 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Strategies for Modality Dropout Resilient Multi-Modal Target Speaker Extraction
Jul 09, 2025The primary goal of multi-modal TSE (MTSE) is to extract a target speaker from a speech mixture using complementary information from different modalities, such as audio enrolment and visual feeds corresponding to the target speaker. MTSE systems are expected to perform well even when one of the modalities is unavailable. In practice, the systems often suffer from modality dominance, where one of the modalities outweighs the others, thereby limiting robustness. Our study investigates training strategies and the effect of architectural choices, particularly the normalization layers, in yielding a robust MTSE system in both non-causal and causal configurations. In particular, we propose the use of modality dropout training (MDT) as a superior strategy to standard and multi-task training (MTT) strategies. Experiments conducted on two-speaker mixtures from the LRS3 dataset show the MDT strategy to be effective irrespective of the employed normalization layer. In contrast, the models trained with the standard and MTT strategies are susceptible to modality dominance, and their performance depends on the chosen normalization layer. Additionally, we demonstrate that the system trained with MDT strategy is robust to using extracted speech as the enrollment signal, highlighting its potential applicability in scenarios where the target speaker is not enrolled.
UBGAN: Enhancing Coded Speech with Blind and Guided Bandwidth Extension
May 22, 2025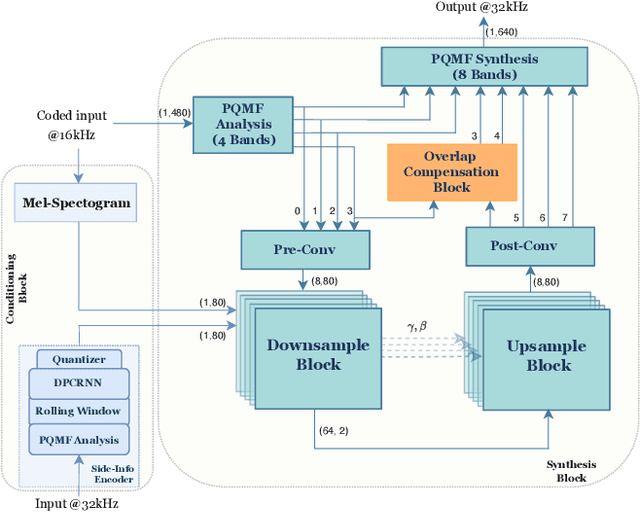
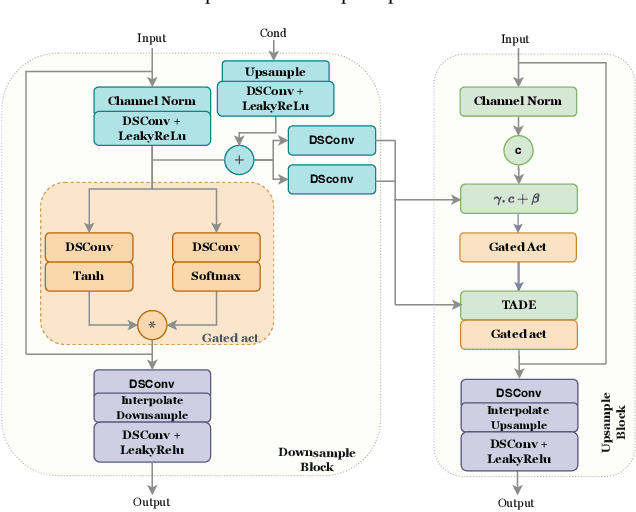

In practical application of speech codecs, a multitude of factors such as the quality of the radio connection, limiting hardware or required user experience necessitate trade-offs between achievable perceptual quality, engendered bitrate and computational complexity. Most conventional and neural speech codecs operate on wideband (WB) speech signals to achieve this compromise. To further enhance the perceptual quality of coded speech, bandwidth extension (BWE) of the transmitted speech is an attractive and popular technique in conventional speech coding. In contrast, neural speech codecs are typically trained end-to-end to a specific set of requirements and are often not easily adaptable. In particular, they are typically trained to operate at a single fixed sampling rate. With the Universal Bandwidth Extension Generative Adversarial Network (UBGAN), we propose a modular and lightweight GAN-based solution that increases the operational flexibility of a wide range of conventional and neural codecs. Our model operates in the subband domain and extends the bandwidth of WB signals from 8 kHz to 16 kHz, resulting in super-wideband (SWB) signals. We further introduce two variants, guided-UBGAN and blind-UBGAN, where the guided version transmits quantized learned representation as a side information at a very low bitrate additional to the bitrate of the codec, while blind-BWE operates without such side-information. Our subjective assessments demonstrate the advantage of UBGAN applied to WB codecs and highlight the generalization capacity of our proposed method across multiple codecs and bitrates.
On Improving Error Resilience of Neural End-to-End Speech Coders
Jun 13, 2024Error resilient tools like Packet Loss Concealment (PLC) and Forward Error Correction (FEC) are essential to maintain a reliable speech communication for applications like Voice over Internet Protocol (VoIP), where packets are frequently delayed and lost. In recent times, end-to-end neural speech codecs have seen a significant rise, due to their ability to transmit speech signal at low bitrates but few considerations were made about their error resilience in a real system. Recently introduced Neural End-to-End Speech Codec (NESC) can reproduce high quality natural speech at low bitrates. We extend its robustness to packet losses by adding a low complexity network to predict the codebook indices in latent space. Furthermore, we propose a method to add an in-band FEC at an additional bitrate of 0.8 kbps. Both subjective and objective assessment indicate the effectiveness of proposed methods, and demonstrate that coupling PLC and FEC provide significant robustness against packet losses.
NESC: Robust Neural End-2-End Speech Coding with GANs
Jul 07, 2022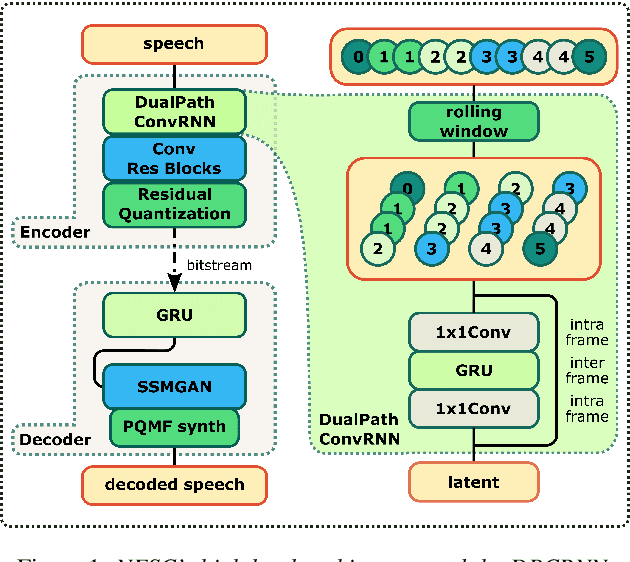
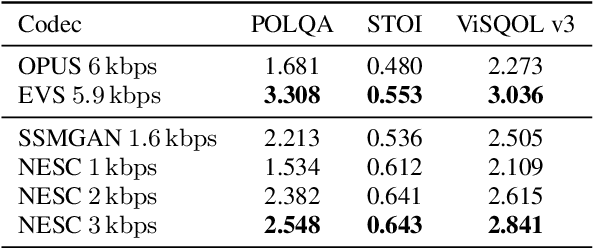
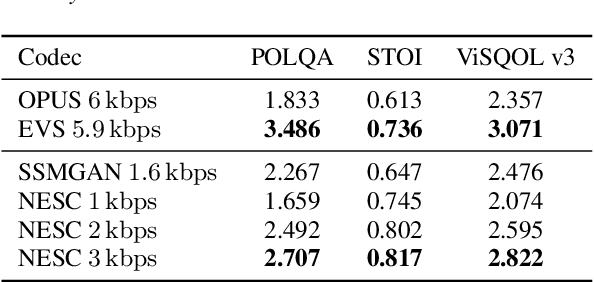
Neural networks have proven to be a formidable tool to tackle the problem of speech coding at very low bit rates. However, the design of a neural coder that can be operated robustly under real-world conditions remains a major challenge. Therefore, we present Neural End-2-End Speech Codec (NESC) a robust, scalable end-to-end neural speech codec for high-quality wideband speech coding at 3 kbps. The encoder uses a new architecture configuration, which relies on our proposed Dual-PathConvRNN (DPCRNN) layer, while the decoder architecture is based on our previous work Streamwise-StyleMelGAN. Our subjective listening tests on clean and noisy speech show that NESC is particularly robust to unseen conditions and signal perturbations.
PostGAN: A GAN-Based Post-Processor to Enhance the Quality of Coded Speech
Jan 31, 2022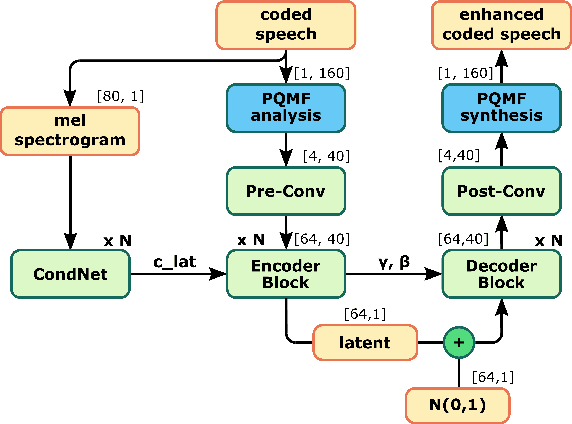
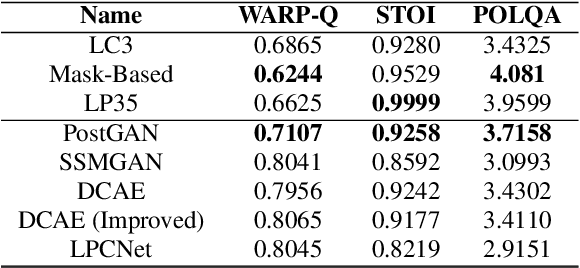
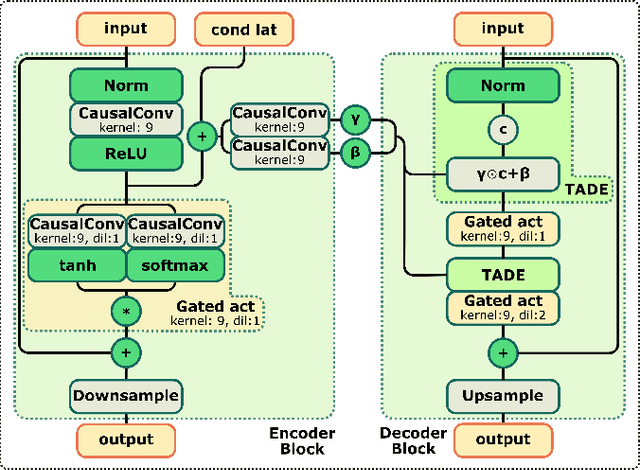
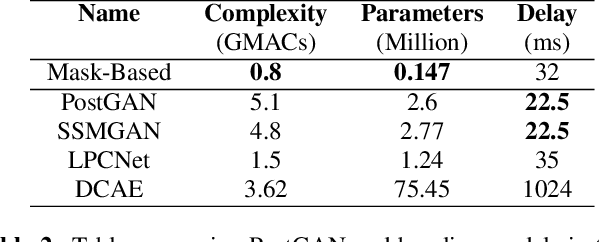
The quality of speech coded by transform coding is affected by various artefacts especially when bitrates to quantize the frequency components become too low. In order to mitigate these coding artefacts and enhance the quality of coded speech, a post-processor that relies on a-priori information transmitted from the encoder is traditionally employed at the decoder side. In recent years, several data-driven post-postprocessors have been proposed which were shown to outperform traditional approaches. In this paper, we propose PostGAN, a GAN-based neural post-processor that operates in the sub-band domain and relies on the U-Net architecture and a learned affine transform. It has been tested on the recently standardized low-complexity, low-delay bluetooth codec (LC3) for wideband speech at the lowest bitrate (16 kbit/s). Subjective evaluations and objective scores show that the newly introduced post-processor surpasses previously published methods and can improve the quality of coded speech by around 20 MUSHRA points.
A DNN Based Post-Filter to Enhance the Quality of Coded Speech in MDCT Domain
Jan 28, 2022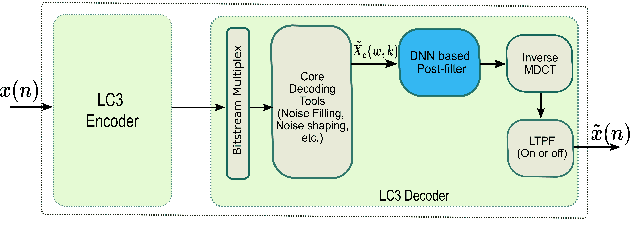

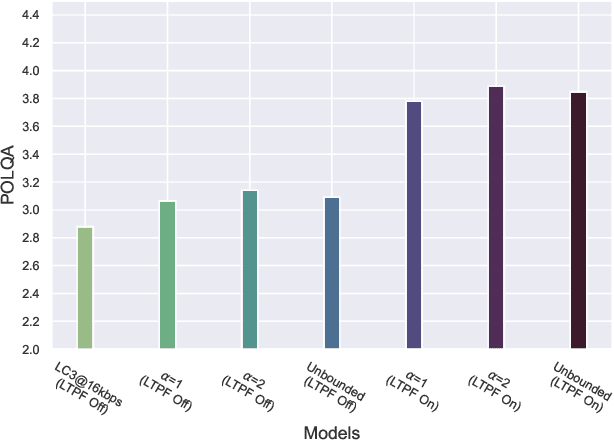
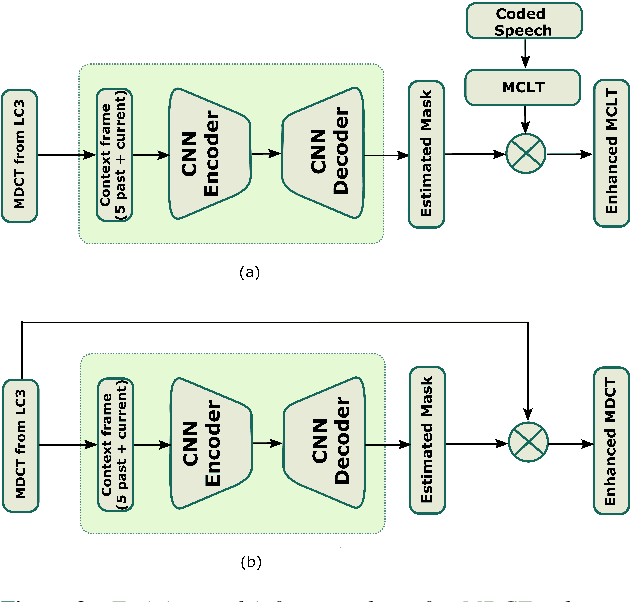
Frequency domain processing, and in particular the use of Modified Discrete Cosine Transform (MDCT), is the most widespread approach to audio coding. However, at low bitrates, audio quality, especially for speech, degrades drastically due to the lack of available bits to directly code the transform coefficients. Traditionally, post-filtering has been used to mitigate artefacts in the coded speech by exploiting a-priori information of the source and extra transmitted parameters. Recently, data-driven post-filters have shown better results, but at the cost of significant additional complexity and delay. In this work, we propose a mask-based post-filter operating directly in MDCT domain of the codec, inducing no extra delay. The real-valued mask is applied to the quantized MDCT coefficients and is estimated from a relatively lightweight convolutional encoder-decoder network. Our solution is tested on the recently standardized low-delay, low-complexity codec (LC3) at lowest possible bitrate of 16 kbps. Objective and subjective assessments clearly show the advantage of this approach over the conventional post-filter, with an average improvement of 10 MUSHRA points over the LC3 coded speech.
A Streamwise GAN Vocoder for Wideband Speech Coding at Very Low Bit Rate
Aug 09, 2021
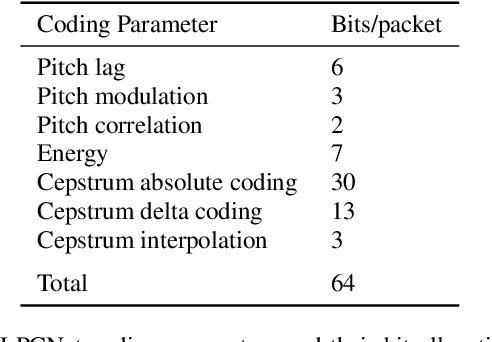
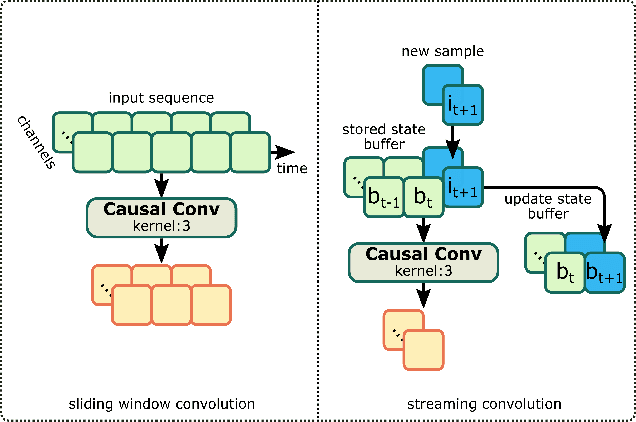
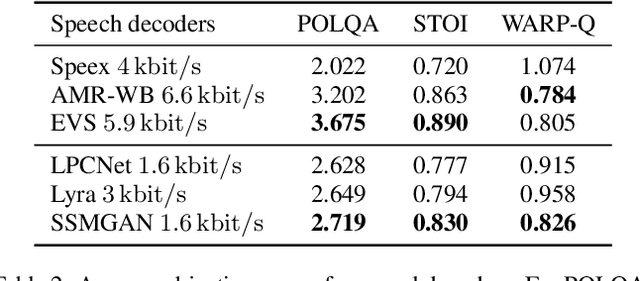
Recently, GAN vocoders have seen rapid progress in speech synthesis, starting to outperform autoregressive models in perceptual quality with much higher generation speed. However, autoregressive vocoders are still the common choice for neural generation of speech signals coded at very low bit rates. In this paper, we present a GAN vocoder which is able to generate wideband speech waveforms from parameters coded at 1.6 kbit/s. The proposed model is a modified version of the StyleMelGAN vocoder that can run in frame-by-frame manner, making it suitable for streaming applications. The experimental results show that the proposed model significantly outperforms prior autoregressive vocoders like LPCNet for very low bit rate speech coding, with computational complexity of about 5 GMACs, providing a new state of the art in this domain. Moreover, this streamwise adversarial vocoder delivers quality competitive to advanced speech codecs such as EVS at 5.9 kbit/s on clean speech, which motivates further usage of feed-forward fully-convolutional models for low bit rate speech coding.
Enhancement Of Coded Speech Using a Mask-Based Post-Filter
Oct 12, 2020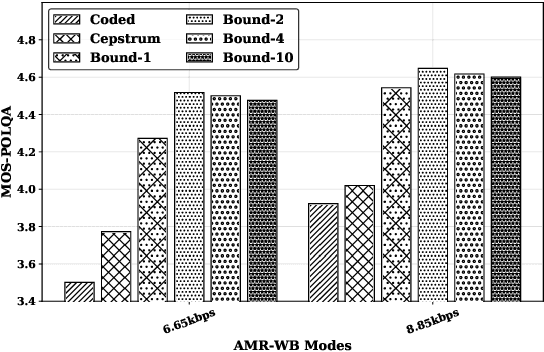
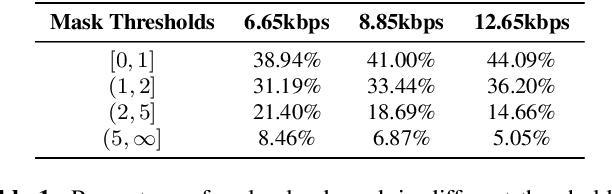

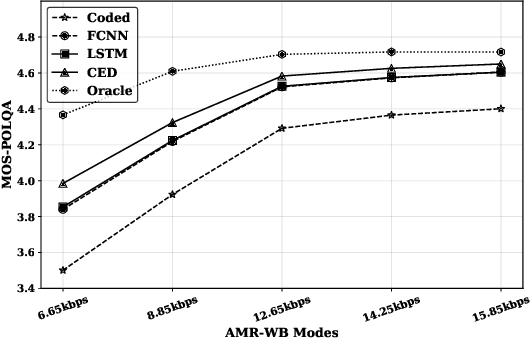
The quality of speech codecs deteriorates at low bitrates due to high quantization noise. A post-filter is generally employed to enhance the quality of the coded speech. In this paper, a data-driven post-filter relying on masking in the time-frequency domain is proposed. A fully connected neural network (FCNN), a convolutional encoder-decoder (CED) network and a long short-term memory (LSTM) network are implemeted to estimate a real-valued mask per time-frequency bin. The proposed models were tested on the five lowest operating modes (6.65 kbps-15.85 kbps) of the Adaptive Multi-Rate Wideband codec (AMR-WB). Both objective and subjective evaluations confirm the enhancement of the coded speech and also show the superiority of the mask-based neural network system over a conventional heuristic post-filter used in the standard like ITU-T G.718.