 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Text-to-Speech Synthesis Using Noise-Augmented Training of ForwardTacotron
Jan 10, 2025

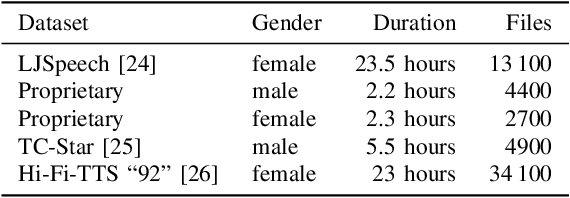
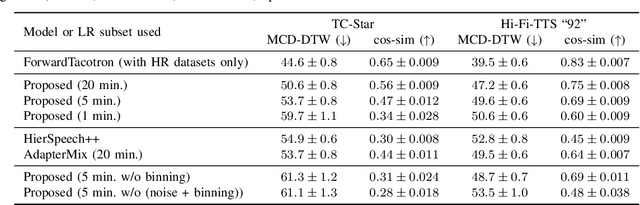
In recent years, several text-to-speech systems have been proposed to synthesize natural speech in zero-shot, few-shot, and low-resource scenarios. However, these methods typically require training with data from many different speakers. The speech quality across the speaker set typically is diverse and imposes an upper limit on the quality achievable for the low-resource speaker. In the current work, we achieve high-quality speech synthesis using as little as five minutes of speech from the desired speaker by augmenting the low-resource speaker data with noise and employing multiple sampling techniques during training. Our method requires only four high-quality, high-resource speakers, which are easy to obtain and use in practice. Our low-complexity method achieves improved speaker similarity compared to the state-of-the-art zero-shot method HierSpeech++ and the recent low-resource method AdapterMix while maintaining comparable naturalness. Our proposed approach can also reduce the data requirements for speech synthesis for new speakers and languages.
Meta Learning Text-to-Speech Synthesis in over 7000 Languages
Jun 10, 2024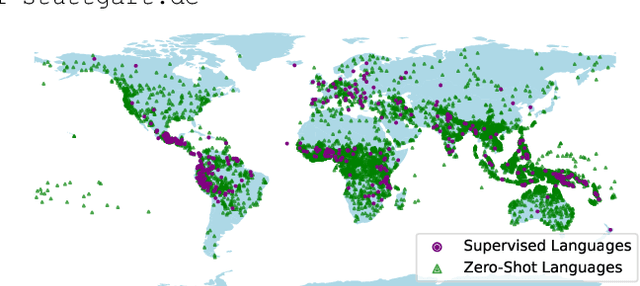
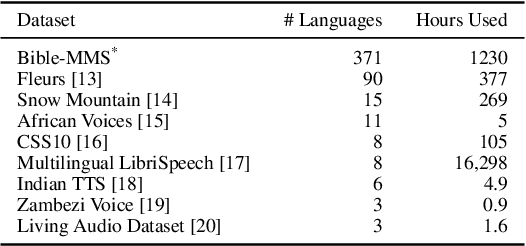
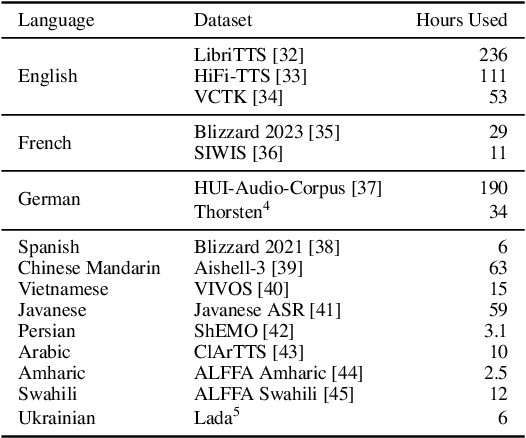
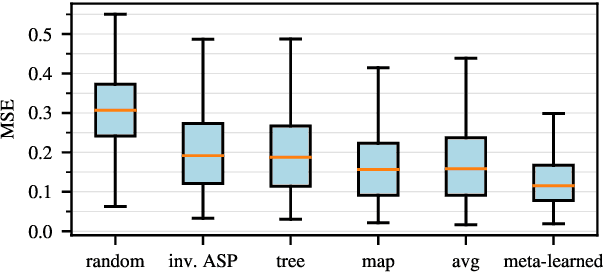
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
Theme Transformer: Symbolic Music Generation with Theme-Conditioned Transformer
Nov 07, 2021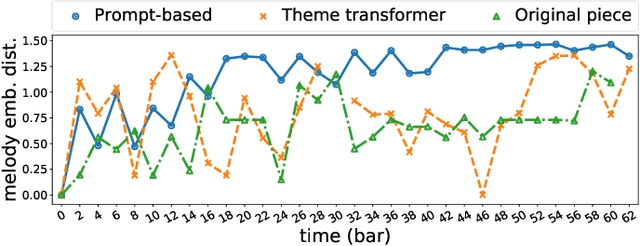
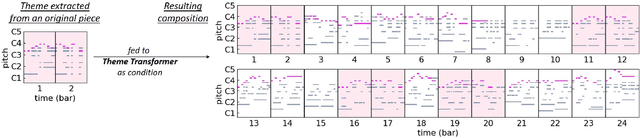
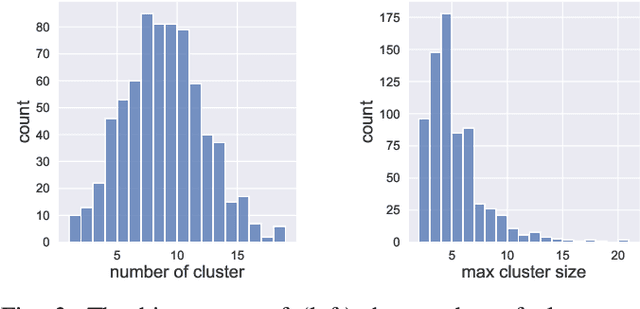
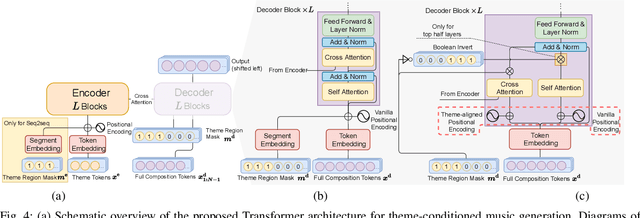
Attention-based Transformer models have been increasingly employed for automatic music generation. To condition the generation process of such a model with a user-specified sequence, a popular approach is to take that conditioning sequence as a priming sequence and ask a Transformer decoder to generate a continuation. However, this prompt-based conditioning cannot guarantee that the conditioning sequence would develop or even simply repeat itself in the generated continuation. In this paper, we propose an alternative conditioning approach, called theme-based conditioning, that explicitly trains the Transformer to treat the conditioning sequence as a thematic material that has to manifest itself multiple times in its generation result. This is achieved with two main technical contributions. First, we propose a deep learning-based approach that uses contrastive representation learning and clustering to automatically retrieve thematic materials from music pieces in the training data. Second, we propose a novel gated parallel attention module to be used in a sequence-to-sequence (seq2seq) encoder/decoder architecture to more effectively account for a given conditioning thematic material in the generation process of the Transformer decoder. We report on objective and subjective evaluations of variants of the proposed Theme Transformer and the conventional prompt-based baseline, showing that our best model can generate, to some extent, polyphonic pop piano music with repetition and plausible variations of a given condition.