 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially constrained vs. unconstrained filtering in neural spatiospectral filters for multichannel speech enhancement
Jun 17, 2024



When using artificial neural networks for multichannel speech enhancement, filtering is often achieved by estimating a complex-valued mask that is applied to all or one reference channel of the input signal. The estimation of this mask is based on the noisy multichannel signal and, hence, can exploit spatial and spectral cues simultaneously. While it has been shown that exploiting spatial and spectral cues jointly is beneficial for the speech enhancement result, the mechanics of the interplay of the two inside the neural network are still largely unknown. In this contribution, we investigate how two conceptually different neural spatiospectral filters (NSSFs) exploit spatial cues depending on the training target signal and show that, while one NSSF always performs spatial filtering, the other one is selective in leveraging spatial information depending on the task at hand. These insights provide better understanding of the information the NSSFs use to make their prediction and, thus, allow to make informed decisions regarding their design and deployment.
Localizing Spatial Information in Neural Spatiospectral Filters
Mar 14, 2023Beamforming for multichannel speech enhancement relies on the estimation of spatial characteristics of the acoustic scene. In its simplest form, the delay-and-sum beamformer (DSB) introduces a time delay to all channels to align the desired signal components for constructive superposition. Recent investigations of neural spatiospectral filtering revealed that these filters can be characterized by a beampattern similar to one of traditional beamformers, which shows that artificial neural networks can learn and explicitly represent spatial structure. Using the Complex-valued Spatial Autoencoder (COSPA) as an exemplary neural spatiospectral filter for multichannel speech enhancement, we investigate where and how such networks represent spatial information. We show via clustering that for COSPA the spatial information is represented by the features generated by a gated recurrent unit (GRU) layer that has access to all channels simultaneously and that these features are not source -- but only direction of arrival-dependent.
Exploiting spatial information with the informed complex-valued spatial autoencoder for target speaker extraction
Oct 27, 2022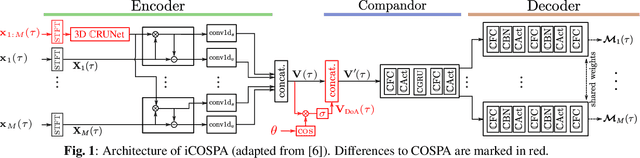
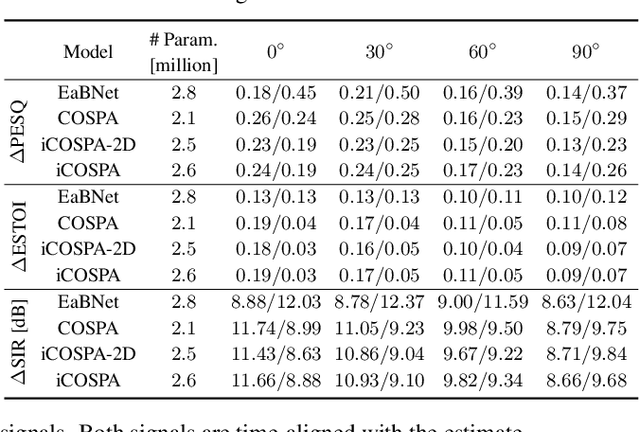

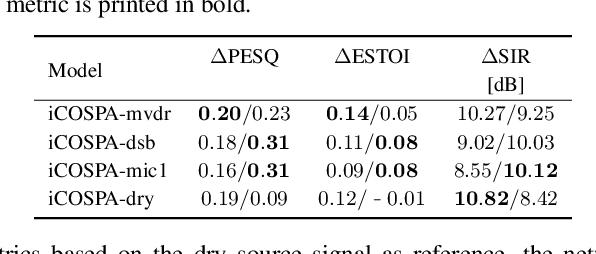
In conventional multichannel audio signal enhancement, spatial and spectral filtering are often performed sequentially. In contrast, it has been shown that for neural spatial filtering a joint approach of spectro-spatial filtering is more beneficial. In this contribution, we investigate the influence of the training target on the spatial selectivity of such a time-varying spectro-spatial filter. We extend the recently proposed complex-valued spatial autoencoder (COSPA) for target speaker extraction by leveraging its interpretable structure and purposefully informing the network of the target speaker's position. Consequently, this approach uses a multichannel complex-valued neural network architecture that is capable of processing spatial and spectral information rendering informed COSPA (iCOSPA) an effective neural spatial filtering method. We train iCOSPA for several training targets that enforce different amounts of spatial processing and analyze the network's spatial filtering capacity. We find that the proposed architecture is indeed capable of learning different spatial selectivity patterns to attain the different training targets.