 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoom Impulse Response Completion Using Signal-Prediction Diffusion Models Conditioned on Simulated Early Reflections
Mar 16, 2026Room impulse responses (RIRs) are fundamental to audio data augmentation, acoustic signal processing, and immersive audio rendering. While geometric simulators such as the image source method (ISM) can efficiently generate early reflections, they lack the realism of measured RIRs due to missing acoustic wave effects. We propose a diffusion-based RIR completion method using signal-prediction conditioned on ISM-simulated direct-path and early reflections. Unlike state-of-the-art methods, our approach imposes no fixed duration constraint on the input early reflections. We further incorporate classifier-free guidance to steer generation toward a target distribution learned from physically realistic RIRs simulated with the Treble SDK. Objective evaluation demonstrates that the proposed method outperforms a state-of-the-art baseline in early RIR completion and energy decay curve reconstruction.
Robust Online Overdetermined Independent Vector Analysis Based on Bilinear Decomposition
Jan 18, 2026Online blind source separation is essential for both speech communication and human-machine interaction. Among existing approaches, overdetermined independent vector analysis (OverIVA) delivers strong performance by exploiting the statistical independence of source signals and the orthogonality between source and noise subspaces. However, when applied to large microphone arrays, the number of parameters grows rapidly, which can degrade online estimation accuracy. To overcome this challenge, we propose decomposing each long separation filter into a bilinear form of two shorter filters, thereby reducing the number of parameters. Because the two filters are closely coupled, we design an alternating iterative projection algorithm to update them in turn. Simulation results show that, with far fewer parameters, the proposed method achieves improved performance and robustness.
DeePAQ: A Perceptual Audio Quality Metric Based On Foundational Models and Weakly Supervised Learning
Oct 14, 2025This paper presents the Deep learning-based Perceptual Audio Quality metric (DeePAQ) for evaluating general audio quality. Our approach leverages metric learning together with the music foundation model MERT, guided by surrogate labels, to construct an embedding space that captures distortion intensity in general audio. To the best of our knowledge, DeePAQ is the first in the general audio quality domain to leverage weakly supervised labels and metric learning for fine-tuning a music foundation model with Low-Rank Adaptation (LoRA), a direction not yet explored by other state-of-the-art methods. We benchmark the proposed model against state-of-the-art objective audio quality metrics across listening tests spanning audio coding and source separation. Results show that our method surpasses existing metrics in detecting coding artifacts and generalizes well to unseen distortions such as source separation, highlighting its robustness and versatility.
Leveraging Discriminative Latent Representations for Conditioning GAN-Based Speech Enhancement
Aug 28, 2025Generative speech enhancement methods based on generative adversarial networks (GANs) and diffusion models have shown promising results in various speech enhancement tasks. However, their performance in very low signal-to-noise ratio (SNR) scenarios remains under-explored and limited, as these conditions pose significant challenges to both discriminative and generative state-of-the-art methods. To address this, we propose a method that leverages latent features extracted from discriminative speech enhancement models as generic conditioning features to improve GAN-based speech enhancement. The proposed method, referred to as DisCoGAN, demonstrates performance improvements over baseline models, particularly in low-SNR scenarios, while also maintaining competitive or superior performance in high-SNR conditions and on real-world recordings. We also conduct a comprehensive evaluation of conventional GAN-based architectures, including GANs trained end-to-end, GANs as a first processing stage, and post-filtering GANs, as well as discriminative models under low-SNR conditions. We show that DisCoGAN consistently outperforms existing methods. Finally, we present an ablation study that investigates the contributions of individual components within DisCoGAN and analyzes the impact of the discriminative conditioning method on overall performance.
UBGAN: Enhancing Coded Speech with Blind and Guided Bandwidth Extension
May 22, 2025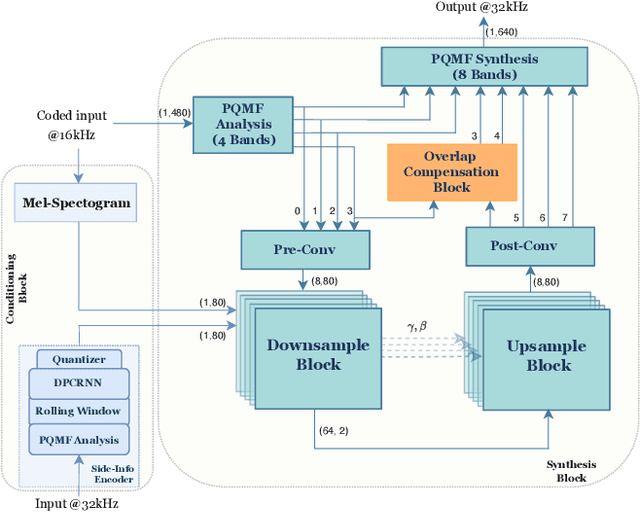
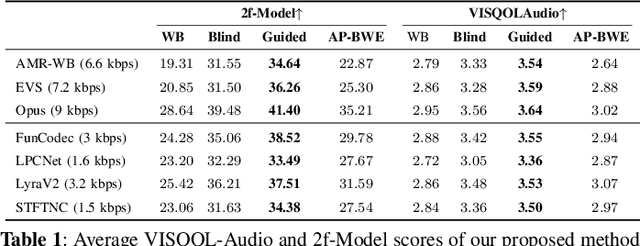
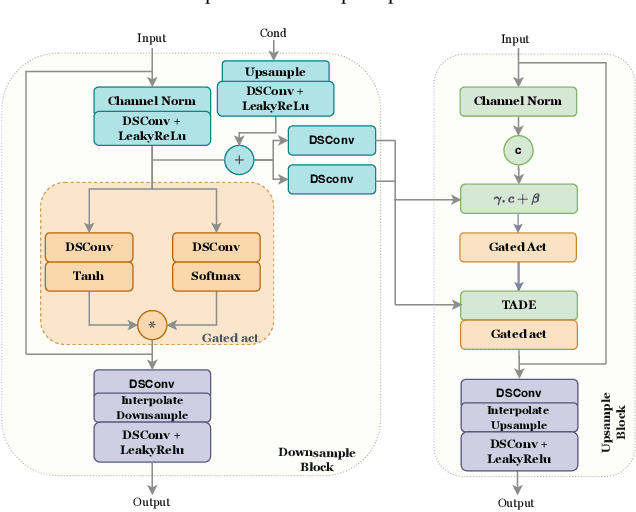

In practical application of speech codecs, a multitude of factors such as the quality of the radio connection, limiting hardware or required user experience necessitate trade-offs between achievable perceptual quality, engendered bitrate and computational complexity. Most conventional and neural speech codecs operate on wideband (WB) speech signals to achieve this compromise. To further enhance the perceptual quality of coded speech, bandwidth extension (BWE) of the transmitted speech is an attractive and popular technique in conventional speech coding. In contrast, neural speech codecs are typically trained end-to-end to a specific set of requirements and are often not easily adaptable. In particular, they are typically trained to operate at a single fixed sampling rate. With the Universal Bandwidth Extension Generative Adversarial Network (UBGAN), we propose a modular and lightweight GAN-based solution that increases the operational flexibility of a wide range of conventional and neural codecs. Our model operates in the subband domain and extends the bandwidth of WB signals from 8 kHz to 16 kHz, resulting in super-wideband (SWB) signals. We further introduce two variants, guided-UBGAN and blind-UBGAN, where the guided version transmits quantized learned representation as a side information at a very low bitrate additional to the bitrate of the codec, while blind-BWE operates without such side-information. Our subjective assessments demonstrate the advantage of UBGAN applied to WB codecs and highlight the generalization capacity of our proposed method across multiple codecs and bitrates.
On the Design of Diffusion-based Neural Speech Codecs
Apr 11, 2025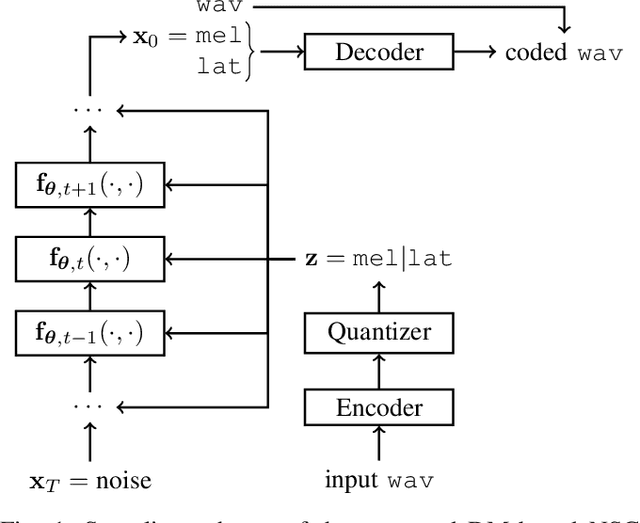
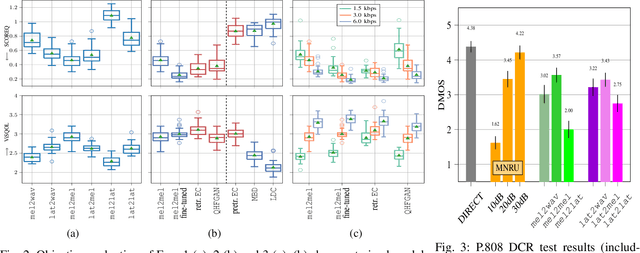
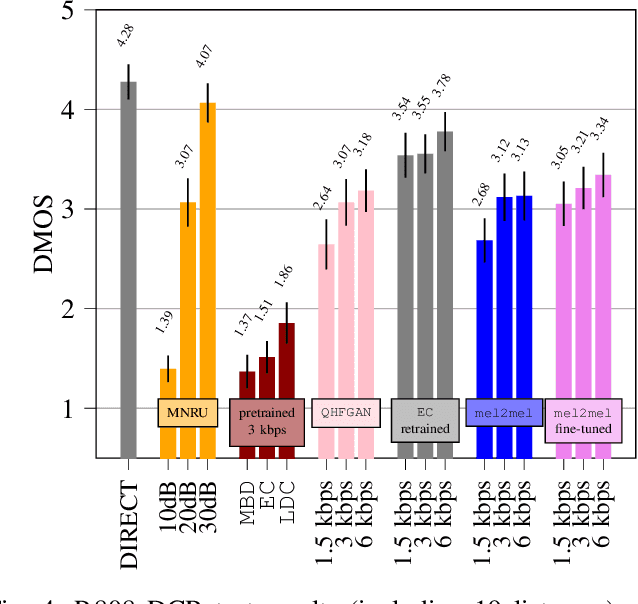

Recently, neural speech codecs (NSCs) trained as generative models have shown superior performance compared to conventional codecs at low bitrates. Although most state-of-the-art NSCs are trained as Generative Adversarial Networks (GANs), Diffusion Models (DMs), a recent class of generative models, represent a promising alternative due to their superior performance in image generation relative to GANs. Consequently, DMs have been successfully applied for audio and speech coding among various other audio generation applications. However, the design of diffusion-based NSCs has not yet been explored in a systematic way. We address this by providing a comprehensive analysis of diffusion-based NSCs divided into three contributions. First, we propose a categorization based on the conditioning and output domains of the DM. This simple conceptual framework allows us to define a design space for diffusion-based NSCs and to assign a category to existing approaches in the literature. Second, we systematically investigate unexplored designs by creating and evaluating new diffusion-based NSCs within the conceptual framework. Finally, we compare the proposed models to existing GAN and DM baselines through objective metrics and subjective listening tests.
GAN-Based Speech Enhancement for Low SNR Using Latent Feature Conditioning
Oct 17, 2024



Enhancing speech quality under adverse SNR conditions remains a significant challenge for discriminative deep neural network (DNN)-based approaches. In this work, we propose DisCoGAN, which is a time-frequency-domain generative adversarial network (GAN) conditioned by the latent features of a discriminative model pre-trained for speech enhancement in low SNR scenarios. Our proposed method achieves superior performance compared to state-of-the-arts discriminative methods and also surpasses end-to-end (E2E) trained GAN models. We also investigate the impact of various configurations for conditioning the proposed GAN model with the discriminative model and assess their influence on enhancing speech quality
Comparative Analysis Of Discriminative Deep Learning-Based Noise Reduction Methods In Low SNR Scenarios
Aug 26, 2024



In this study, we conduct a comparative analysis of deep learning-based noise reduction methods in low signal-to-noise ratio (SNR) scenarios. Our investigation primarily focuses on five key aspects: The impact of training data, the influence of various loss functions, the effectiveness of direct and indirect speech estimation techniques, the efficacy of masking, mapping, and deep filtering methodologies, and the exploration of different model capacities on noise reduction performance and speech quality. Through comprehensive experimentation, we provide insights into the strengths, weaknesses, and applicability of these methods in low SNR environments. The findings derived from our analysis are intended to assist both researchers and practitioners in selecting better techniques tailored to their specific applications within the domain of low SNR noise reduction.
Blind Acoustic Parameter Estimation Through Task-Agnostic Embeddings Using Latent Approximations
Jul 29, 2024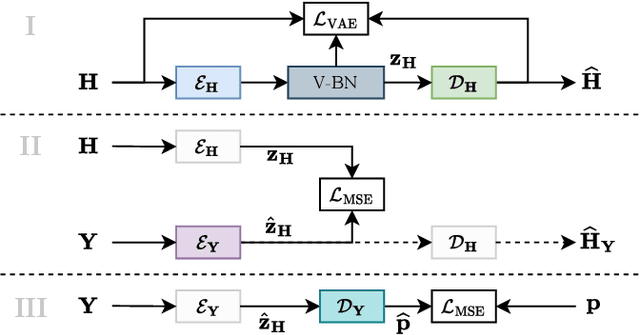
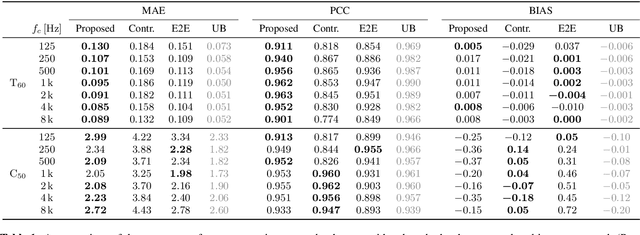
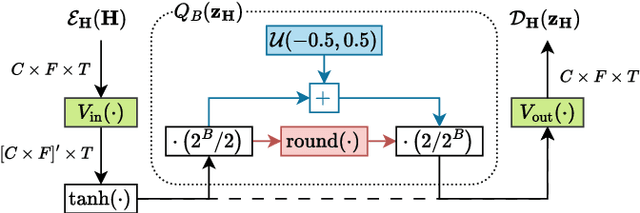
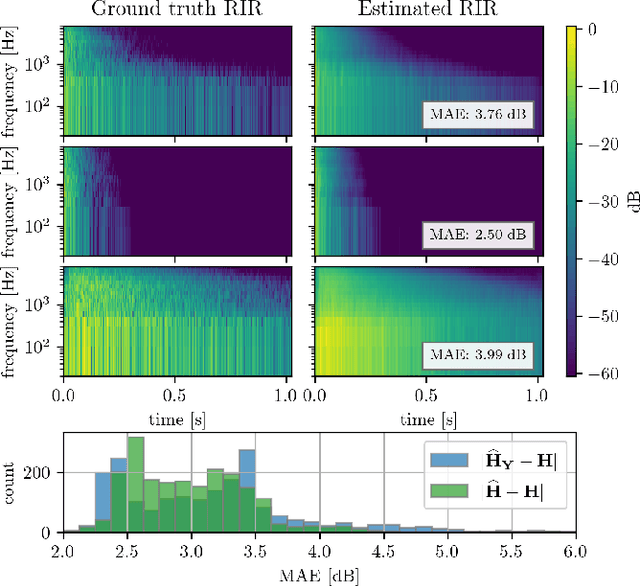
We present a method for blind acoustic parameter estimation from single-channel reverberant speech. The method is structured into three stages. In the first stage, a variational auto-encoder is trained to extract latent representations of acoustic impulse responses represented as mel-spectrograms. In the second stage, a separate speech encoder is trained to estimate low-dimensional representations from short segments of reverberant speech. Finally, the pre-trained speech encoder is combined with a small regression model and evaluated on two parameter regression tasks. Experimentally, the proposed method is shown to outperform a fully end-to-end trained baseline model.
On Improving Error Resilience of Neural End-to-End Speech Coders
Jun 13, 2024Error resilient tools like Packet Loss Concealment (PLC) and Forward Error Correction (FEC) are essential to maintain a reliable speech communication for applications like Voice over Internet Protocol (VoIP), where packets are frequently delayed and lost. In recent times, end-to-end neural speech codecs have seen a significant rise, due to their ability to transmit speech signal at low bitrates but few considerations were made about their error resilience in a real system. Recently introduced Neural End-to-End Speech Codec (NESC) can reproduce high quality natural speech at low bitrates. We extend its robustness to packet losses by adding a low complexity network to predict the codebook indices in latent space. Furthermore, we propose a method to add an in-band FEC at an additional bitrate of 0.8 kbps. Both subjective and objective assessment indicate the effectiveness of proposed methods, and demonstrate that coupling PLC and FEC provide significant robustness against packet losses.