 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-To-End Deep Learning-based Adaptation Control for Linear Acoustic Echo Cancellation
Paper and Code
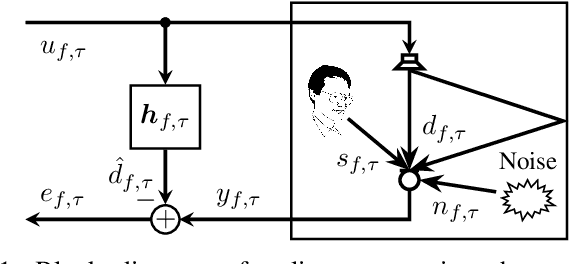
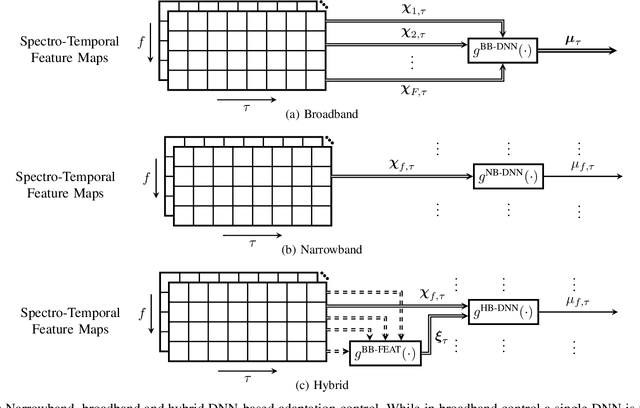
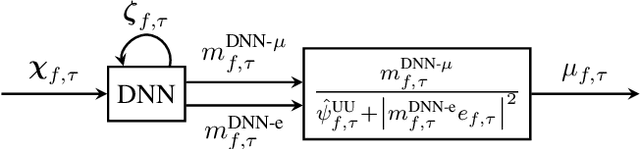
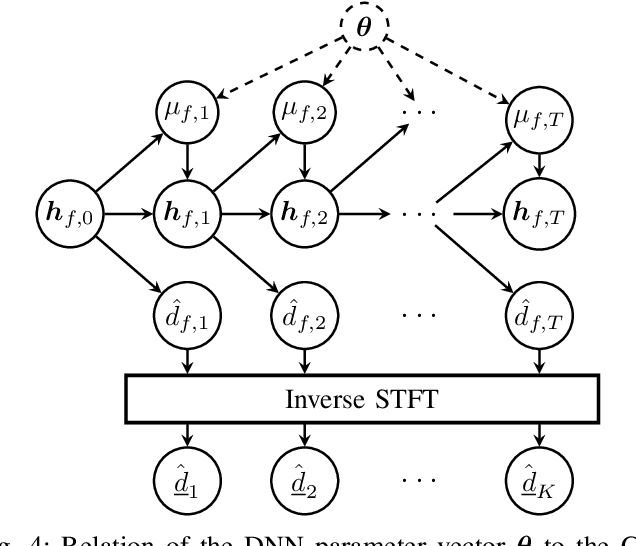
The attenuation of acoustic loudspeaker echoes remains to be one of the open challenges to achieve pleasant full-duplex hands free speech communication. In many modern signal enhancement interfaces, this problem is addressed by a linear acoustic echo canceler which subtracts a loudspeaker echo estimate from the recorded microphone signal. To obtain precise echo estimates, the parameters of the echo canceler, i.e., the filter coefficients, need to be estimated quickly and precisely from the observed loudspeaker and microphone signals. For this a sophisticated adaptation control is required to deal with high-power double-talk and rapidly track time-varying acoustic environments which are often faced with portable devices. In this paper, we address this problem by end-to-end deep learning. In particular, we suggest to infer the step-size for a least mean squares frequency-domain adaptive filter update by a Deep Neural Network (DNN). Two different step-size inference approaches are investigated. On the one hand broadband approaches, which use a single DNN to jointly infer step-sizes for all frequency bands, and on the other hand narrowband methods, which exploit individual DNNs per frequency band. The discussion of benefits and disadvantages of both approaches leads to a novel hybrid approach which shows improved echo cancellation while requiring only small DNN architectures. Furthermore, we investigate the effect of different loss functions, signal feature vectors, and DNN output layer architectures on the echo cancellation performance from which we obtain valuable insights into the general design and functionality of DNN-based adaptation control algorithms.