 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro Language Models Enable Instant Responses
Apr 21, 2026Edge devices such as smartwatches and smart glasses cannot continuously run even the smallest 100M-1B parameter language models due to power and compute constraints, yet cloud inference introduces multi-second latencies that break the illusion of a responsive assistant. We introduce micro language models ($μ$LMs): ultra-compact models (8M-30M parameters) that instantly generate the first 4-8 words of a contextually grounded response on-device, while a cloud model completes it; thus, masking the cloud latency. We show that useful language generation survives at this extreme scale with our models matching several 70M-256M-class existing models. We design a collaborative generation framework that reframes the cloud model as a continuator rather than a respondent, achieving seamless mid-sentence handoffs and structured graceful recovery via three error correction methods when the local opener goes wrong. Empirical results show that $μ$LMs can initiate responses that larger models complete seamlessly, demonstrating that orders-of-magnitude asymmetric collaboration is achievable and unlocking responsive AI for extremely resource-constrained devices. The model checkpoint and demo are available at https://github.com/Sensente/micro_language_model_swen_project.
A Hierarchical End-of-Turn Model with Primary Speaker Segmentation for Real-Time Conversational AI
Mar 10, 2026We present a real-time front-end for voice-based conversational AI to enable natural turn-taking in two-speaker scenarios by combining primary speaker segmentation with hierarchical End-of-Turn (EOT) detection. To operate robustly in multi-speaker environments, the system continuously identifies and tracks the primary user, ensuring that downstream EOT decisions are not confounded by background conversations. The tracked activity segments are fed to a hierarchical, causal EOT model that predicts the immediate conversational state by independently analyzing per-speaker speech features from both the primary speaker and the bot. Simultaneously, the model anticipates near-future states ($t{+}10/20/30$\,ms) through probabilistic predictions that are aware of the conversation partner's speech. Task-specific knowledge distillation compresses wav2vec~2.0 representations (768\,D) into a compact MFCC-based student (32\,D) for efficient deployment. The system achieves 82\% multi-class frame-level F1 and 70.6\% F1 on Backchannel detection, with 69.3\% F1 on a binary Final vs.\ Others task. On an end-to-end turn-detection benchmark, our model reaches 87.7\% recall vs.\ 58.9\% for Smart Turn~v3 while keeping a median detection latency of 36\,ms versus 800--1300\,ms. Despite using only 1.14\,M parameters, the proposed model matches or exceeds transformer-based baselines while substantially reducing latency and memory footprint, making it suitable for edge deployment.
Sound Source Separation Using Latent Variational Block-Wise Disentanglement
Feb 08, 2024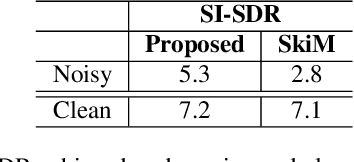
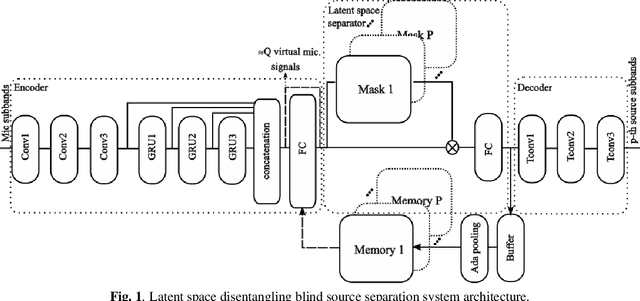
While neural network approaches have made significant strides in resolving classical signal processing problems, it is often the case that hybrid approaches that draw insight from both signal processing and neural networks produce more complete solutions. In this paper, we present a hybrid classical digital signal processing/deep neural network (DSP/DNN) approach to source separation (SS) highlighting the theoretical link between variational autoencoder and classical approaches to SS. We propose a system that transforms the single channel under-determined SS task to an equivalent multichannel over-determined SS problem in a properly designed latent space. The separation task in the latent space is treated as finding a variational block-wise disentangled representation of the mixture. We show empirically, that the design choices and the variational formulation of the task at hand motivated by the classical signal processing theoretical results lead to robustness to unseen out-of-distribution data and reduction of the overfitting risk. To address the resulting permutation issue we explicitly incorporate a novel differentiable permutation loss function and augment the model with a memory mechanism to keep track of the statistics of the individual sources.
Real-time Stereo Speech Enhancement with Spatial-Cue Preservation based on Dual-Path Structure
Feb 01, 2024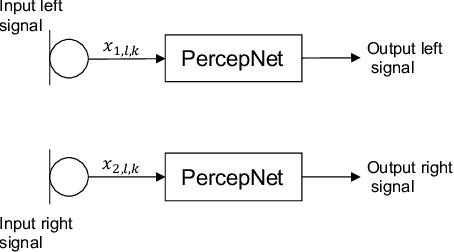



We introduce a real-time, multichannel speech enhancement algorithm which maintains the spatial cues of stereo recordings including two speech sources. Recognizing that each source has unique spatial information, our method utilizes a dual-path structure, ensuring the spatial cues remain unaffected during enhancement by applying source-specific common-band gain. This method also seamlessly integrates pretrained monaural speech enhancement, eliminating the need for retraining on stereo inputs. Source separation from stereo mixtures is achieved via spatial beamforming, with the steering vector for each source being adaptively updated using post-enhancement output signal. This ensures accurate tracking of the spatial information. The final stereo output is derived by merging the spatial images of the enhanced sources, with its efficacy not heavily reliant on the separation performance of the beamforming. The algorithm runs in real-time on 10-ms frames with a 40 ms of look-ahead. Evaluations reveal its effectiveness in enhancing speech and preserving spatial cues in both fully and sparsely overlapped mixtures.
Neural Harmonium: An Interpretable Deep Structure for Nonlinear Dynamic System Identification with Application to Audio Processing
Oct 10, 2023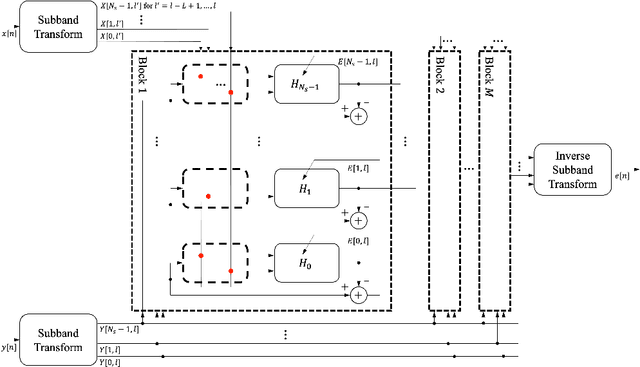
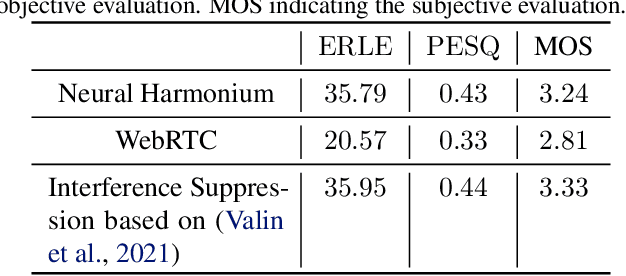
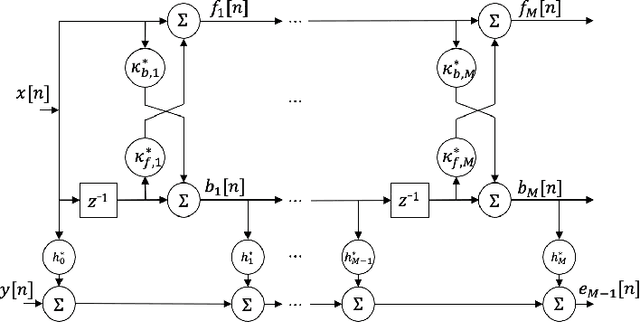

Improving the interpretability of deep neural networks has recently gained increased attention, especially when the power of deep learning is leveraged to solve problems in physics. Interpretability helps us understand a model's ability to generalize and reveal its limitations. In this paper, we introduce a causal interpretable deep structure for modeling dynamic systems. Our proposed model makes use of the harmonic analysis by modeling the system in a time-frequency domain while maintaining high temporal and spectral resolution. Moreover, the model is built in an order recursive manner which allows for fast, robust, and exact second order optimization without the need for an explicit Hessian calculation. To circumvent the resulting high dimensionality of the building blocks of our system, a neural network is designed to identify the frequency interdependencies. The proposed model is illustrated and validated on nonlinear system identification problems as required for audio signal processing tasks. Crowd-sourced experimentation contrasting the performance of the proposed approach to other state-of-the-art solutions on an acoustic echo cancellation scenario confirms the effectiveness of our method for real-life applications.
NoLACE: Improving Low-Complexity Speech Codec Enhancement Through Adaptive Temporal Shaping
Sep 25, 2023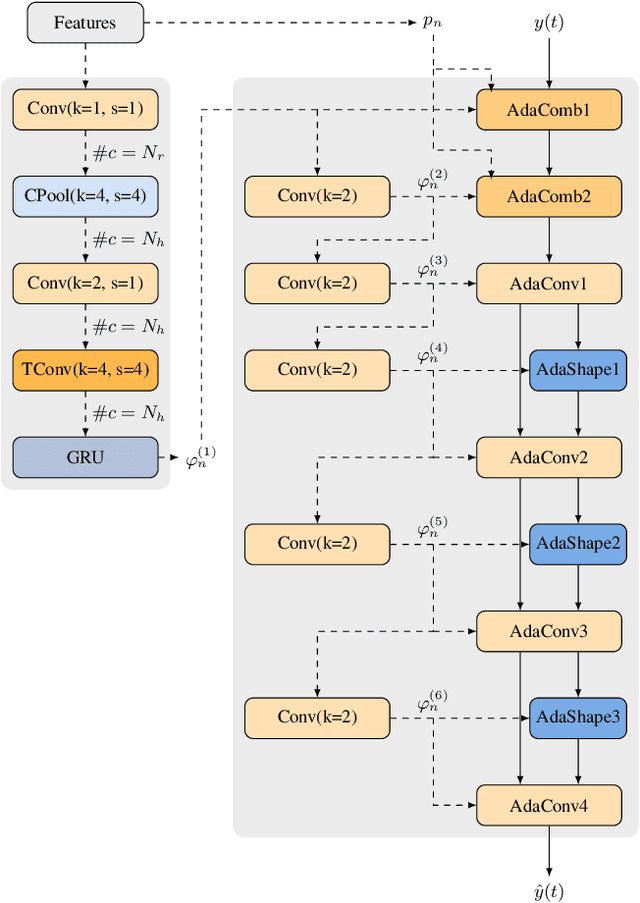
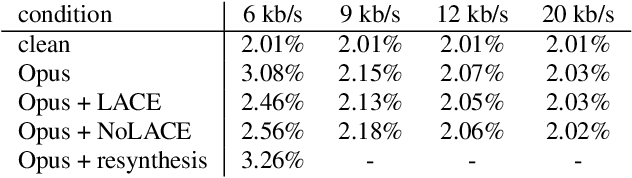
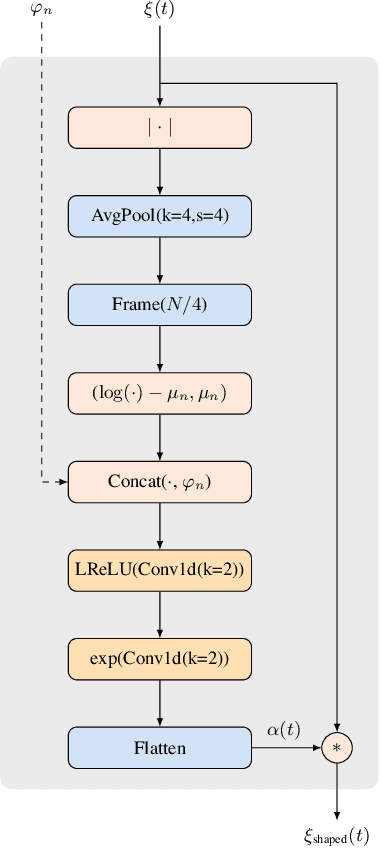
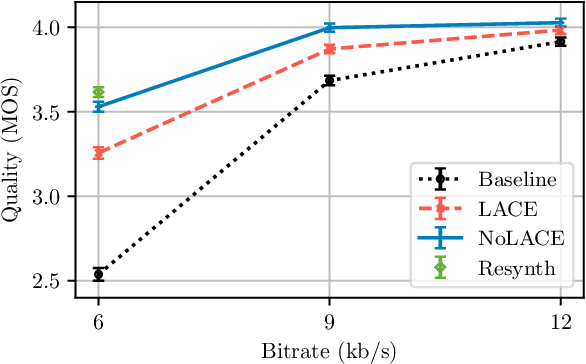
Speech codec enhancement methods are designed to remove distortions added by speech codecs. While classical methods are very low in complexity and add zero delay, their effectiveness is rather limited. Compared to that, DNN-based methods deliver higher quality but they are typically high in complexity and/or require delay. The recently proposed Linear Adaptive Coding Enhancer (LACE) addresses this problem by combining DNNs with classical long-term/short-term postfiltering resulting in a causal low-complexity model. A short-coming of the LACE model is, however, that quality quickly saturates when the model size is scaled up. To mitigate this problem, we propose a novel adatpive temporal shaping module that adds high temporal resolution to the LACE model resulting in the Non-Linear Adaptive Coding Enhancer (NoLACE). We adapt NoLACE to enhance the Opus codec and show that NoLACE significantly outperforms both the Opus baseline and an enlarged LACE model at 6, 9 and 12 kb/s. We also show that LACE and NoLACE are well-behaved when used with an ASR system.
Learning Linear Groups in Neural Networks
May 29, 2023Employing equivariance in neural networks leads to greater parameter efficiency and improved generalization performance through the encoding of domain knowledge in the architecture; however, the majority of existing approaches require an a priori specification of the desired symmetries. We present a neural network architecture, Linear Group Networks (LGNs), for learning linear groups acting on the weight space of neural networks. Linear groups are desirable due to their inherent interpretability, as they can be represented as finite matrices. LGNs learn groups without any supervision or knowledge of the hidden symmetries in the data and the groups can be mapped to well known operations in machine learning. We use LGNs to learn groups on multiple datasets while considering different downstream tasks; we demonstrate that the linear group structure depends on both the data distribution and the considered task.
Robust Audio Anomaly Detection
Feb 03, 2022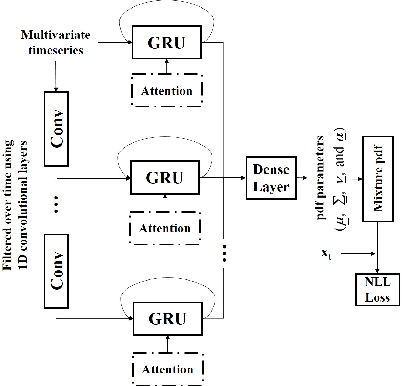
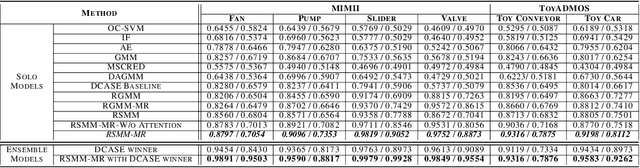

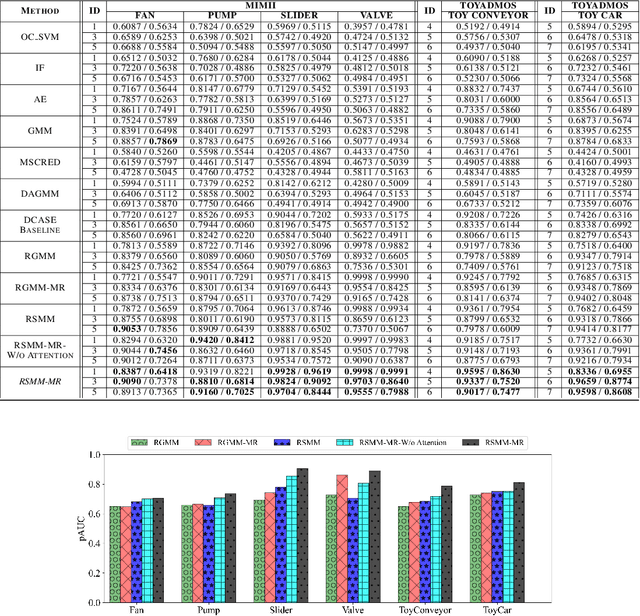
We propose an outlier robust multivariate time series model which can be used for detecting previously unseen anomalous sounds based on noisy training data. The presented approach doesn't assume the presence of labeled anomalies in the training dataset and uses a novel deep neural network architecture to learn the temporal dynamics of the multivariate time series at multiple resolutions while being robust to contaminations in the training dataset. The temporal dynamics are modeled using recurrent layers augmented with attention mechanism. These recurrent layers are built on top of convolutional layers allowing the network to extract features at multiple resolutions. The output of the network is an outlier robust probability density function modeling the conditional probability of future samples given the time series history. State-of-the-art approaches using other multiresolution architectures are contrasted with our proposed approach. We validate our solution using publicly available machine sound datasets. We demonstrate the effectiveness of our approach in anomaly detection by comparing against several state-of-the-art models.
* Accepted paper at RobustML Workshop@ICLR 2021
Low-Complexity, Real-Time Joint Neural Echo Control and Speech Enhancement Based On PercepNet
Feb 10, 2021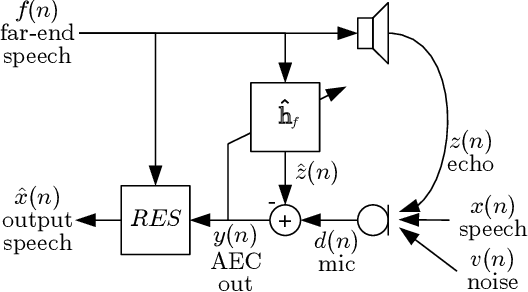
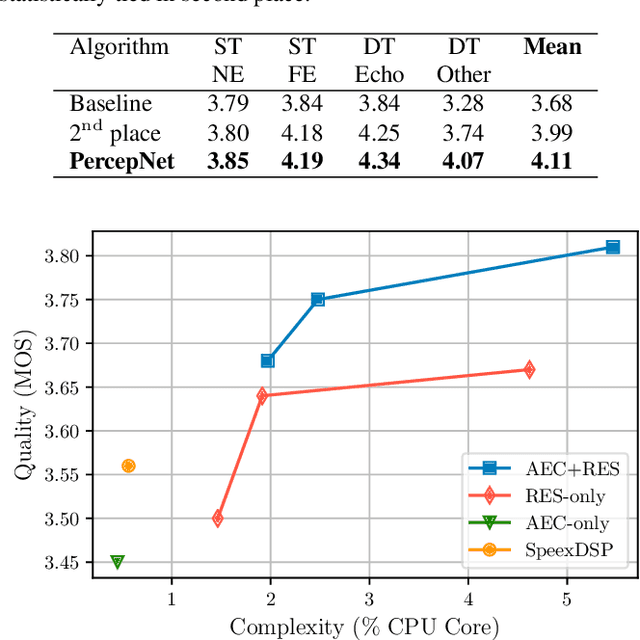
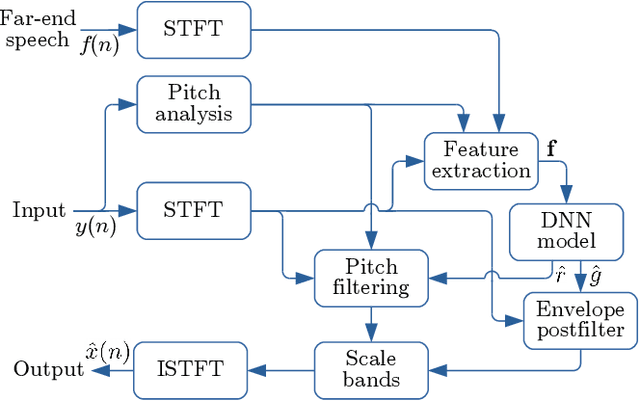
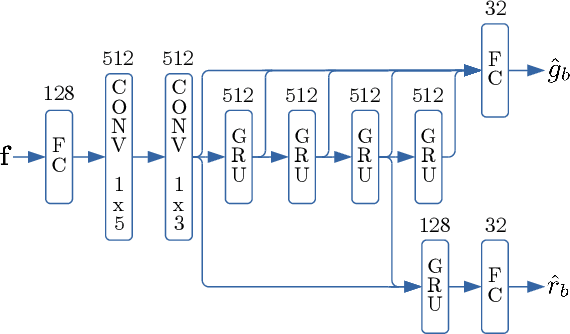
Speech enhancement algorithms based on deep learning have greatly surpassed their traditional counterparts and are now being considered for the task of removing acoustic echo from hands-free communication systems. This is a challenging problem due to both real-world constraints like loudspeaker non-linearities, and to limited compute capabilities in some communication systems. In this work, we propose a system combining a traditional acoustic echo canceller, and a low-complexity joint residual echo and noise suppressor based on a hybrid signal processing/deep neural network (DSP/DNN) approach. We show that the proposed system outperforms both traditional and other neural approaches, while requiring only 5.5% CPU for real-time operation. We further show that the system can scale to even lower complexity levels.
Enhancing Audio Augmentation Methods with Consistency Learning
Feb 09, 2021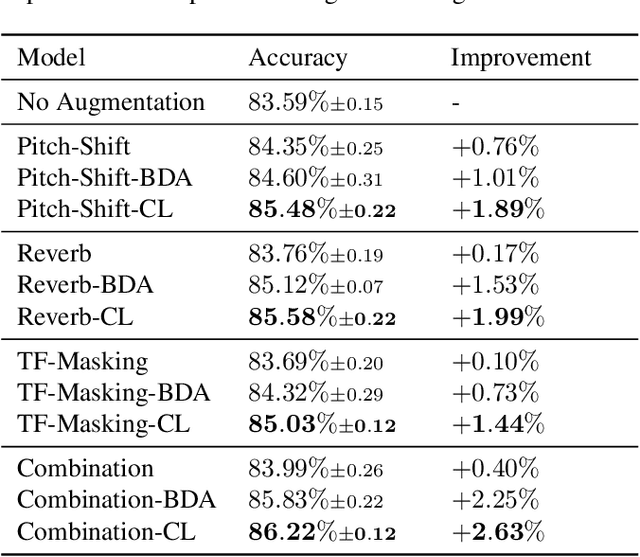

Data augmentation is an inexpensive way to increase training data diversity, and is commonly achieved via transformations of existing data. For tasks such as classification, there is a good case for learning representations of the data that are invariant to such transformations, yet this is not explicitly enforced by classification losses such as the cross-entropy loss. This paper investigates the use of training objectives that explicitly impose this consistency constraint, and how it can impact downstream audio classification tasks. In the context of deep convolutional neural networks in the supervised setting, we show empirically that certain measures of consistency are not implicitly captured by the cross-entropy loss, and that incorporating such measures into the loss function can improve the performance of tasks such as audio tagging. Put another way, we demonstrate how existing augmentation methods can further improve learning by enforcing consistency.