 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowMAC: Conditional Flow Matching for Audio Coding at Low Bit Rates
Sep 26, 2024This paper introduces FlowMAC, a novel neural audio codec for high-quality general audio compression at low bit rates based on conditional flow matching (CFM). FlowMAC jointly learns a mel spectrogram encoder, quantizer and decoder. At inference time the decoder integrates a continuous normalizing flow via an ODE solver to generate a high-quality mel spectrogram. This is the first time that a CFM-based approach is applied to general audio coding, enabling a scalable, simple and memory efficient training. Our subjective evaluations show that FlowMAC at 3 kbps achieves similar quality as state-of-the-art GAN-based and DDPM-based neural audio codecs at double the bit rate. Moreover, FlowMAC offers a tunable inference pipeline, which permits to trade off complexity and quality. This enables real-time coding on CPU, while maintaining high perceptual quality.
On Improving Error Resilience of Neural End-to-End Speech Coders
Jun 13, 2024Error resilient tools like Packet Loss Concealment (PLC) and Forward Error Correction (FEC) are essential to maintain a reliable speech communication for applications like Voice over Internet Protocol (VoIP), where packets are frequently delayed and lost. In recent times, end-to-end neural speech codecs have seen a significant rise, due to their ability to transmit speech signal at low bitrates but few considerations were made about their error resilience in a real system. Recently introduced Neural End-to-End Speech Codec (NESC) can reproduce high quality natural speech at low bitrates. We extend its robustness to packet losses by adding a low complexity network to predict the codebook indices in latent space. Furthermore, we propose a method to add an in-band FEC at an additional bitrate of 0.8 kbps. Both subjective and objective assessment indicate the effectiveness of proposed methods, and demonstrate that coupling PLC and FEC provide significant robustness against packet losses.
Simple and Efficient Quantization Techniques for Neural Speech Coding
May 14, 2024Neural audio coding has emerged as a vivid research direction by promising good audio quality at very low bitrates unachievable by classical coding techniques. Here, end-to-end trainable autoencoder-like models represent the state of the art, where a discrete representation in the bottleneck of the autoencoder has to be learned that allows for efficient transmission of the input audio signal. This discrete representation is typically generated by applying a quantizer to the output of the neural encoder. In almost all state-of-the-art neural audio coding approaches, this quantizer is realized as a Vector Quantizer (VQ) and a lot of effort has been spent to alleviate drawbacks of this quantization technique when used together with a neural audio coder. In this paper, we propose simple alternatives to VQ, which are based on projected Scalar Quantization (SQ). These quantization techniques do not need any additional losses, scheduling parameters or codebook storage thereby simplifying the training of neural audio codecs. Furthermore, we propose a new causal network architecture for neural speech coding that shows good performance at very low computational complexity.
NESC: Robust Neural End-2-End Speech Coding with GANs
Jul 07, 2022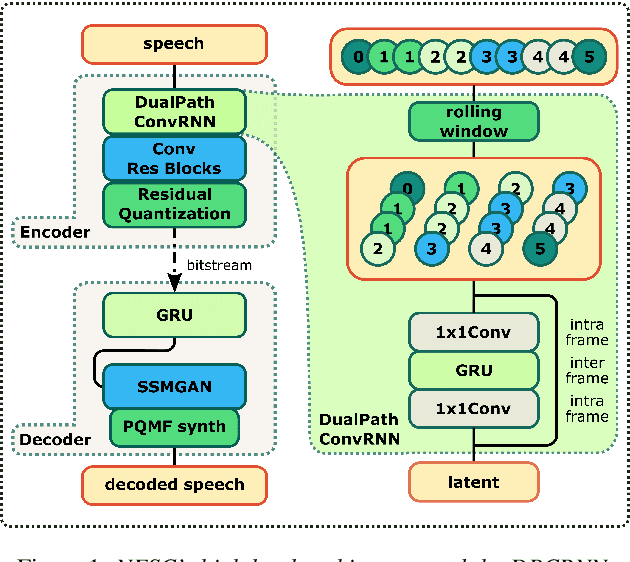
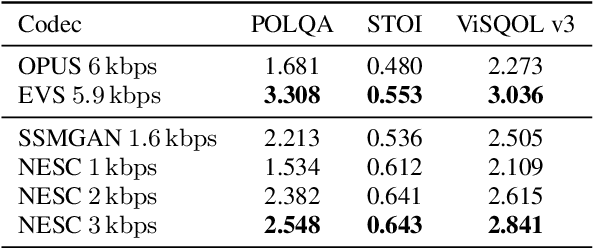
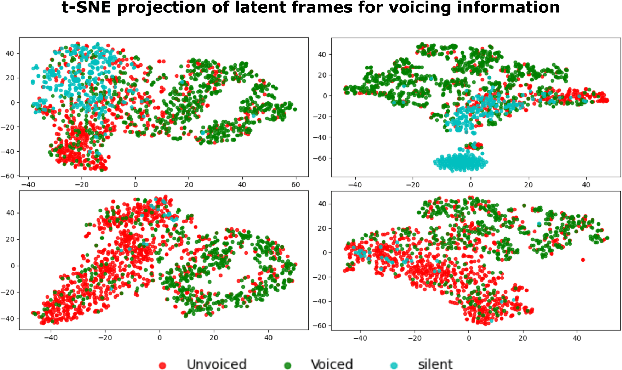
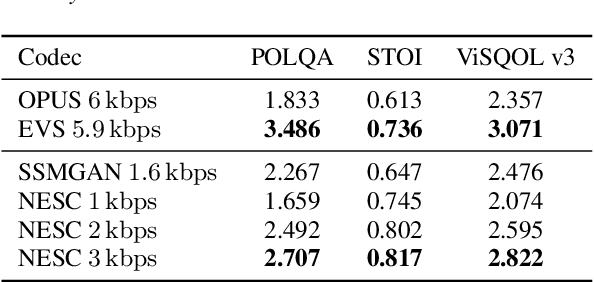
Neural networks have proven to be a formidable tool to tackle the problem of speech coding at very low bit rates. However, the design of a neural coder that can be operated robustly under real-world conditions remains a major challenge. Therefore, we present Neural End-2-End Speech Codec (NESC) a robust, scalable end-to-end neural speech codec for high-quality wideband speech coding at 3 kbps. The encoder uses a new architecture configuration, which relies on our proposed Dual-PathConvRNN (DPCRNN) layer, while the decoder architecture is based on our previous work Streamwise-StyleMelGAN. Our subjective listening tests on clean and noisy speech show that NESC is particularly robust to unseen conditions and signal perturbations.