 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Text-to-Speech Synthesis Using Noise-Augmented Training of ForwardTacotron
Paper and Code


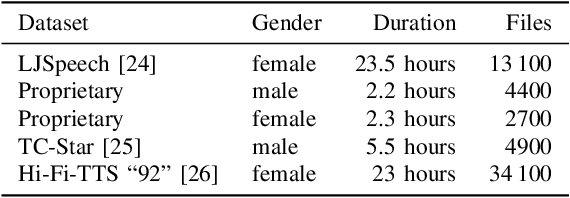
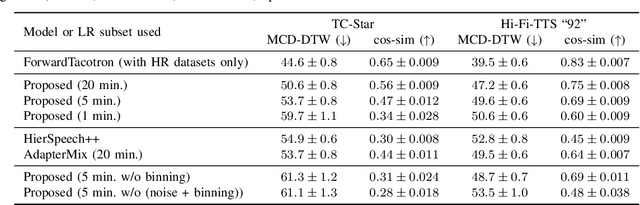
In recent years, several text-to-speech systems have been proposed to synthesize natural speech in zero-shot, few-shot, and low-resource scenarios. However, these methods typically require training with data from many different speakers. The speech quality across the speaker set typically is diverse and imposes an upper limit on the quality achievable for the low-resource speaker. In the current work, we achieve high-quality speech synthesis using as little as five minutes of speech from the desired speaker by augmenting the low-resource speaker data with noise and employing multiple sampling techniques during training. Our method requires only four high-quality, high-resource speakers, which are easy to obtain and use in practice. Our low-complexity method achieves improved speaker similarity compared to the state-of-the-art zero-shot method HierSpeech++ and the recent low-resource method AdapterMix while maintaining comparable naturalness. Our proposed approach can also reduce the data requirements for speech synthesis for new speakers and languages.