 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCount The Notes: Histogram-Based Supervision for Automatic Music Transcription
Nov 18, 2025Automatic Music Transcription (AMT) converts audio recordings into symbolic musical representations. Training deep neural networks (DNNs) for AMT typically requires strongly aligned training pairs with precise frame-level annotations. Since creating such datasets is costly and impractical for many musical contexts, weakly aligned approaches using segment-level annotations have gained traction. However, existing methods often rely on Dynamic Time Warping (DTW) or soft alignment loss functions, both of which still require local semantic correspondences, making them error-prone and computationally expensive. In this article, we introduce CountEM, a novel AMT framework that eliminates the need for explicit local alignment by leveraging note event histograms as supervision, enabling lighter computations and greater flexibility. Using an Expectation-Maximization (EM) approach, CountEM iteratively refines predictions based solely on note occurrence counts, significantly reducing annotation efforts while maintaining high transcription accuracy. Experiments on piano, guitar, and multi-instrument datasets demonstrate that CountEM matches or surpasses existing weakly supervised methods, improving AMT's robustness, scalability, and efficiency. Our project page is available at https://yoni-yaffe.github.io/count-the-notes.
Pitch Contour Exploration Across Audio Domains: A Vision-Based Transfer Learning Approach
Mar 24, 2025



This study examines pitch contours as a unifying semantic construct prevalent across various audio domains including music, speech, bioacoustics, and everyday sounds. Analyzing pitch contours offers insights into the universal role of pitch in the perceptual processing of audio signals and contributes to a deeper understanding of auditory mechanisms in both humans and animals. Conventional pitch-tracking methods, while optimized for music and speech, face challenges in handling much broader frequency ranges and more rapid pitch variations found in other audio domains. This study introduces a vision-based approach to pitch contour analysis that eliminates the need for explicit pitch-tracking. The approach uses a convolutional neural network, pre-trained for object detection in natural images and fine-tuned with a dataset of synthetically generated pitch contours, to extract key contour parameters from the time-frequency representation of short audio segments. A diverse set of eight downstream tasks from four audio domains were selected to provide a challenging evaluation scenario for cross-domain pitch contour analysis. The results show that the proposed method consistently surpasses traditional techniques based on pitch-tracking on a wide range of tasks. This suggests that the vision-based approach establishes a foundation for comparative studies of pitch contour characteristics across diverse audio domains.
Model-Based Deep Learning for Music Information Research
Jun 17, 2024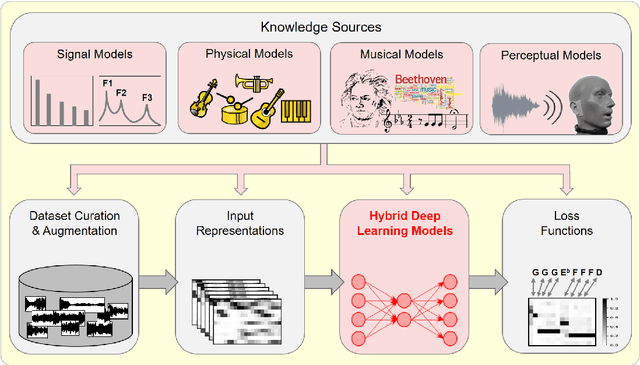
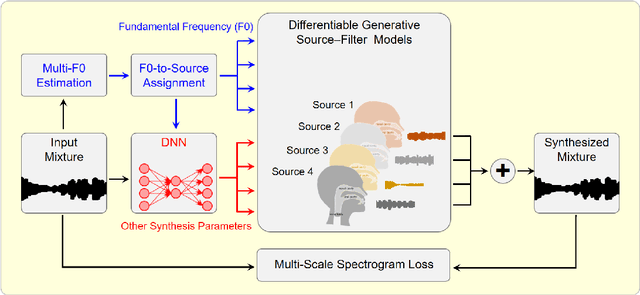
In this article, we investigate the notion of model-based deep learning in the realm of music information research (MIR). Loosely speaking, we refer to the term model-based deep learning for approaches that combine traditional knowledge-based methods with data-driven techniques, especially those based on deep learning, within a diff erentiable computing framework. In music, prior knowledge for instance related to sound production, music perception or music composition theory can be incorporated into the design of neural networks and associated loss functions. We outline three specifi c scenarios to illustrate the application of model-based deep learning in MIR, demonstrating the implementation of such concepts and their potential.
Performance Conditioning for Diffusion-Based Multi-Instrument Music Synthesis
Sep 21, 2023

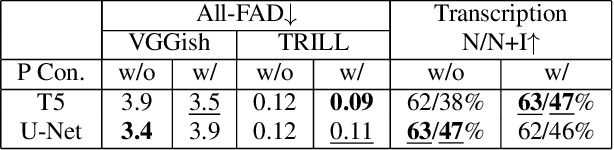

Generating multi-instrument music from symbolic music representations is an important task in Music Information Retrieval (MIR). A central but still largely unsolved problem in this context is musically and acoustically informed control in the generation process. As the main contribution of this work, we propose enhancing control of multi-instrument synthesis by conditioning a generative model on a specific performance and recording environment, thus allowing for better guidance of timbre and style. Building on state-of-the-art diffusion-based music generative models, we introduce performance conditioning - a simple tool indicating the generative model to synthesize music with style and timbre of specific instruments taken from specific performances. Our prototype is evaluated using uncurated performances with diverse instrumentation and achieves state-of-the-art FAD realism scores while allowing novel timbre and style control. Our project page, including samples and demonstrations, is available at benadar293.github.io/midipm
Local Periodicity-Based Beat Tracking for Expressive Classical Piano Music
Aug 20, 2023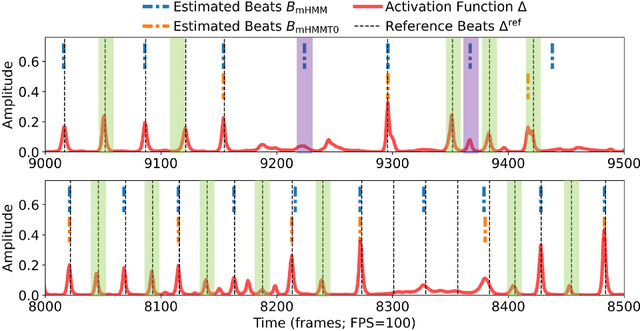
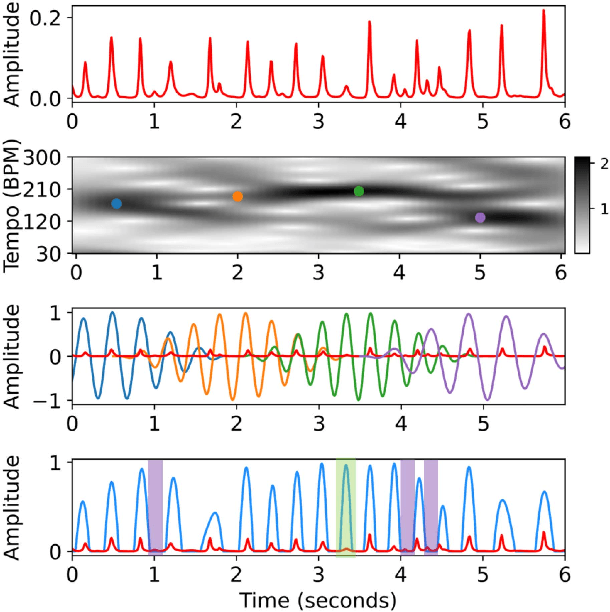
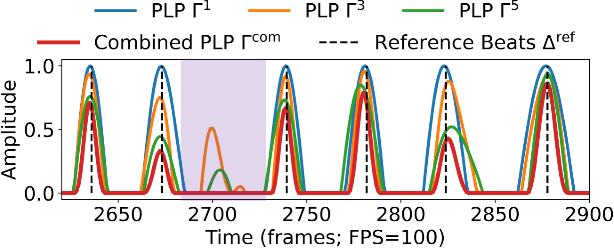
To model the periodicity of beats, state-of-the-art beat tracking systems use "post-processing trackers" (PPTs) that rely on several empirically determined global assumptions for tempo transition, which work well for music with a steady tempo. For expressive classical music, however, these assumptions can be too rigid. With two large datasets of Western classical piano music, namely the Aligned Scores and Performances (ASAP) dataset and a dataset of Chopin's Mazurkas (Maz-5), we report on experiments showing the failure of existing PPTs to cope with local tempo changes, thus calling for new methods. In this paper, we propose a new local periodicity-based PPT, called predominant local pulse-based dynamic programming (PLPDP) tracking, that allows for more flexible tempo transitions. Specifically, the new PPT incorporates a method called "predominant local pulses" (PLP) in combination with a dynamic programming (DP) component to jointly consider the locally detected periodicity and beat activation strength at each time instant. Accordingly, PLPDP accounts for the local periodicity, rather than relying on a global tempo assumption. Compared to existing PPTs, PLPDP particularly enhances the recall values at the cost of a lower precision, resulting in an overall improvement of F1-score for beat tracking in ASAP (from 0.473 to 0.493) and Maz-5 (from 0.595 to 0.838).
Stabilizing Training with Soft Dynamic Time Warping: A Case Study for Pitch Class Estimation with Weakly Aligned Targets
Aug 10, 2023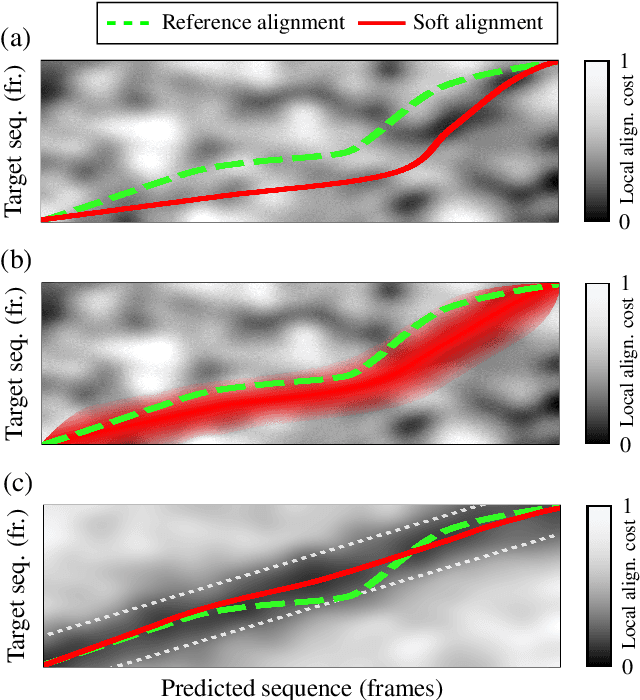
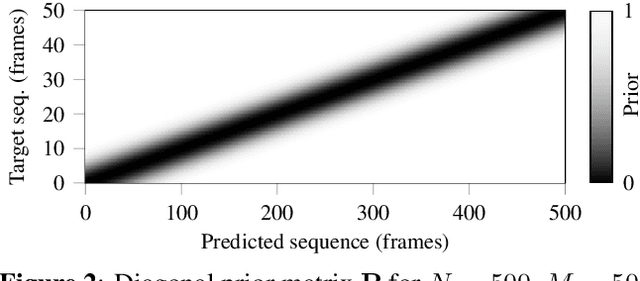
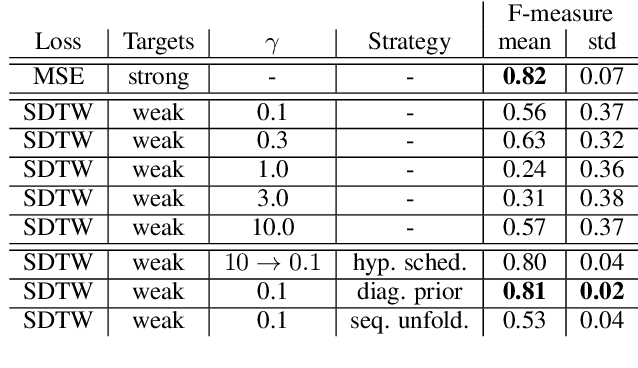
Soft dynamic time warping (SDTW) is a differentiable loss function that allows for training neural networks from weakly aligned data. Typically, SDTW is used to iteratively compute and refine soft alignments that compensate for temporal deviations between the training data and its weakly annotated targets. One major problem is that a mismatch between the estimated soft alignments and the reference alignments in the early training stage leads to incorrect parameter updates, making the overall training procedure unstable. In this paper, we investigate such stability issues by considering the task of pitch class estimation from music recordings as an illustrative case study. In particular, we introduce and discuss three conceptually different strategies (a hyperparameter scheduling, a diagonal prior, and a sequence unfolding strategy) with the objective of stabilizing intermediate soft alignment results. Finally, we report on experiments that demonstrate the effectiveness of the strategies and discuss efficiency and implementation issues.
Soft Dynamic Time Warping for Multi-Pitch Estimation and Beyond
Apr 11, 2023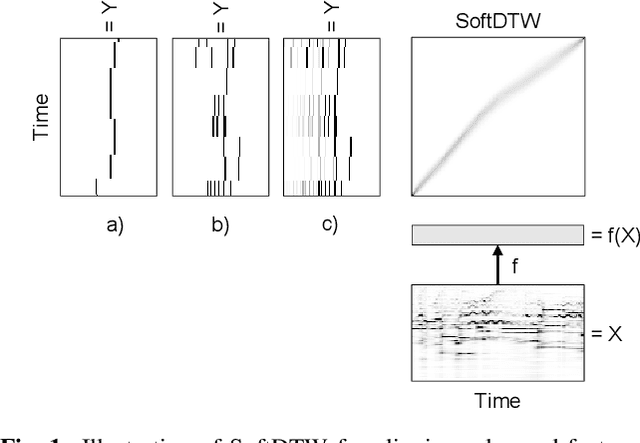
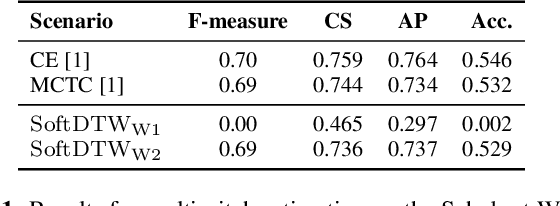
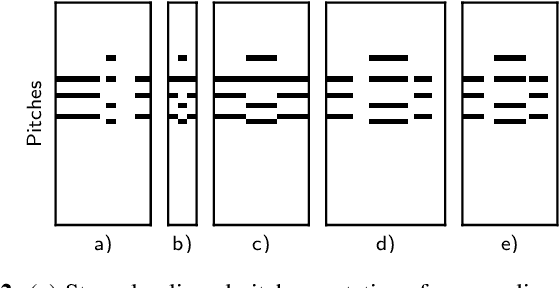

Many tasks in music information retrieval (MIR) involve weakly aligned data, where exact temporal correspondences are unknown. The connectionist temporal classification (CTC) loss is a standard technique to learn feature representations based on weakly aligned training data. However, CTC is limited to discrete-valued target sequences and can be difficult to extend to multi-label problems. In this article, we show how soft dynamic time warping (SoftDTW), a differentiable variant of classical DTW, can be used as an alternative to CTC. Using multi-pitch estimation as an example scenario, we show that SoftDTW yields results on par with a state-of-the-art multi-label extension of CTC. In addition to being more elegant in terms of its algorithmic formulation, SoftDTW naturally extends to real-valued target sequences.
An Analysis Method for Metric-Level Switching in Beat Tracking
Oct 13, 2022



For expressive music, the tempo may change over time, posing challenges to tracking the beats by an automatic model. The model may first tap to the correct tempo, but then may fail to adapt to a tempo change, or switch between several incorrect but perceptually plausible ones (e.g., half- or double-tempo). Existing evaluation metrics for beat tracking do not reflect such behaviors, as they typically assume a fixed relationship between the reference beats and estimated beats. In this paper, we propose a new performance analysis method, called annotation coverage ratio (ACR), that accounts for a variety of possible metric-level switching behaviors of beat trackers. The idea is to derive sequences of modified reference beats of all metrical levels for every two consecutive reference beats, and compare every sequence of modified reference beats to the subsequences of estimated beats. We show via experiments on three datasets of different genres the usefulness of ACR when utilized alongside existing metrics, and discuss the new insights to be gained.
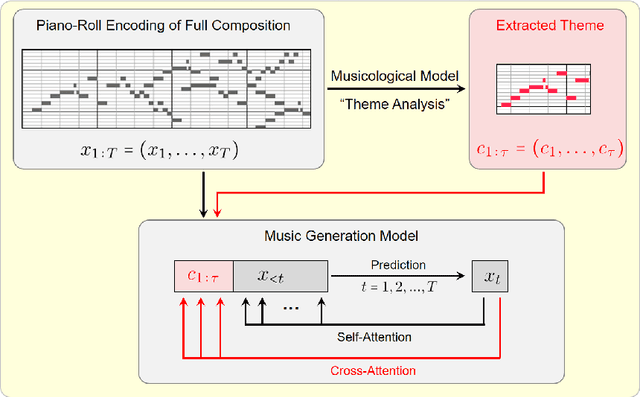
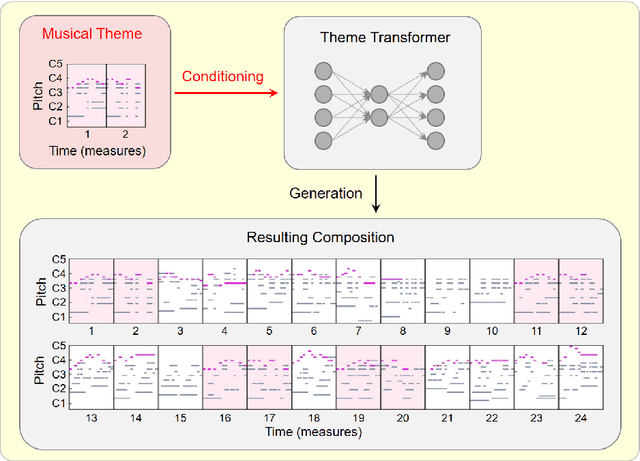
Theme Transformer: Symbolic Music Generation with Theme-Conditioned Transformer
Nov 07, 2021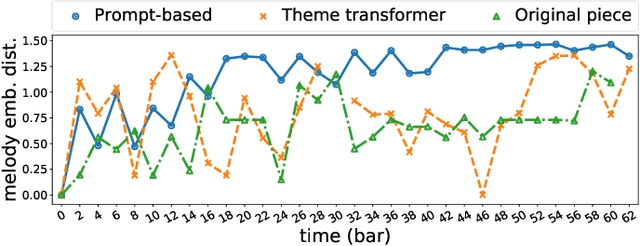
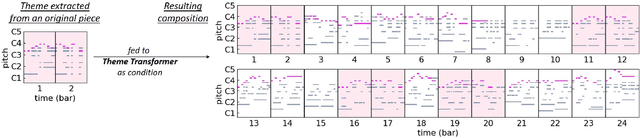
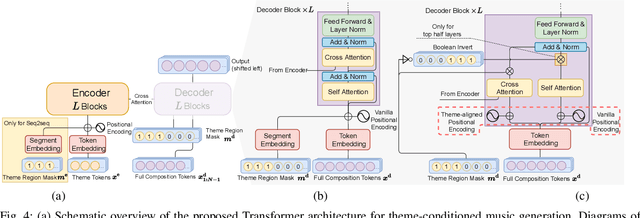
Attention-based Transformer models have been increasingly employed for automatic music generation. To condition the generation process of such a model with a user-specified sequence, a popular approach is to take that conditioning sequence as a priming sequence and ask a Transformer decoder to generate a continuation. However, this prompt-based conditioning cannot guarantee that the conditioning sequence would develop or even simply repeat itself in the generated continuation. In this paper, we propose an alternative conditioning approach, called theme-based conditioning, that explicitly trains the Transformer to treat the conditioning sequence as a thematic material that has to manifest itself multiple times in its generation result. This is achieved with two main technical contributions. First, we propose a deep learning-based approach that uses contrastive representation learning and clustering to automatically retrieve thematic materials from music pieces in the training data. Second, we propose a novel gated parallel attention module to be used in a sequence-to-sequence (seq2seq) encoder/decoder architecture to more effectively account for a given conditioning thematic material in the generation process of the Transformer decoder. We report on objective and subjective evaluations of variants of the proposed Theme Transformer and the conventional prompt-based baseline, showing that our best model can generate, to some extent, polyphonic pop piano music with repetition and plausible variations of a given condition.
Towards Audio Domain Adaptation for Acoustic Scene Classification using Disentanglement Learning
Oct 26, 2021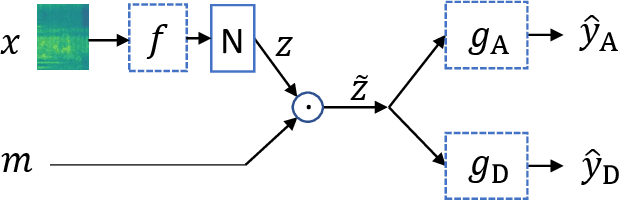
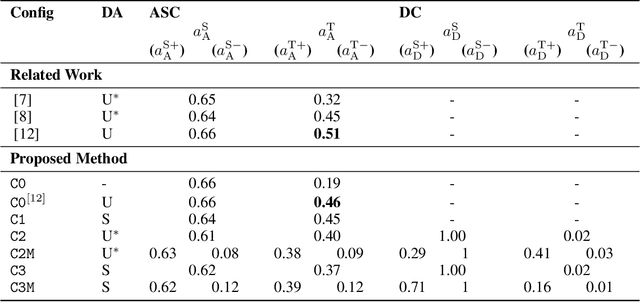

The deployment of machine listening algorithms in real-life applications is often impeded by a domain shift caused for instance by different microphone characteristics. In this paper, we propose a novel domain adaptation strategy based on disentanglement learning. The goal is to disentangle task-specific and domain-specific characteristics in the analyzed audio recordings. In particular, we combine two strategies: First, we apply different binary masks to internal embedding representations and, second, we suggest a novel combination of categorical cross-entropy and variance-based losses. Our results confirm the disentanglement of both tasks on an embedding level but show only minor improvement in the acoustic scene classification performance, when training data from both domains can be used. As a second finding, we can confirm the effectiveness of a state-of-the-art unsupervised domain adaptation strategy, which performs across-domain adaptation on a feature-level instead.