 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Conditioning for Diffusion-Based Multi-Instrument Music Synthesis
Sep 21, 2023

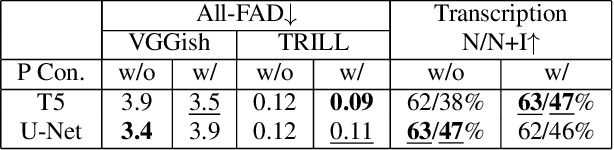

Generating multi-instrument music from symbolic music representations is an important task in Music Information Retrieval (MIR). A central but still largely unsolved problem in this context is musically and acoustically informed control in the generation process. As the main contribution of this work, we propose enhancing control of multi-instrument synthesis by conditioning a generative model on a specific performance and recording environment, thus allowing for better guidance of timbre and style. Building on state-of-the-art diffusion-based music generative models, we introduce performance conditioning - a simple tool indicating the generative model to synthesize music with style and timbre of specific instruments taken from specific performances. Our prototype is evaluated using uncurated performances with diverse instrumentation and achieves state-of-the-art FAD realism scores while allowing novel timbre and style control. Our project page, including samples and demonstrations, is available at benadar293.github.io/midipm
Stabilizing Training with Soft Dynamic Time Warping: A Case Study for Pitch Class Estimation with Weakly Aligned Targets
Aug 10, 2023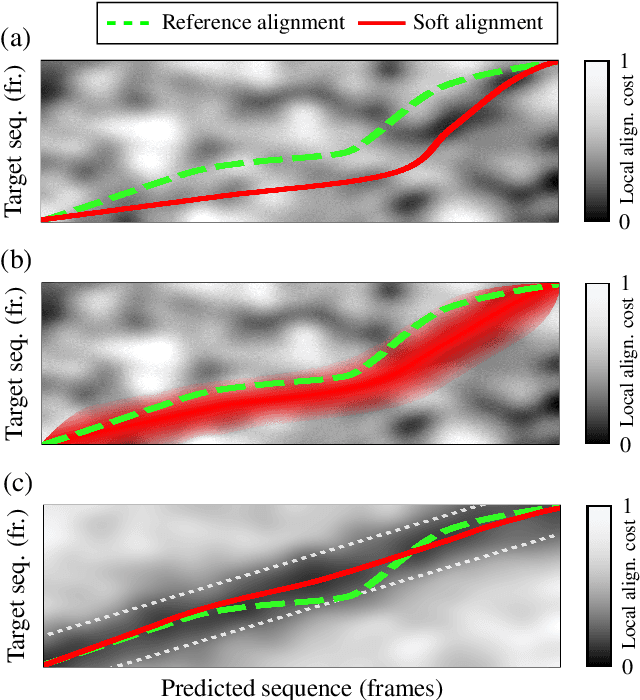
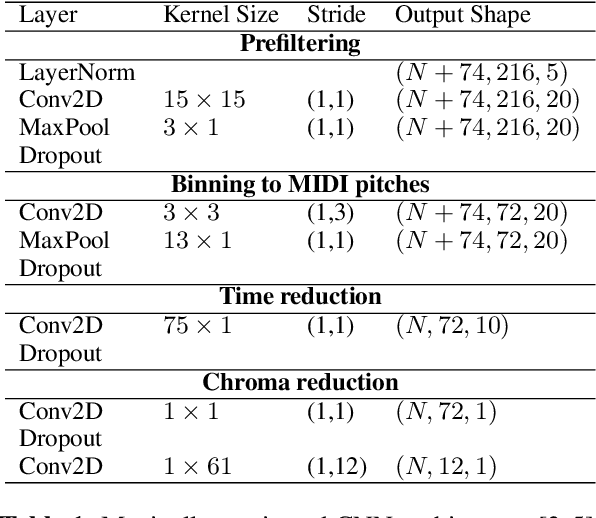
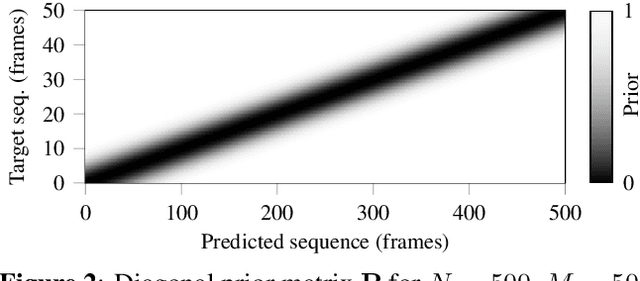
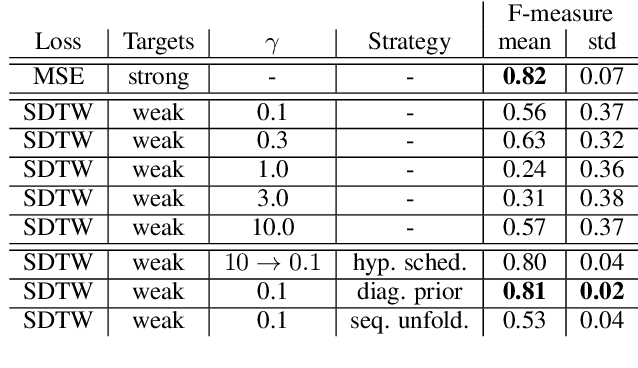
Soft dynamic time warping (SDTW) is a differentiable loss function that allows for training neural networks from weakly aligned data. Typically, SDTW is used to iteratively compute and refine soft alignments that compensate for temporal deviations between the training data and its weakly annotated targets. One major problem is that a mismatch between the estimated soft alignments and the reference alignments in the early training stage leads to incorrect parameter updates, making the overall training procedure unstable. In this paper, we investigate such stability issues by considering the task of pitch class estimation from music recordings as an illustrative case study. In particular, we introduce and discuss three conceptually different strategies (a hyperparameter scheduling, a diagonal prior, and a sequence unfolding strategy) with the objective of stabilizing intermediate soft alignment results. Finally, we report on experiments that demonstrate the effectiveness of the strategies and discuss efficiency and implementation issues.
Manifold learning-supported estimation of relative transfer functions for spatial filtering
Oct 05, 2021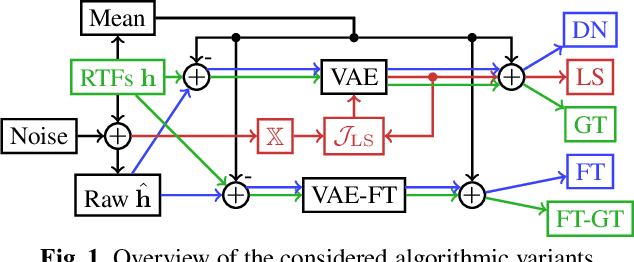

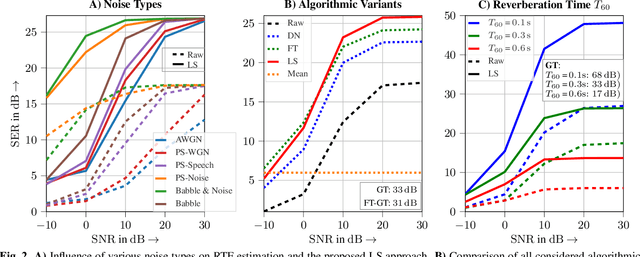
Many spatial filtering algorithms used for voice capture in, e.g., teleconferencing applications, can benefit from or even rely on knowledge of Relative Transfer Functions (RTFs). Accordingly, many RTF estimators have been proposed which, however, suffer from performance degradation under acoustically adverse conditions or need prior knowledge on the properties of the interfering sources. While state-of-the-art RTF estimators ignore prior knowledge about the acoustic enclosure, audio signal processing algorithms for teleconferencing equipment are often operating in the same or at least a similar acoustic enclosure, e.g., a car or an office, such that training data can be collected. In this contribution, we use such data to train Variational Autoencoders (VAEs) in an unsupervised manner and apply the trained VAEs to enhance imprecise RTF estimates. Furthermore, a hybrid between classic RTF estimation and the trained VAE is investigated. Comprehensive experiments with real-world data confirm the efficacy for the proposed method.