 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Emotion in Text-to-Speech with Natural Language Prompts
Paper and Code
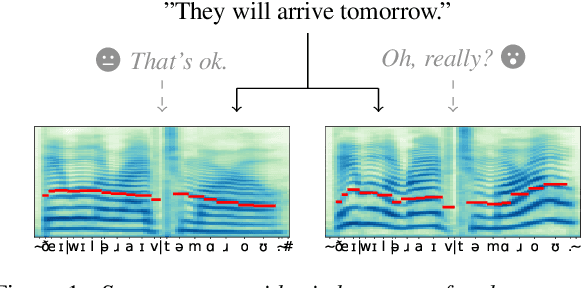

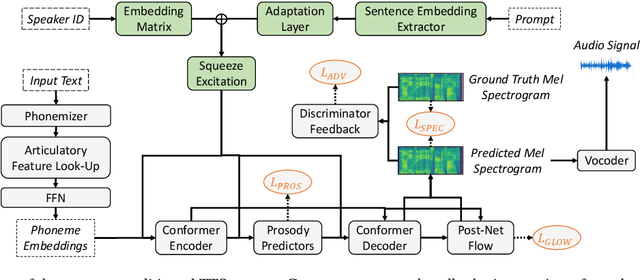
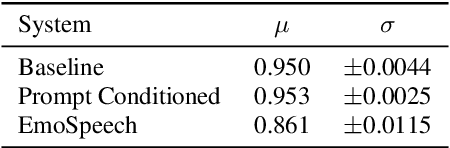
In recent years, prompting has quickly become one of the standard ways of steering the outputs of generative machine learning models, due to its intuitive use of natural language. In this work, we propose a system conditioned on embeddings derived from an emotionally rich text that serves as prompt. Thereby, a joint representation of speaker and prompt embeddings is integrated at several points within a transformer-based architecture. Our approach is trained on merged emotional speech and text datasets and varies prompts in each training iteration to increase the generalization capabilities of the model. Objective and subjective evaluation results demonstrate the ability of the conditioned synthesis system to accurately transfer the emotions present in a prompt to speech. At the same time, precise tractability of speaker identities as well as overall high speech quality and intelligibility are maintained.