 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Emotion in Text-to-Speech with Natural Language Prompts
Jun 11, 2024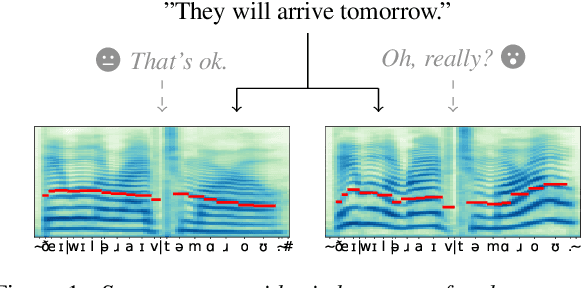

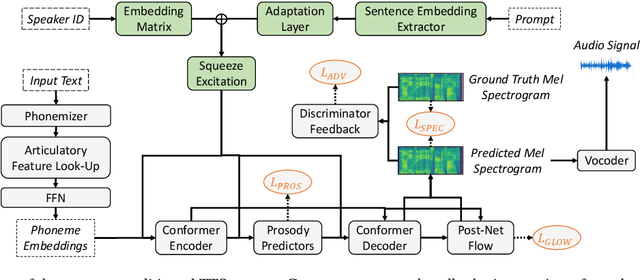
In recent years, prompting has quickly become one of the standard ways of steering the outputs of generative machine learning models, due to its intuitive use of natural language. In this work, we propose a system conditioned on embeddings derived from an emotionally rich text that serves as prompt. Thereby, a joint representation of speaker and prompt embeddings is integrated at several points within a transformer-based architecture. Our approach is trained on merged emotional speech and text datasets and varies prompts in each training iteration to increase the generalization capabilities of the model. Objective and subjective evaluation results demonstrate the ability of the conditioned synthesis system to accurately transfer the emotions present in a prompt to speech. At the same time, precise tractability of speaker identities as well as overall high speech quality and intelligibility are maintained.
The IMS Toucan System for the Blizzard Challenge 2023
Oct 26, 2023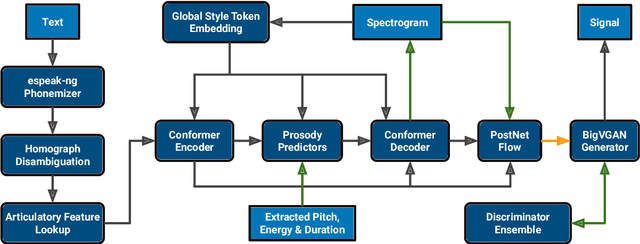
For our contribution to the Blizzard Challenge 2023, we improved on the system we submitted to the Blizzard Challenge 2021. Our approach entails a rule-based text-to-phoneme processing system that includes rule-based disambiguation of homographs in the French language. It then transforms the phonemes to spectrograms as intermediate representations using a fast and efficient non-autoregressive synthesis architecture based on Conformer and Glow. A GAN based neural vocoder that combines recent state-of-the-art approaches converts the spectrogram to the final wave. We carefully designed the data processing, training, and inference procedures for the challenge data. Our system identifier is G. Open source code and demo are available.
More than just Frequency? Demasking Unsupervised Hypernymy Prediction Methods
May 31, 2021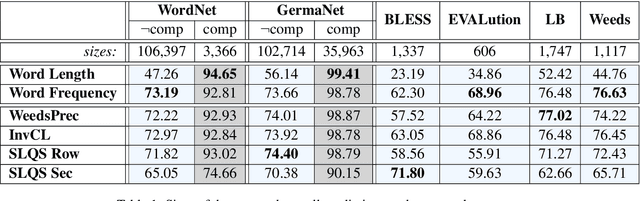


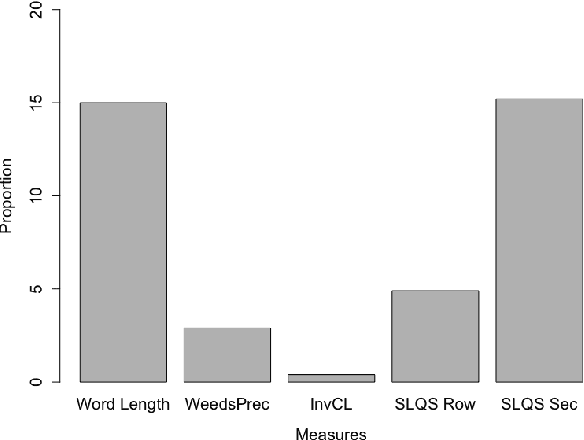
This paper presents a comparison of unsupervised methods of hypernymy prediction (i.e., to predict which word in a pair of words such as fish-cod is the hypernym and which the hyponym). Most importantly, we demonstrate across datasets for English and for German that the predictions of three methods (WeedsPrec, invCL, SLQS Row) strongly overlap and are highly correlated with frequency-based predictions. In contrast, the second-order method SLQS shows an overall lower accuracy but makes correct predictions where the others go wrong. Our study once more confirms the general need to check the frequency bias of a computational method in order to identify frequency-(un)related effects.