 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA lightweight and robust method for blind wideband-to-fullband extension of speech
Dec 16, 2024


Reducing the bandwidth of speech is common practice in resource constrained environments like low-bandwidth speech transmission or low-complexity vocoding. We propose a lightweight and robust method for extending the bandwidth of wideband speech signals that is inspired by classical methods developed in the speech coding context. The resulting model has just $\sim 370$~K parameters and a complexity of ~140 MFLOPS (or ~70 MMACS). With a frame size of 10 ms and a lookahead of just 0.27 ms the model is well-suited for common wideband speech codecs. We evaluate the model's robustness by pairing it with the Opus SILK speech codec (1.5 release) and verify in a P.808 DCR listening test that it significantly improves quality from 6 to 12 kb/s. We also demonstrate that Opus 1.5 together with the proposed bandwidth extension at 9 kb/s meets the quality of 3GPP EVS at 9.6 kb/s and that of Opus 1.4 at 18 kb/s showing that the blind bandwidth extension can meet the quality of classical guided bandwidth extensions.
Very Low Complexity Speech Synthesis Using Framewise Autoregressive GAN (FARGAN) with Pitch Prediction
May 31, 2024Neural vocoders are now being used in a wide range of speech processing applications. In many of those applications, the vocoder can be the most complex component, so finding lower complexity algorithms can lead to significant practical benefits. In this work, we propose FARGAN, an autoregressive vocoder that takes advantage of long-term pitch prediction to synthesize high-quality speech in small subframes, without the need for teacher-forcing. Experimental results show that the proposed 600~MFLOPS FARGAN vocoder can achieve both higher quality and lower complexity than existing low-complexity vocoders. The quality even matches that of existing higher-complexity vocoders.
NoLACE: Improving Low-Complexity Speech Codec Enhancement Through Adaptive Temporal Shaping
Sep 25, 2023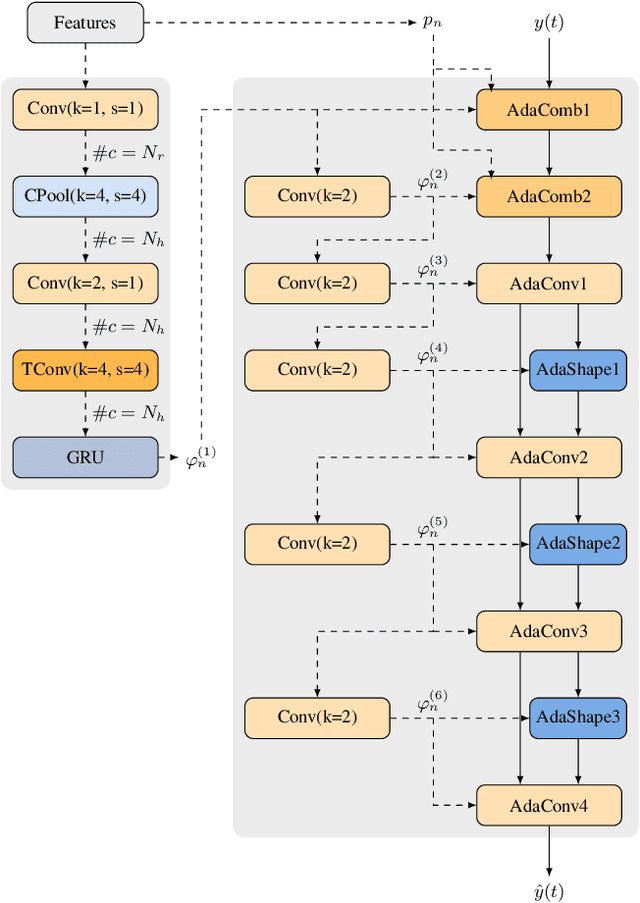
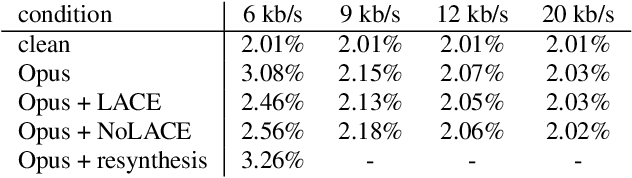
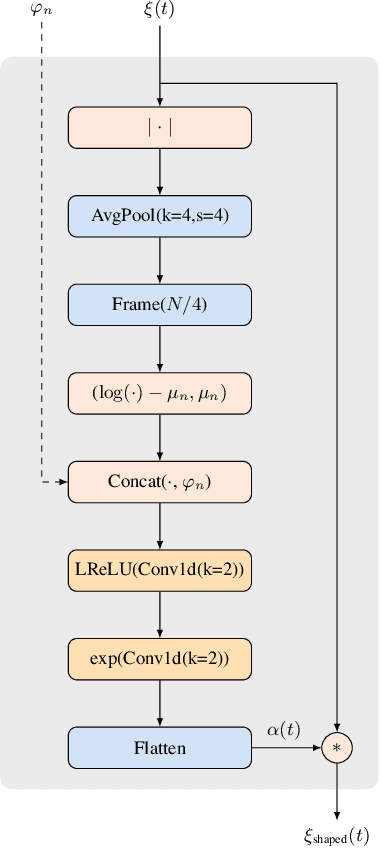
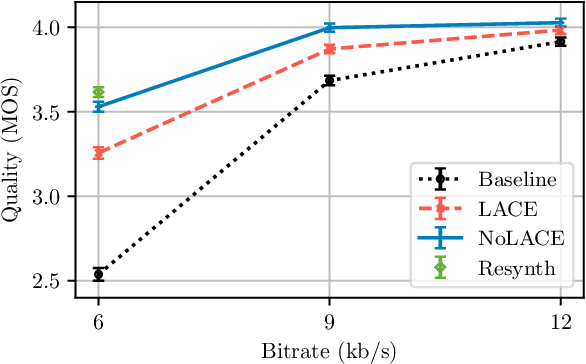
Speech codec enhancement methods are designed to remove distortions added by speech codecs. While classical methods are very low in complexity and add zero delay, their effectiveness is rather limited. Compared to that, DNN-based methods deliver higher quality but they are typically high in complexity and/or require delay. The recently proposed Linear Adaptive Coding Enhancer (LACE) addresses this problem by combining DNNs with classical long-term/short-term postfiltering resulting in a causal low-complexity model. A short-coming of the LACE model is, however, that quality quickly saturates when the model size is scaled up. To mitigate this problem, we propose a novel adatpive temporal shaping module that adds high temporal resolution to the LACE model resulting in the Non-Linear Adaptive Coding Enhancer (NoLACE). We adapt NoLACE to enhance the Opus codec and show that NoLACE significantly outperforms both the Opus baseline and an enlarged LACE model at 6, 9 and 12 kb/s. We also show that LACE and NoLACE are well-behaved when used with an ASR system.
LACE: A light-weight, causal model for enhancing coded speech through adaptive convolutions
Jul 13, 2023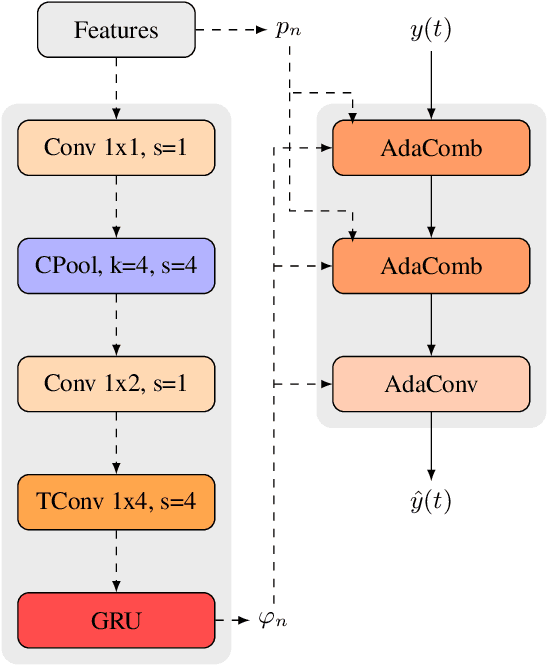



Classical speech coding uses low-complexity postfilters with zero lookahead to enhance the quality of coded speech, but their effectiveness is limited by their simplicity. Deep Neural Networks (DNNs) can be much more effective, but require high complexity and model size, or added delay. We propose a DNN model that generates classical filter kernels on a per-frame basis with a model of just 300~K parameters and 100~MFLOPS complexity, which is a practical complexity for desktop or mobile device CPUs. The lack of added delay allows it to be integrated into the Opus codec, and we demonstrate that it enables effective wideband encoding for bitrates down to 6 kb/s.
Low-Bitrate Redundancy Coding of Speech Using a Rate-Distortion-Optimized Variational Autoencoder
Dec 08, 2022Robustness to packet loss is one of the main ongoing challenges in real-time speech communication. Deep packet loss concealment (PLC) techniques have recently demonstrated improved quality compared to traditional PLC. Despite that, all PLC techniques hit fundamental limitations when too much acoustic information is lost. To reduce losses in the first place, data is commonly sent multiple times using various redundancy mechanisms. We propose a neural speech coder specifically optimized to transmit a large amount of overlapping redundancy at a very low bitrate, up to 50x redundancy using less than 32~kb/s. Results show that the proposed redundancy is more effective than the existing Opus codec redundancy, and that the two can be combined for even greater robustness.
Framewise WaveGAN: High Speed Adversarial Vocoder in Time Domain with Very Low Computational Complexity
Dec 08, 2022GAN vocoders are currently one of the state-of-the-art methods for building high-quality neural waveform generative models. However, most of their architectures require dozens of billion floating-point operations per second (GFLOPS) to generate speech waveforms in samplewise manner. This makes GAN vocoders still challenging to run on normal CPUs without accelerators or parallel computers. In this work, we propose a new architecture for GAN vocoders that mainly depends on recurrent and fully-connected networks to directly generate the time domain signal in framewise manner. This results in considerable reduction of the computational cost and enables very fast generation on both GPUs and low-complexity CPUs. Experimental results show that our Framewise WaveGAN vocoder achieves significantly higher quality than auto-regressive maximum-likelihood vocoders such as LPCNet at a very low complexity of 1.2 GFLOPS. This makes GAN vocoders more practical on edge and low-power devices.
A Streamwise GAN Vocoder for Wideband Speech Coding at Very Low Bit Rate
Aug 09, 2021
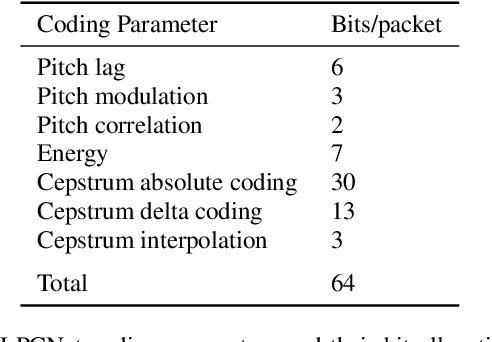
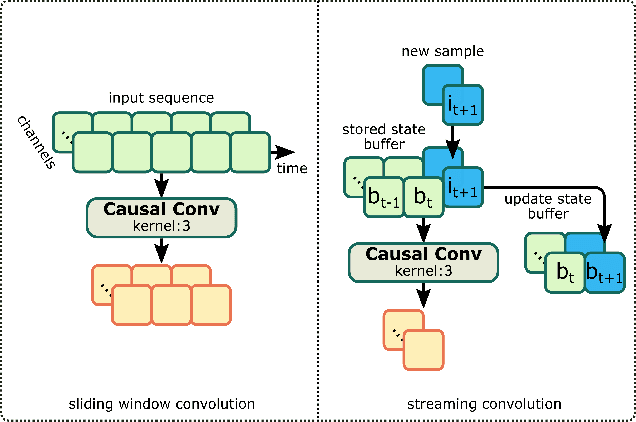
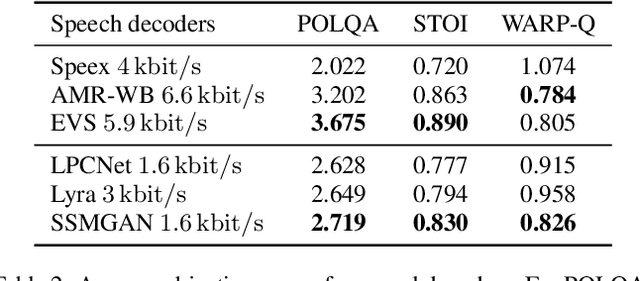
Recently, GAN vocoders have seen rapid progress in speech synthesis, starting to outperform autoregressive models in perceptual quality with much higher generation speed. However, autoregressive vocoders are still the common choice for neural generation of speech signals coded at very low bit rates. In this paper, we present a GAN vocoder which is able to generate wideband speech waveforms from parameters coded at 1.6 kbit/s. The proposed model is a modified version of the StyleMelGAN vocoder that can run in frame-by-frame manner, making it suitable for streaming applications. The experimental results show that the proposed model significantly outperforms prior autoregressive vocoders like LPCNet for very low bit rate speech coding, with computational complexity of about 5 GMACs, providing a new state of the art in this domain. Moreover, this streamwise adversarial vocoder delivers quality competitive to advanced speech codecs such as EVS at 5.9 kbit/s on clean speech, which motivates further usage of feed-forward fully-convolutional models for low bit rate speech coding.