 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-To-End Deep Learning-based Adaptation Control for Linear Acoustic Echo Cancellation
Jun 04, 2023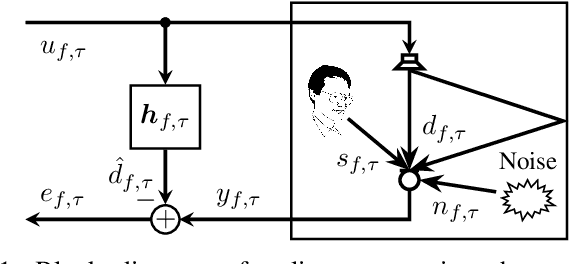
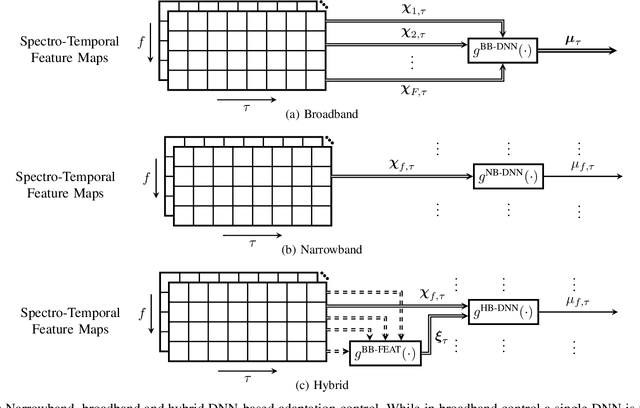
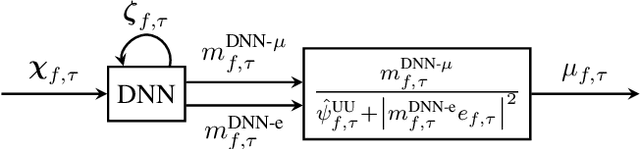
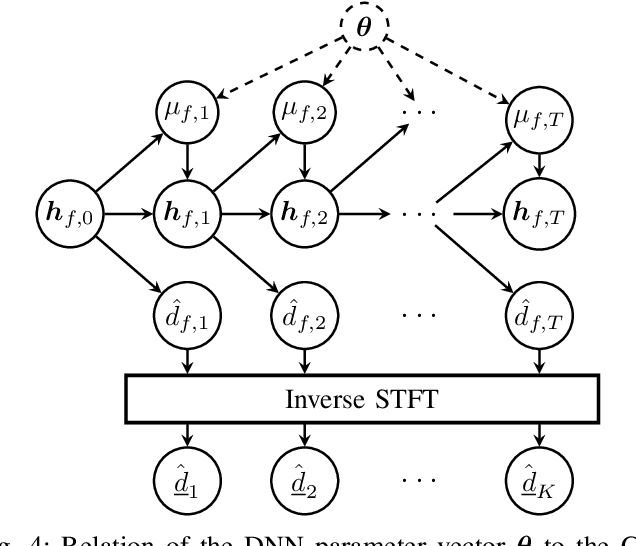
The attenuation of acoustic loudspeaker echoes remains to be one of the open challenges to achieve pleasant full-duplex hands free speech communication. In many modern signal enhancement interfaces, this problem is addressed by a linear acoustic echo canceler which subtracts a loudspeaker echo estimate from the recorded microphone signal. To obtain precise echo estimates, the parameters of the echo canceler, i.e., the filter coefficients, need to be estimated quickly and precisely from the observed loudspeaker and microphone signals. For this a sophisticated adaptation control is required to deal with high-power double-talk and rapidly track time-varying acoustic environments which are often faced with portable devices. In this paper, we address this problem by end-to-end deep learning. In particular, we suggest to infer the step-size for a least mean squares frequency-domain adaptive filter update by a Deep Neural Network (DNN). Two different step-size inference approaches are investigated. On the one hand broadband approaches, which use a single DNN to jointly infer step-sizes for all frequency bands, and on the other hand narrowband methods, which exploit individual DNNs per frequency band. The discussion of benefits and disadvantages of both approaches leads to a novel hybrid approach which shows improved echo cancellation while requiring only small DNN architectures. Furthermore, we investigate the effect of different loss functions, signal feature vectors, and DNN output layer architectures on the echo cancellation performance from which we obtain valuable insights into the general design and functionality of DNN-based adaptation control algorithms.
Localizing Spatial Information in Neural Spatiospectral Filters
Mar 14, 2023Beamforming for multichannel speech enhancement relies on the estimation of spatial characteristics of the acoustic scene. In its simplest form, the delay-and-sum beamformer (DSB) introduces a time delay to all channels to align the desired signal components for constructive superposition. Recent investigations of neural spatiospectral filtering revealed that these filters can be characterized by a beampattern similar to one of traditional beamformers, which shows that artificial neural networks can learn and explicitly represent spatial structure. Using the Complex-valued Spatial Autoencoder (COSPA) as an exemplary neural spatiospectral filter for multichannel speech enhancement, we investigate where and how such networks represent spatial information. We show via clustering that for COSPA the spatial information is represented by the features generated by a gated recurrent unit (GRU) layer that has access to all channels simultaneously and that these features are not source -- but only direction of arrival-dependent.
A Unifying View on Blind Source Separation of Convolutive Mixtures based on Independent Component Analysis
Jul 28, 2022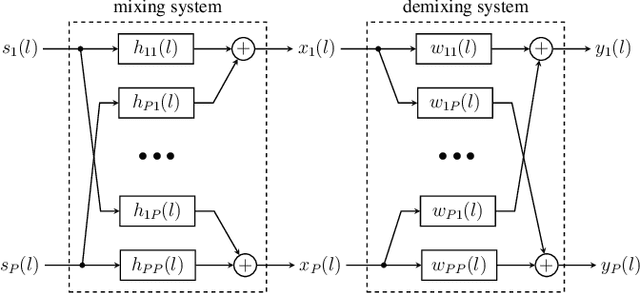
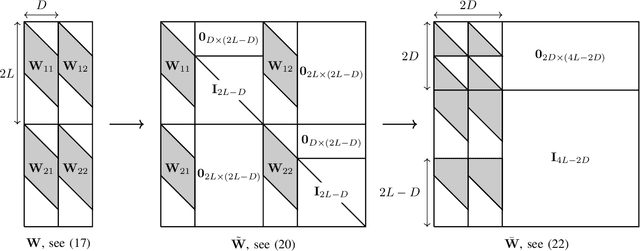
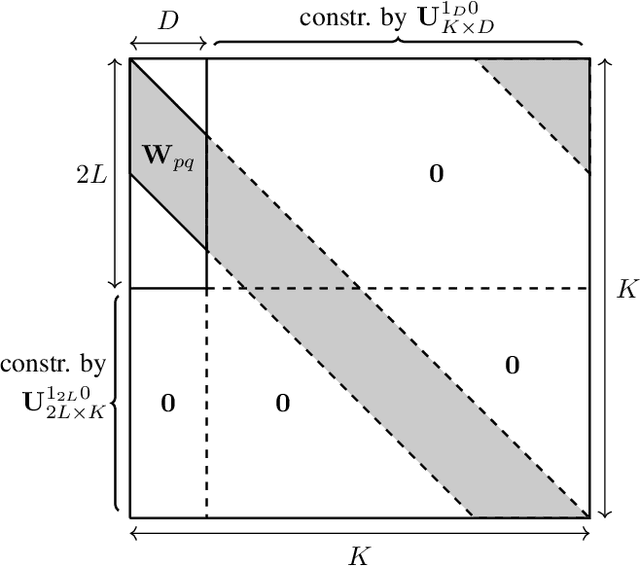

In many daily-life scenarios, acoustic sources recorded in an enclosure can only be observed with other interfering sources. Hence, convolutive Blind Source Separation (BSS) is a central problem in audio signal processing. Methods based on Independent Component Analysis (ICA) are especially important in this field as they require only few and weak assumptions and allow for blindness regarding the original source signals and the acoustic propagation path. Most of the currently used algorithms belong to one of the following three families: Frequency Domain ICA (FD-ICA), Independent Vector Analysis (IVA), and TRIple-N Independent component analysis for CONvolutive mixtures (TRINICON). While the relation between ICA, FD-ICA and IVA becomes apparent due to their construction, the relation to TRINICON is not well established yet. This paper fills this gap by providing an in-depth treatment of the common building blocks of these algorithms and their differences, and thus provides a common framework for all considered algorithms.
Joint Acoustic Echo Cancellation and Blind Source Extraction based on Independent Vector Extraction
May 13, 2022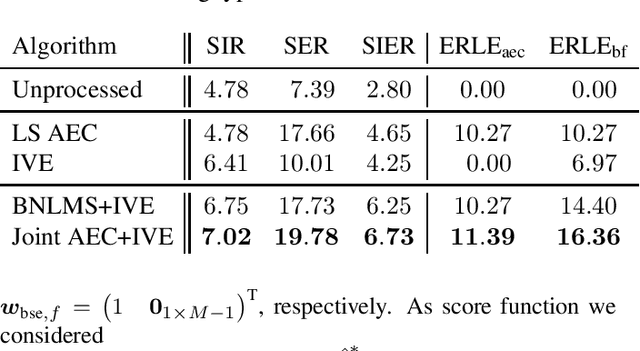
We describe a joint acoustic echo cancellation (AEC) and blind source extraction (BSE) approach for multi-microphone acoustic frontends. The proposed algorithm blindly estimates AEC and beamforming filters by maximizing the statistical independence of a non-Gaussian source of interest and a stationary Gaussian background modeling interfering signals and residual echo. Double talk-robust and fast-converging parameter updates are derived from a global maximum-likelihood objective function resulting in a computationally efficient Newton-type update rule. Evaluation with simulated acoustic data confirms the benefit of the proposed joint AEC and beamforming filter estimation in comparison to updating both filters individually.
Deep Learning-Based Joint Control of Acoustic Echo Cancellation, Beamforming and Postfiltering
Mar 03, 2022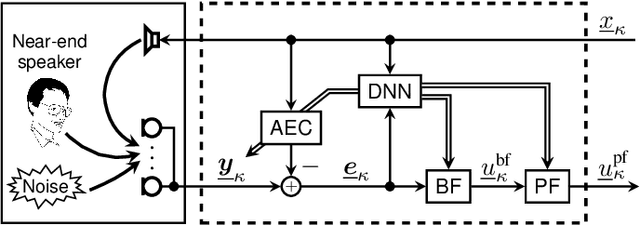
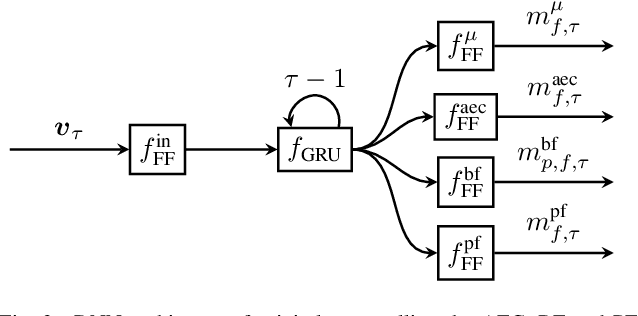
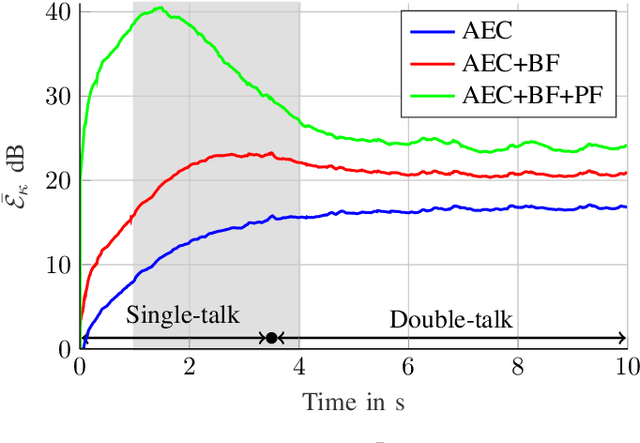
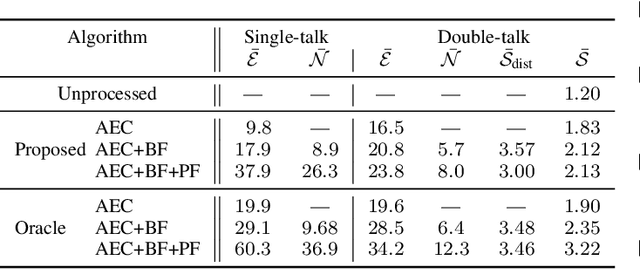
We introduce a novel method for controlling the functionality of a hands-free speech communication device which comprises a model-based acoustic echo canceller (AEC), minimum variance distortionless response (MVDR) beamformer (BF) and spectral postfilter (PF). While the AEC removes the early echo component, the MVDR BF and PF suppress the residual echo and background noise. As key innovation, we suggest to use a single deep neural network (DNN) to jointly control the adaptation of the various algorithmic components. This allows for rapid convergence and high steady-state performance in the presence of high-level interfering double-talk. End-to-end training of the DNN using a time-domain speech extraction loss function avoids the design of individual control strategies.
End-To-End Deep Learning-Based Adaptation Control for Frequency-Domain Adaptive System Identification
Jun 02, 2021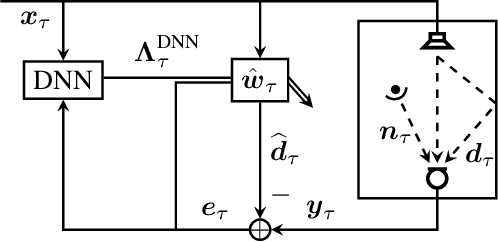



We present a novel end-to-end deep learning-based adaptation control algorithm for frequency-domain adaptive system identification. The proposed method exploits a deep neural network to map observed signal features to corresponding step-sizes which control the filter adaptation. The parameters of the network are optimized in an end-to-end fashion by minimizing the average system distance of the adaptive filter. This avoids the need of explicit signal power spectral density estimation as required for model-based adaptation control and further auxiliary mechanisms to deal with model inaccuracies. The proposed algorithm achieves fast convergence and robust steady-state performance for scenarios characterized by non-white and non-stationary noise signals, time-varying environment changes and additional model inaccuracies.
Online Acoustic System Identification Exploiting Kalman Filtering and an Adaptive Impulse Response Subspace Model
May 07, 2021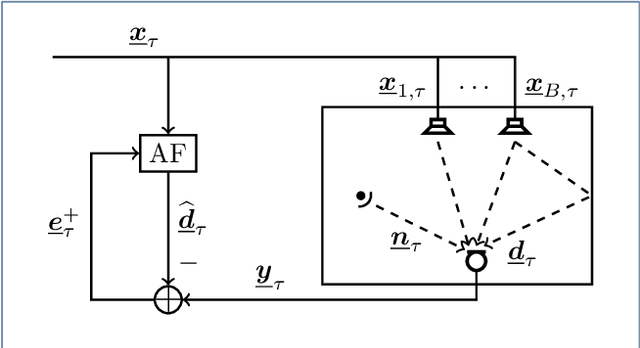
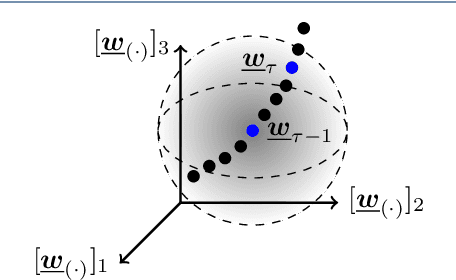
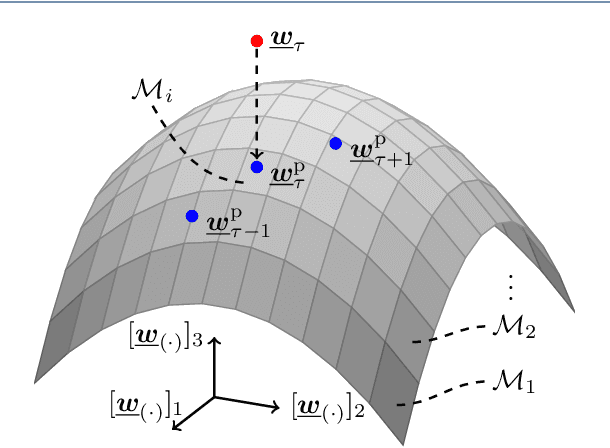
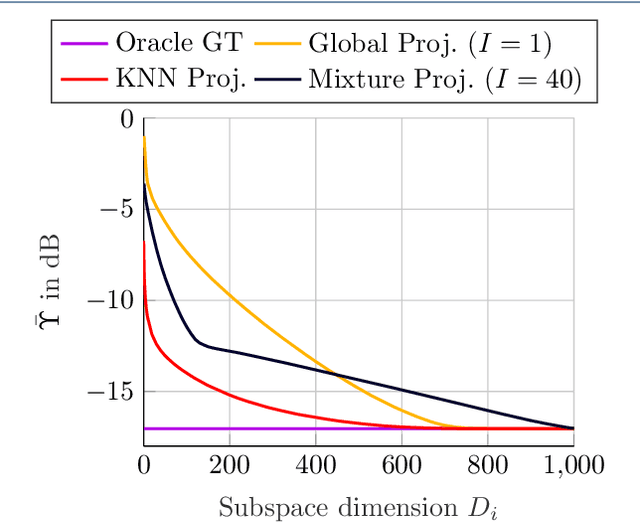
We introduce a novel algorithm for online estimation of acoustic impulse responses (AIRs) which allows for fast convergence by exploiting prior knowledge about the fundamental structure of AIRs. The proposed method assumes that the variability of AIRs of an acoustic scene is confined to a low-dimensional manifold which is embedded in a high-dimensional space of possible AIR estimates. We discuss various approaches to locally approximate the AIR manifold by affine subspaces which are assumed to be tangential hyperplanes to the manifold. The validity of these model assumptions is verified for simulated data. Subsequently, we describe how the learned models can be used to improve online AIR estimates by projecting them onto an adaptively estimated subspace. The parameters determining the subspace are learned from training samples in a local neighbourhood to the current AIR estimate. This allows the system identification algorithm to benefit from preceding estimates in the acoustic scene. To assess the proximity of training data AIRs to the current AIR estimate, we introduce a probabilistic extension of the Euclidean distance which improves the performance for applications with correlated excitation signals. Furthermore, we describe how model imperfections can be tackled by a soft projection of the AIR estimates. The proposed algorithm exhibits significantly faster convergence properties in comparison to a high-performance state-of-the-art algorithm. Furthermore, we show an improved steady-state performance for speech-excited system identification scenarios suffering from high-level interfering noise and nonunique solutions.