 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Likelihood Ratio Estimation for Pixel-Wise Out-of-Distribution Detection
Aug 01, 2025Semantic segmentation models trained on known object classes often fail in real-world autonomous driving scenarios by confidently misclassifying unknown objects. While pixel-wise out-of-distribution detection can identify unknown objects, existing methods struggle in complex scenes where rare object classes are often confused with truly unknown objects. We introduce an uncertainty-aware likelihood ratio estimation method that addresses these limitations. Our approach uses an evidential classifier within a likelihood ratio test to distinguish between known and unknown pixel features from a semantic segmentation model, while explicitly accounting for uncertainty. Instead of producing point estimates, our method outputs probability distributions that capture uncertainty from both rare training examples and imperfect synthetic outliers. We show that by incorporating uncertainty in this way, outlier exposure can be leveraged more effectively. Evaluated on five standard benchmark datasets, our method achieves the lowest average false positive rate (2.5%) among state-of-the-art while maintaining high average precision (90.91%) and incurring only negligible computational overhead. Code is available at https://github.com/glasbruch/ULRE.
Spatially constrained vs. unconstrained filtering in neural spatiospectral filters for multichannel speech enhancement
Jun 17, 2024



When using artificial neural networks for multichannel speech enhancement, filtering is often achieved by estimating a complex-valued mask that is applied to all or one reference channel of the input signal. The estimation of this mask is based on the noisy multichannel signal and, hence, can exploit spatial and spectral cues simultaneously. While it has been shown that exploiting spatial and spectral cues jointly is beneficial for the speech enhancement result, the mechanics of the interplay of the two inside the neural network are still largely unknown. In this contribution, we investigate how two conceptually different neural spatiospectral filters (NSSFs) exploit spatial cues depending on the training target signal and show that, while one NSSF always performs spatial filtering, the other one is selective in leveraging spatial information depending on the task at hand. These insights provide better understanding of the information the NSSFs use to make their prediction and, thus, allow to make informed decisions regarding their design and deployment.
End-To-End Deep Learning-based Adaptation Control for Linear Acoustic Echo Cancellation
Jun 04, 2023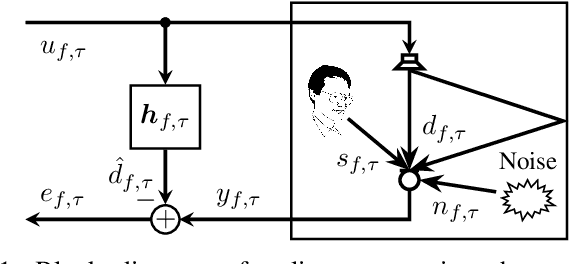
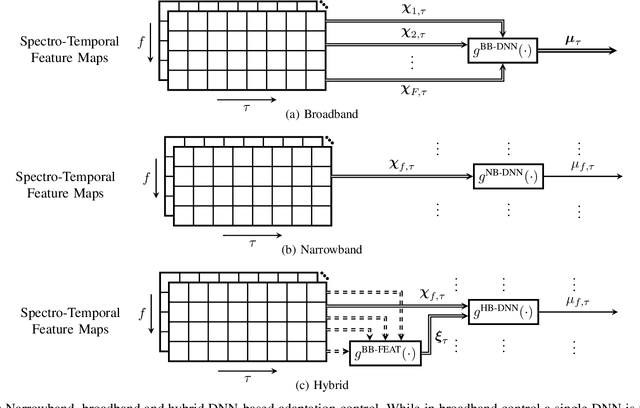
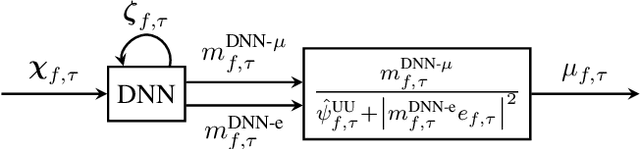
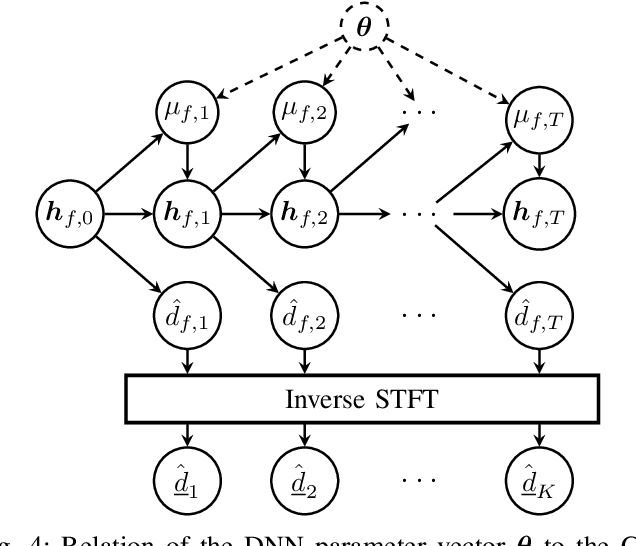
The attenuation of acoustic loudspeaker echoes remains to be one of the open challenges to achieve pleasant full-duplex hands free speech communication. In many modern signal enhancement interfaces, this problem is addressed by a linear acoustic echo canceler which subtracts a loudspeaker echo estimate from the recorded microphone signal. To obtain precise echo estimates, the parameters of the echo canceler, i.e., the filter coefficients, need to be estimated quickly and precisely from the observed loudspeaker and microphone signals. For this a sophisticated adaptation control is required to deal with high-power double-talk and rapidly track time-varying acoustic environments which are often faced with portable devices. In this paper, we address this problem by end-to-end deep learning. In particular, we suggest to infer the step-size for a least mean squares frequency-domain adaptive filter update by a Deep Neural Network (DNN). Two different step-size inference approaches are investigated. On the one hand broadband approaches, which use a single DNN to jointly infer step-sizes for all frequency bands, and on the other hand narrowband methods, which exploit individual DNNs per frequency band. The discussion of benefits and disadvantages of both approaches leads to a novel hybrid approach which shows improved echo cancellation while requiring only small DNN architectures. Furthermore, we investigate the effect of different loss functions, signal feature vectors, and DNN output layer architectures on the echo cancellation performance from which we obtain valuable insights into the general design and functionality of DNN-based adaptation control algorithms.
Novel features for the detection of bearing faults in railway vehicles
Apr 14, 2023



{In this paper, we address the challenging problem of detecting bearing faults from vibration signals. For this, several time- and frequency-domain features have been proposed already in the past. However, these features are usually evaluated on data originating from relatively simple scenarios and a significant performance loss can be observed if more realistic scenarios are considered. To overcome this, we introduce Mel-Frequency Cepstral Coefficients (MFCCs) and features extracted from the Amplitude Modulation Spectrogram (AMS) as features for the detection of bearing faults. Both AMS and MFCCs were originally introduced in the context of audio signal processing but it is demonstrated that a significantly improved classification performance can be obtained by using these features. Furthermore, to tackle the characteristic data imbalance problem in the context of bearing fault detection, i.e., typically much more data from healthy bearings than from damaged bearings is available, we propose to train a One-class \ac{SVM} with data from healthy bearings only. Bearing faults are then classified by the detection of outliers. Our approach is evaluated with data measured in a highly challenging scenario comprising a state-of-the-art commuter railway engine which is supplied by an industrial power converter and coupled to a load machine.
1-D Residual Convolutional Neural Network coupled with Data Augmentation and Regularization Techniques for the ICPHM 2023 Data Challenge
Apr 14, 2023In this article, we present our contribution to the ICPHM 2023 Data Challenge on Industrial Systems' Health Monitoring using Vibration Analysis. For the task of classifying sun gear faults in a gearbox, we propose a residual Convolutional Neural Network that operates on raw three-channel time-domain vibration signals. In conjunction with data augmentation and regularization techniques, the proposed model yields very good results in a multi-class classification scenario with real-world data despite its relatively small size, i.e., with less than 30,000 trainable parameters. Even when presented with data obtained from multiple operating conditions, the network is still capable to accurately predict the condition of the gearbox under inspection.
Airborne-Sound Analysis for the Detection of Bearing Faults in Railway Vehicles with Real-World Data
Apr 14, 2023In this paper, we address the challenging problem of detecting bearing faults in railway vehicles by analyzing acoustic signals recorded during regular operation. For this, we introduce Mel Frequency Cepstral Coefficients (MFCCs) as features, which form the input to a simple Multi-Layer Perceptron classifier. The proposed method is evaluated with real-world data that was obtained for state-of-the-art commuter railway vehicles in a measurement campaign. The experiments show that with the chosen MFCC features bearing faults can be reliably detected even for bearing damages that were not included in training.
Localizing Spatial Information in Neural Spatiospectral Filters
Mar 14, 2023Beamforming for multichannel speech enhancement relies on the estimation of spatial characteristics of the acoustic scene. In its simplest form, the delay-and-sum beamformer (DSB) introduces a time delay to all channels to align the desired signal components for constructive superposition. Recent investigations of neural spatiospectral filtering revealed that these filters can be characterized by a beampattern similar to one of traditional beamformers, which shows that artificial neural networks can learn and explicitly represent spatial structure. Using the Complex-valued Spatial Autoencoder (COSPA) as an exemplary neural spatiospectral filter for multichannel speech enhancement, we investigate where and how such networks represent spatial information. We show via clustering that for COSPA the spatial information is represented by the features generated by a gated recurrent unit (GRU) layer that has access to all channels simultaneously and that these features are not source -- but only direction of arrival-dependent.
Exploiting spatial information with the informed complex-valued spatial autoencoder for target speaker extraction
Oct 27, 2022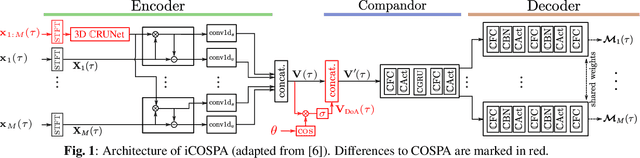
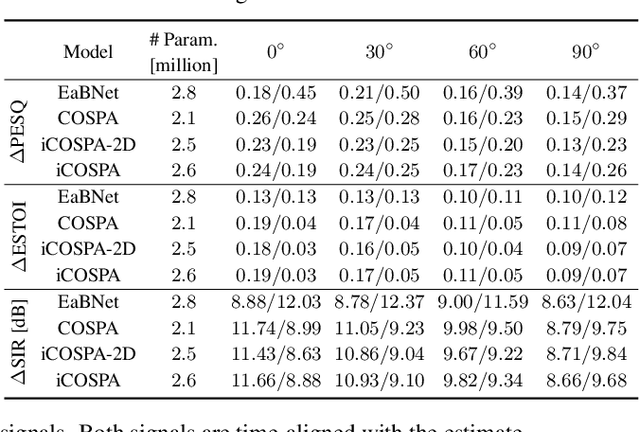

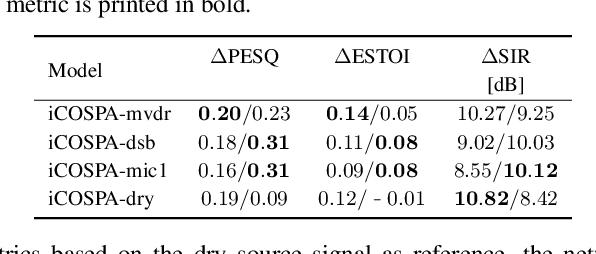
In conventional multichannel audio signal enhancement, spatial and spectral filtering are often performed sequentially. In contrast, it has been shown that for neural spatial filtering a joint approach of spectro-spatial filtering is more beneficial. In this contribution, we investigate the influence of the training target on the spatial selectivity of such a time-varying spectro-spatial filter. We extend the recently proposed complex-valued spatial autoencoder (COSPA) for target speaker extraction by leveraging its interpretable structure and purposefully informing the network of the target speaker's position. Consequently, this approach uses a multichannel complex-valued neural network architecture that is capable of processing spatial and spectral information rendering informed COSPA (iCOSPA) an effective neural spatial filtering method. We train iCOSPA for several training targets that enforce different amounts of spatial processing and analyze the network's spatial filtering capacity. We find that the proposed architecture is indeed capable of learning different spatial selectivity patterns to attain the different training targets.
A Unifying View on Blind Source Separation of Convolutive Mixtures based on Independent Component Analysis
Jul 28, 2022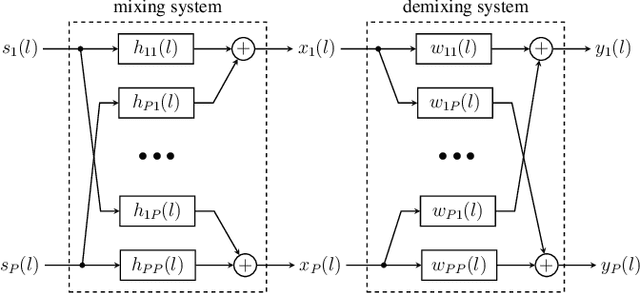
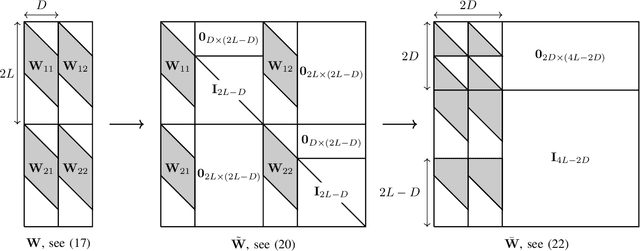
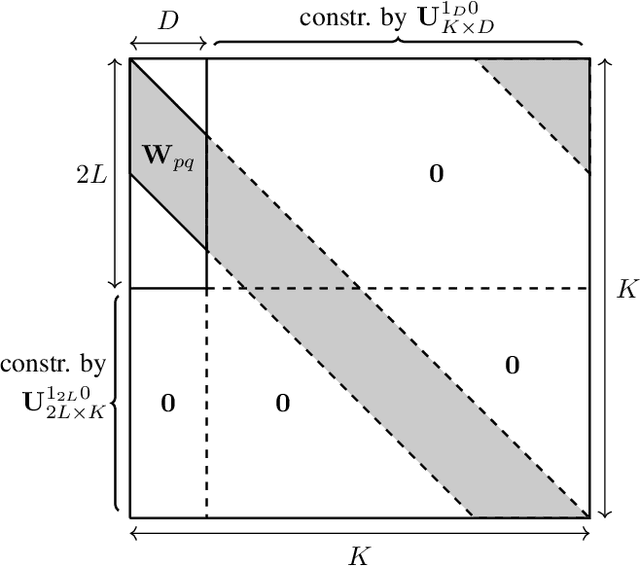

In many daily-life scenarios, acoustic sources recorded in an enclosure can only be observed with other interfering sources. Hence, convolutive Blind Source Separation (BSS) is a central problem in audio signal processing. Methods based on Independent Component Analysis (ICA) are especially important in this field as they require only few and weak assumptions and allow for blindness regarding the original source signals and the acoustic propagation path. Most of the currently used algorithms belong to one of the following three families: Frequency Domain ICA (FD-ICA), Independent Vector Analysis (IVA), and TRIple-N Independent component analysis for CONvolutive mixtures (TRINICON). While the relation between ICA, FD-ICA and IVA becomes apparent due to their construction, the relation to TRINICON is not well established yet. This paper fills this gap by providing an in-depth treatment of the common building blocks of these algorithms and their differences, and thus provides a common framework for all considered algorithms.
Joint Acoustic Echo Cancellation and Blind Source Extraction based on Independent Vector Extraction
May 13, 2022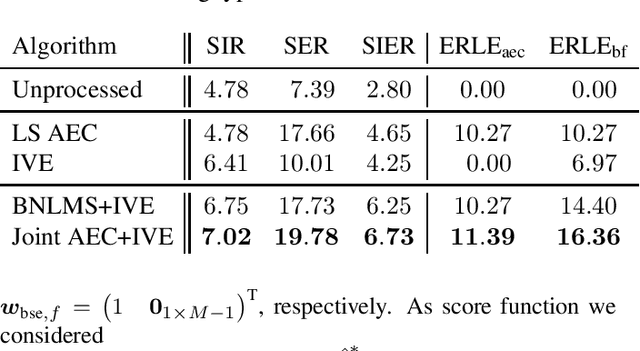
We describe a joint acoustic echo cancellation (AEC) and blind source extraction (BSE) approach for multi-microphone acoustic frontends. The proposed algorithm blindly estimates AEC and beamforming filters by maximizing the statistical independence of a non-Gaussian source of interest and a stationary Gaussian background modeling interfering signals and residual echo. Double talk-robust and fast-converging parameter updates are derived from a global maximum-likelihood objective function resulting in a computationally efficient Newton-type update rule. Evaluation with simulated acoustic data confirms the benefit of the proposed joint AEC and beamforming filter estimation in comparison to updating both filters individually.