 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold learning-supported estimation of relative transfer functions for spatial filtering
Paper and Code
Oct 05, 2021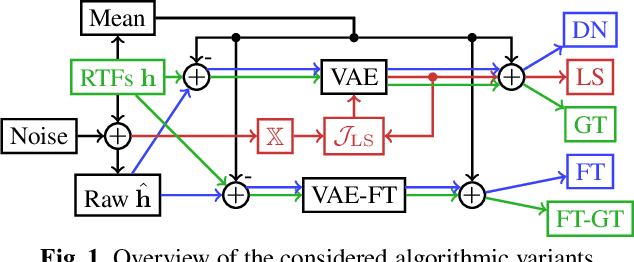

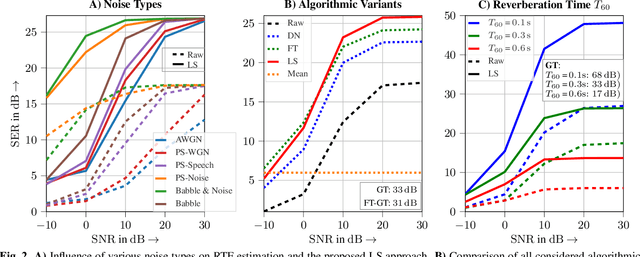
Many spatial filtering algorithms used for voice capture in, e.g., teleconferencing applications, can benefit from or even rely on knowledge of Relative Transfer Functions (RTFs). Accordingly, many RTF estimators have been proposed which, however, suffer from performance degradation under acoustically adverse conditions or need prior knowledge on the properties of the interfering sources. While state-of-the-art RTF estimators ignore prior knowledge about the acoustic enclosure, audio signal processing algorithms for teleconferencing equipment are often operating in the same or at least a similar acoustic enclosure, e.g., a car or an office, such that training data can be collected. In this contribution, we use such data to train Variational Autoencoders (VAEs) in an unsupervised manner and apply the trained VAEs to enhance imprecise RTF estimates. Furthermore, a hybrid between classic RTF estimation and the trained VAE is investigated. Comprehensive experiments with real-world data confirm the efficacy for the proposed method.