Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than just Frequency? Demasking Unsupervised Hypernymy Prediction Methods
Paper and Code
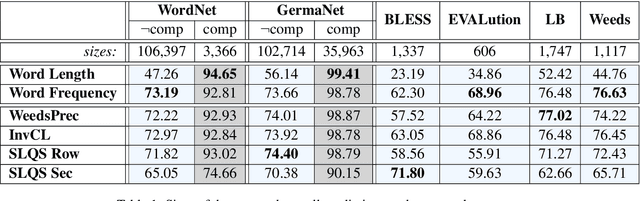


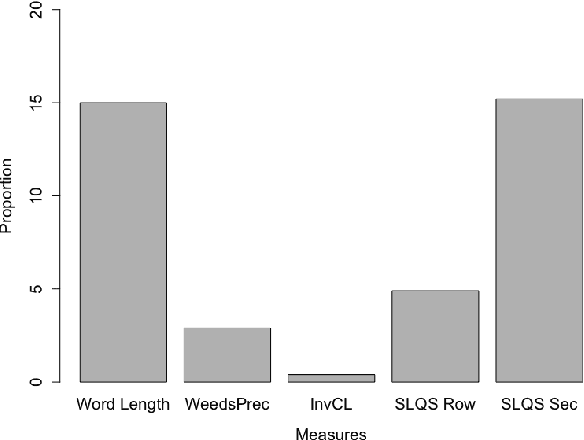
This paper presents a comparison of unsupervised methods of hypernymy prediction (i.e., to predict which word in a pair of words such as fish-cod is the hypernym and which the hyponym). Most importantly, we demonstrate across datasets for English and for German that the predictions of three methods (WeedsPrec, invCL, SLQS Row) strongly overlap and are highly correlated with frequency-based predictions. In contrast, the second-order method SLQS shows an overall lower accuracy but makes correct predictions where the others go wrong. Our study once more confirms the general need to check the frequency bias of a computational method in order to identify frequency-(un)related effects.
* ACL Findings, 5 pages
View paper on