 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCount The Notes: Histogram-Based Supervision for Automatic Music Transcription
Nov 18, 2025Automatic Music Transcription (AMT) converts audio recordings into symbolic musical representations. Training deep neural networks (DNNs) for AMT typically requires strongly aligned training pairs with precise frame-level annotations. Since creating such datasets is costly and impractical for many musical contexts, weakly aligned approaches using segment-level annotations have gained traction. However, existing methods often rely on Dynamic Time Warping (DTW) or soft alignment loss functions, both of which still require local semantic correspondences, making them error-prone and computationally expensive. In this article, we introduce CountEM, a novel AMT framework that eliminates the need for explicit local alignment by leveraging note event histograms as supervision, enabling lighter computations and greater flexibility. Using an Expectation-Maximization (EM) approach, CountEM iteratively refines predictions based solely on note occurrence counts, significantly reducing annotation efforts while maintaining high transcription accuracy. Experiments on piano, guitar, and multi-instrument datasets demonstrate that CountEM matches or surpasses existing weakly supervised methods, improving AMT's robustness, scalability, and efficiency. Our project page is available at https://yoni-yaffe.github.io/count-the-notes.
Performance Conditioning for Diffusion-Based Multi-Instrument Music Synthesis
Sep 21, 2023

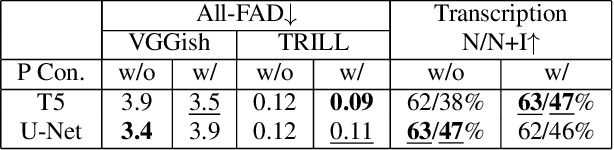

Generating multi-instrument music from symbolic music representations is an important task in Music Information Retrieval (MIR). A central but still largely unsolved problem in this context is musically and acoustically informed control in the generation process. As the main contribution of this work, we propose enhancing control of multi-instrument synthesis by conditioning a generative model on a specific performance and recording environment, thus allowing for better guidance of timbre and style. Building on state-of-the-art diffusion-based music generative models, we introduce performance conditioning - a simple tool indicating the generative model to synthesize music with style and timbre of specific instruments taken from specific performances. Our prototype is evaluated using uncurated performances with diverse instrumentation and achieves state-of-the-art FAD realism scores while allowing novel timbre and style control. Our project page, including samples and demonstrations, is available at benadar293.github.io/midipm
Unaligned Supervision For Automatic Music Transcription in The Wild
Apr 28, 2022

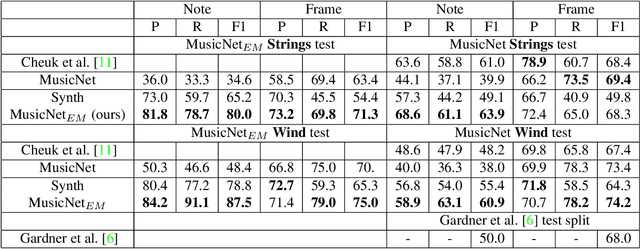

Multi-instrument Automatic Music Transcription (AMT), or the decoding of a musical recording into semantic musical content, is one of the holy grails of Music Information Retrieval. Current AMT approaches are restricted to piano and (some) guitar recordings, due to difficult data collection. In order to overcome data collection barriers, previous AMT approaches attempt to employ musical scores in the form of a digitized version of the same song or piece. The scores are typically aligned using audio features and strenuous human intervention to generate training labels. We introduce NoteEM, a method for simultaneously training a transcriber and aligning the scores to their corresponding performances, in a fully-automated process. Using this unaligned supervision scheme, complemented by pseudo-labels and pitch-shift augmentation, our method enables training on in-the-wild recordings with unprecedented accuracy and instrumental variety. Using only synthetic data and unaligned supervision, we report SOTA note-level accuracy of the MAPS dataset, and large favorable margins on cross-dataset evaluations. We also demonstrate robustness and ease of use; we report comparable results when training on a small, easily obtainable, self-collected dataset, and we propose alternative labeling to the MusicNet dataset, which we show to be more accurate. Our project page is available at https://benadar293.github.io