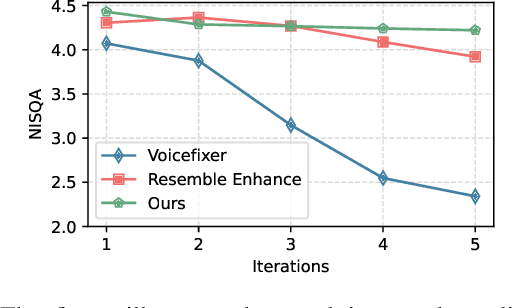
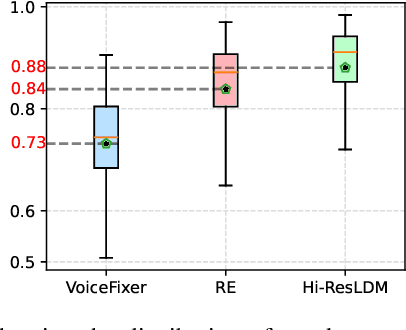
Traditional speech enhancement methods often oversimplify the task of restoration by focusing on a single type of distortion. Generative models that handle multiple distortions frequently struggle with phone reconstruction and high-frequency harmonics, leading to breathing and gasping artifacts that reduce the intelligibility of reconstructed speech. These models are also computationally demanding, and many solutions are restricted to producing outputs in the wide-band frequency range, which limits their suitability for professional applications. To address these challenges, we propose Hi-ResLDM, a novel generative model based on latent diffusion designed to remove multiple distortions and restore speech recordings to studio quality, sampled at 48kHz. We benchmark Hi-ResLDM against state-of-the-art methods that leverage GAN and Conditional Flow Matching (CFM) components, demonstrating superior performance in regenerating high-frequency-band details. Hi-ResLDM not only excels in non-instrusive metrics but is also consistently preferred in human evaluation and performs competitively on intrusive evaluations, making it ideal for high-resolution speech restoration.
Probing the Feasibility of Multilingual Speaker Anonymization
Jul 03, 2024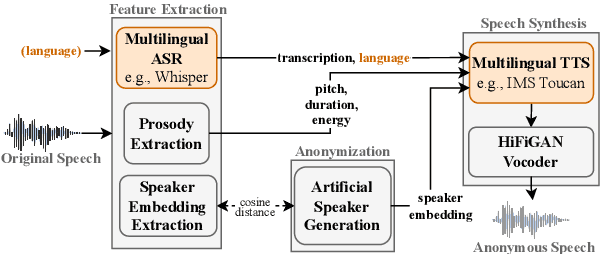
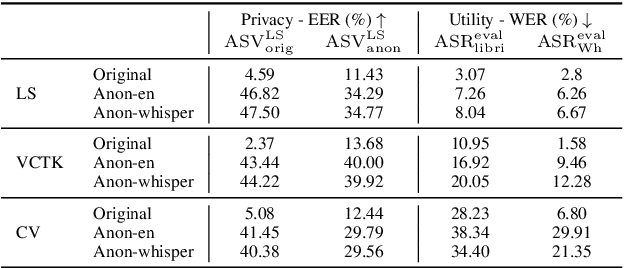
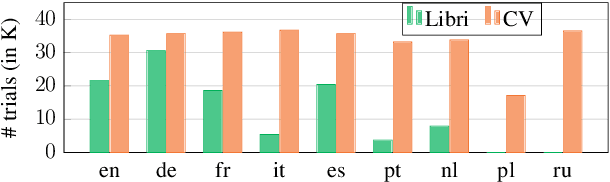
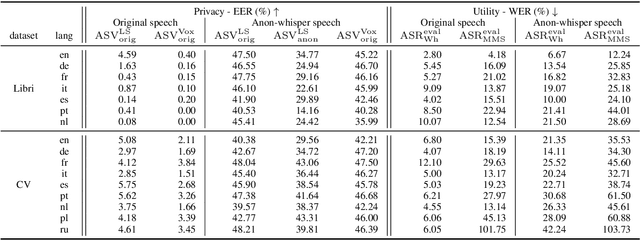
In speaker anonymization, speech recordings are modified in a way that the identity of the speaker remains hidden. While this technology could help to protect the privacy of individuals around the globe, current research restricts this by focusing almost exclusively on English data. In this study, we extend a state-of-the-art anonymization system to nine languages by transforming language-dependent components to their multilingual counterparts. Experiments testing the robustness of the anonymized speech against privacy attacks and speech deterioration show an overall success of this system for all languages. The results suggest that speaker embeddings trained on English data can be applied across languages, and that the anonymization performance for a language is mainly affected by the quality of the speech synthesis component used for it.
Controlling Emotion in Text-to-Speech with Natural Language Prompts
Jun 11, 2024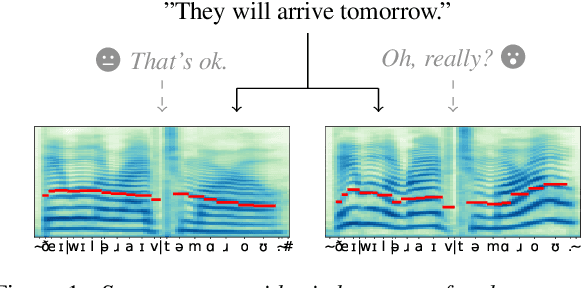

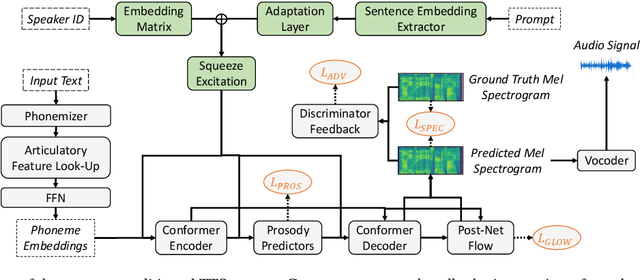
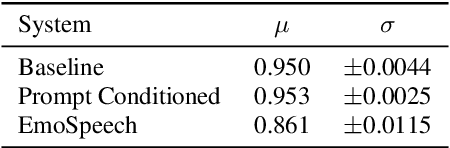
In recent years, prompting has quickly become one of the standard ways of steering the outputs of generative machine learning models, due to its intuitive use of natural language. In this work, we propose a system conditioned on embeddings derived from an emotionally rich text that serves as prompt. Thereby, a joint representation of speaker and prompt embeddings is integrated at several points within a transformer-based architecture. Our approach is trained on merged emotional speech and text datasets and varies prompts in each training iteration to increase the generalization capabilities of the model. Objective and subjective evaluation results demonstrate the ability of the conditioned synthesis system to accurately transfer the emotions present in a prompt to speech. At the same time, precise tractability of speaker identities as well as overall high speech quality and intelligibility are maintained.
Meta Learning Text-to-Speech Synthesis in over 7000 Languages
Jun 10, 2024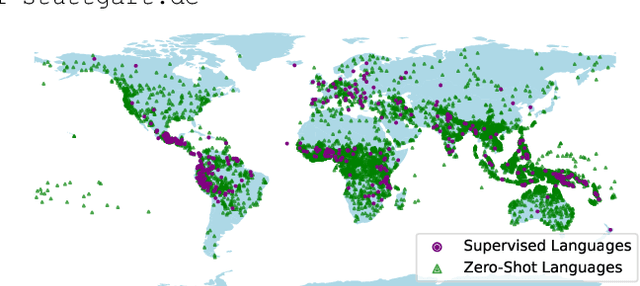
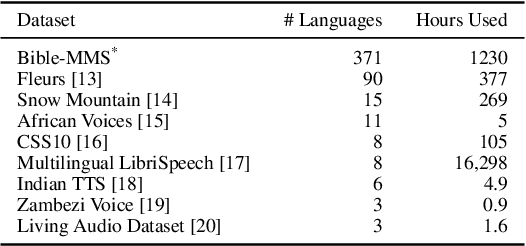
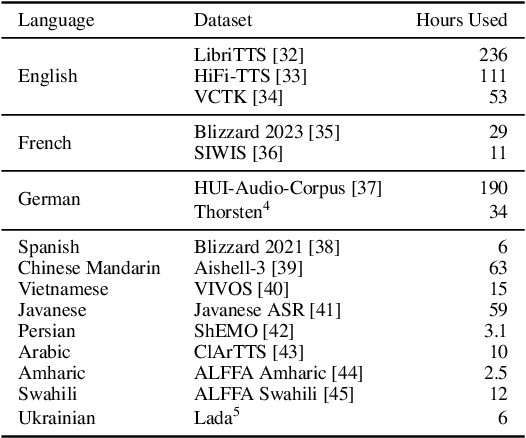
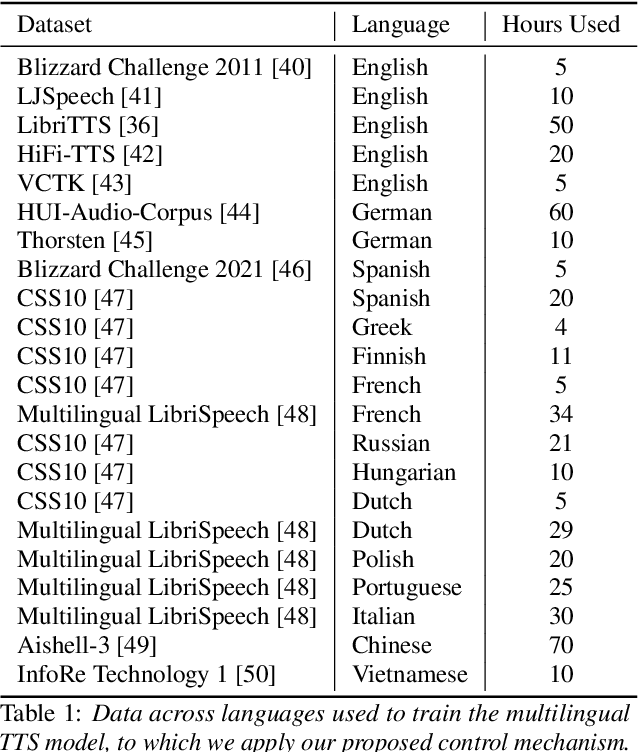
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
Controllable Generation of Artificial Speaker Embeddings through Discovery of Principal Directions
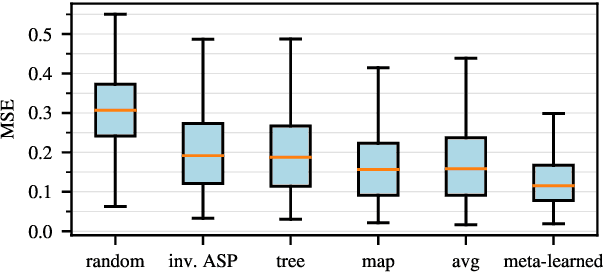
Oct 26, 2023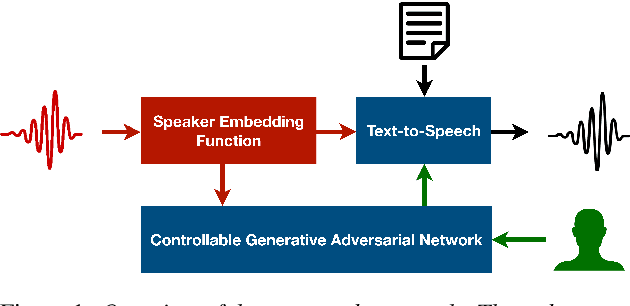
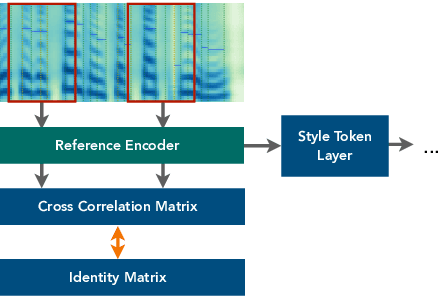

Customizing voice and speaking style in a speech synthesis system with intuitive and fine-grained controls is challenging, given that little data with appropriate labels is available. Furthermore, editing an existing human's voice also comes with ethical concerns. In this paper, we propose a method to generate artificial speaker embeddings that cannot be linked to a real human while offering intuitive and fine-grained control over the voice and speaking style of the embeddings, without requiring any labels for speaker or style. The artificial and controllable embeddings can be fed to a speech synthesis system, conditioned on embeddings of real humans during training, without sacrificing privacy during inference.
The IMS Toucan System for the Blizzard Challenge 2023
Oct 26, 2023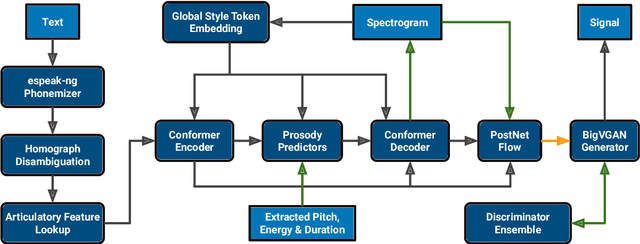
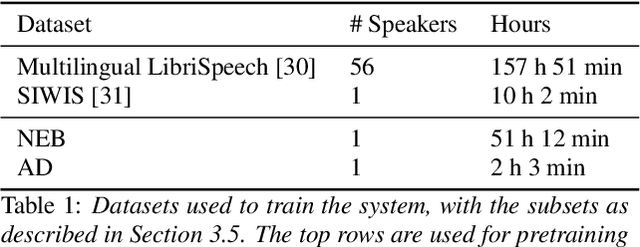
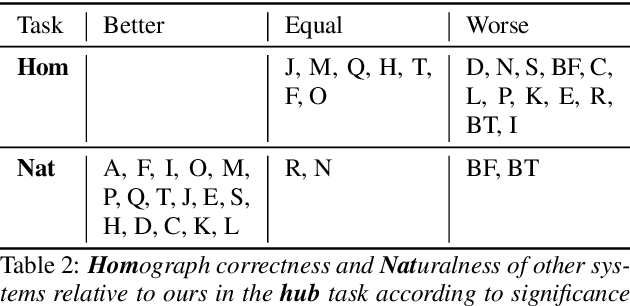
For our contribution to the Blizzard Challenge 2023, we improved on the system we submitted to the Blizzard Challenge 2021. Our approach entails a rule-based text-to-phoneme processing system that includes rule-based disambiguation of homographs in the French language. It then transforms the phonemes to spectrograms as intermediate representations using a fast and efficient non-autoregressive synthesis architecture based on Conformer and Glow. A GAN based neural vocoder that combines recent state-of-the-art approaches converts the spectrogram to the final wave. We carefully designed the data processing, training, and inference procedures for the challenge data. Our system identifier is G. Open source code and demo are available.
Anonymizing Speech with Generative Adversarial Networks to Preserve Speaker Privacy
Oct 20, 2022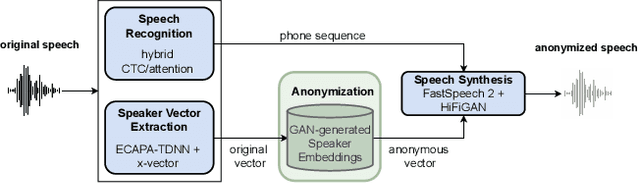
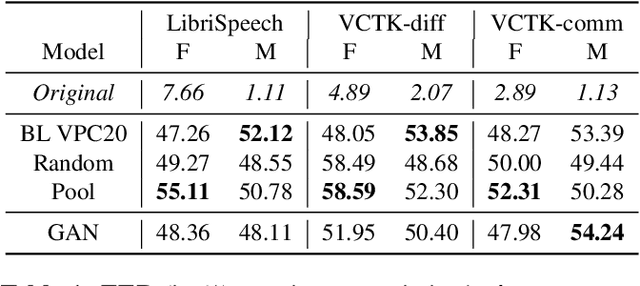
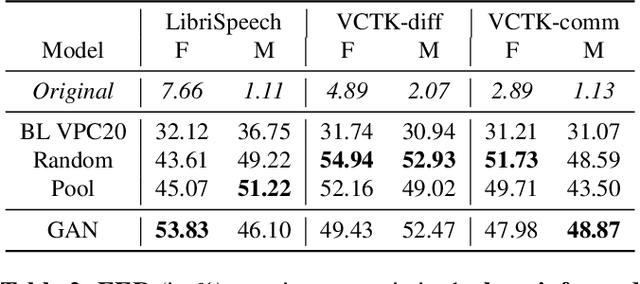
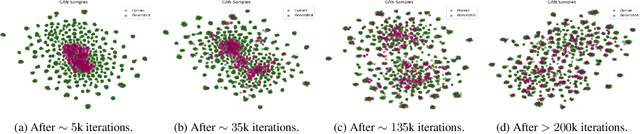
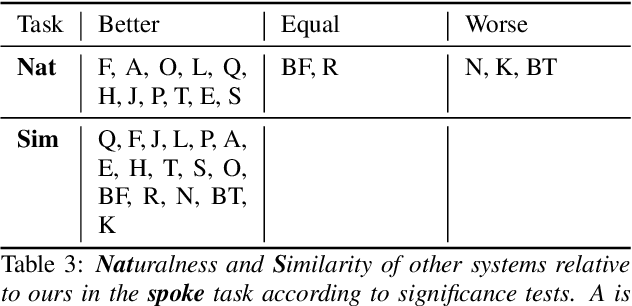
In order to protect the privacy of speech data, speaker anonymization aims for hiding the identity of a speaker by changing the voice in speech recordings. This typically comes with a privacy-utility trade-off between protection of individuals and usability of the data for downstream applications. One of the challenges in this context is to create non-existent voices that sound as natural as possible. In this work, we propose to tackle this issue by generating speaker embeddings using a generative adversarial network with Wasserstein distance as cost function. By incorporating these artificial embeddings into a speech-to-text-to-speech pipeline, we outperform previous approaches in terms of privacy and utility. According to standard objective metrics and human evaluation, our approach generates intelligible and content-preserving yet privacy-protecting versions of the original recordings.
PoeticTTS -- Controllable Poetry Reading for Literary Studies
Jul 11, 2022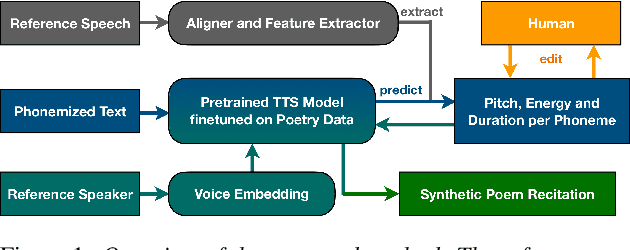
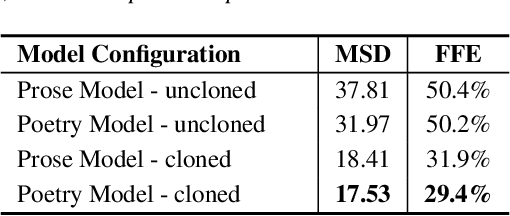
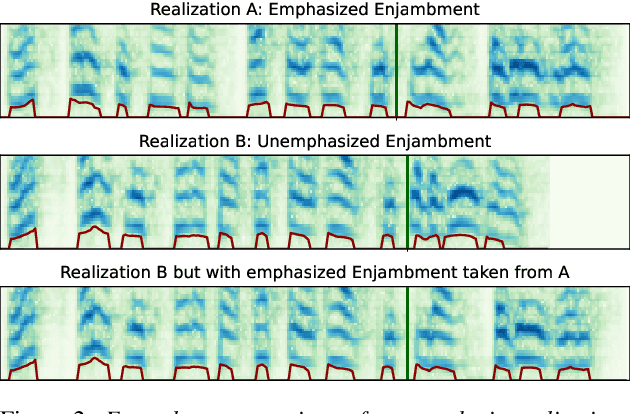
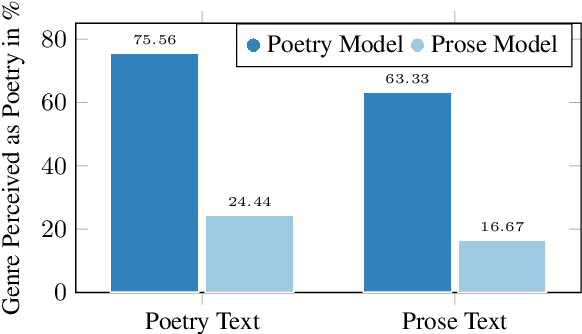
Speech synthesis for poetry is challenging due to specific intonation patterns inherent to poetic speech. In this work, we propose an approach to synthesise poems with almost human like naturalness in order to enable literary scholars to systematically examine hypotheses on the interplay between text, spoken realisation, and the listener's perception of poems. To meet these special requirements for literary studies, we resynthesise poems by cloning prosodic values from a human reference recitation, and afterwards make use of fine-grained prosody control to manipulate the synthetic speech in a human-in-the-loop setting to alter the recitation w.r.t. specific phenomena. We find that finetuning our TTS model on poetry captures poetic intonation patterns to a large extent which is beneficial for prosody cloning and manipulation and verify the success of our approach both in an objective evaluation as well as in human studies.