 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Strategies for Modality Dropout Resilient Multi-Modal Target Speaker Extraction
Jul 09, 2025The primary goal of multi-modal TSE (MTSE) is to extract a target speaker from a speech mixture using complementary information from different modalities, such as audio enrolment and visual feeds corresponding to the target speaker. MTSE systems are expected to perform well even when one of the modalities is unavailable. In practice, the systems often suffer from modality dominance, where one of the modalities outweighs the others, thereby limiting robustness. Our study investigates training strategies and the effect of architectural choices, particularly the normalization layers, in yielding a robust MTSE system in both non-causal and causal configurations. In particular, we propose the use of modality dropout training (MDT) as a superior strategy to standard and multi-task training (MTT) strategies. Experiments conducted on two-speaker mixtures from the LRS3 dataset show the MDT strategy to be effective irrespective of the employed normalization layer. In contrast, the models trained with the standard and MTT strategies are susceptible to modality dominance, and their performance depends on the chosen normalization layer. Additionally, we demonstrate that the system trained with MDT strategy is robust to using extracted speech as the enrollment signal, highlighting its potential applicability in scenarios where the target speaker is not enrolled.
Low-Resource Text-to-Speech Synthesis Using Noise-Augmented Training of ForwardTacotron
Jan 10, 2025

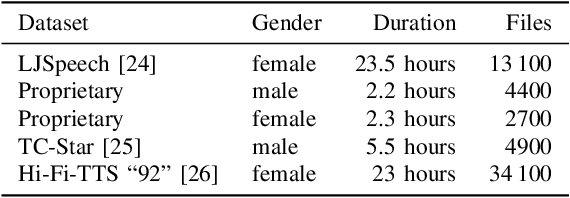
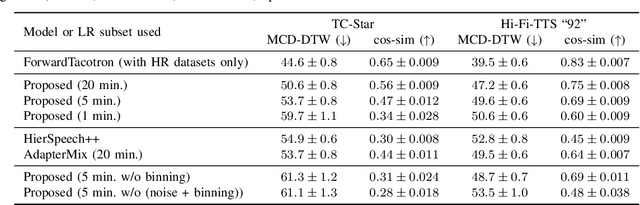
In recent years, several text-to-speech systems have been proposed to synthesize natural speech in zero-shot, few-shot, and low-resource scenarios. However, these methods typically require training with data from many different speakers. The speech quality across the speaker set typically is diverse and imposes an upper limit on the quality achievable for the low-resource speaker. In the current work, we achieve high-quality speech synthesis using as little as five minutes of speech from the desired speaker by augmenting the low-resource speaker data with noise and employing multiple sampling techniques during training. Our method requires only four high-quality, high-resource speakers, which are easy to obtain and use in practice. Our low-complexity method achieves improved speaker similarity compared to the state-of-the-art zero-shot method HierSpeech++ and the recent low-resource method AdapterMix while maintaining comparable naturalness. Our proposed approach can also reduce the data requirements for speech synthesis for new speakers and languages.
ODAQ: Open Dataset of Audio Quality
Dec 30, 2023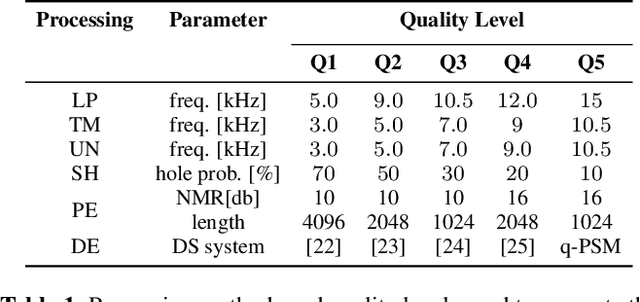
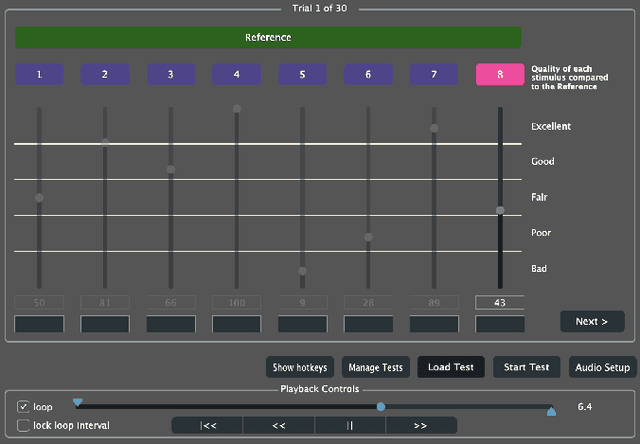
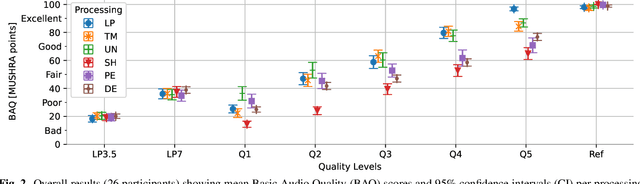
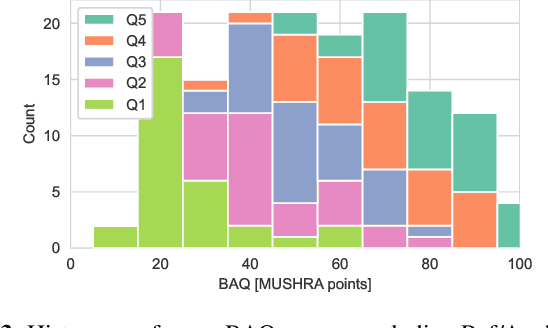
Research into the prediction and analysis of perceived audio quality is hampered by the scarcity of openly available datasets of audio signals accompanied by corresponding subjective quality scores. To address this problem, we present the Open Dataset of Audio Quality (ODAQ), a new dataset containing the results of a MUSHRA listening test conducted with expert listeners from 2 international laboratories. ODAQ contains 240 audio samples and corresponding quality scores. Each audio sample is rated by 26 listeners. The audio samples are stereo audio signals sampled at 44.1 or 48 kHz and are processed by a total of 6 method classes, each operating at different quality levels. The processing method classes are designed to generate quality degradations possibly encountered during audio coding and source separation, and the quality levels for each method class span the entire quality range. The diversity of the processing methods, the large span of quality levels, the high sampling frequency, and the pool of international listeners make ODAQ particularly suited for further research into subjective and objective audio quality. The dataset is released with permissive licenses, and the software used to conduct the listening test is also made publicly available.