 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Complexity, Real-Time Joint Neural Echo Control and Speech Enhancement Based On PercepNet
Paper and Code
Feb 10, 2021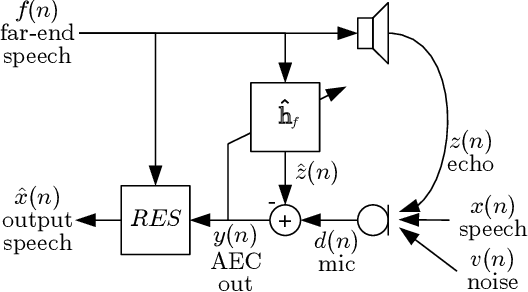
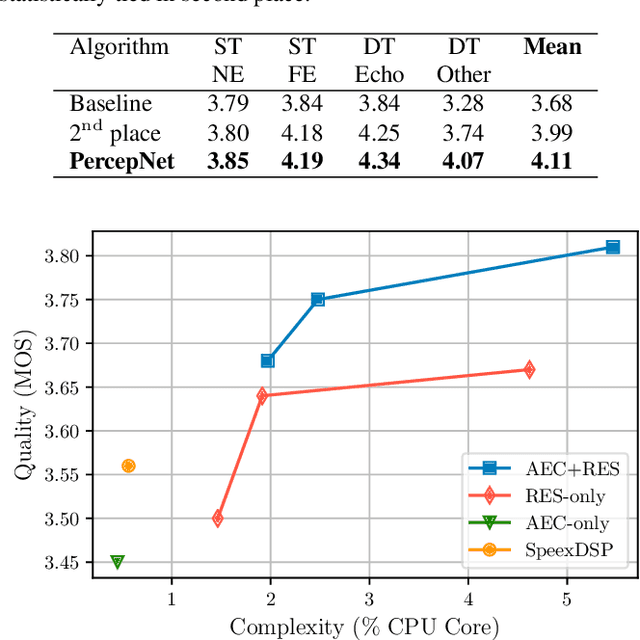
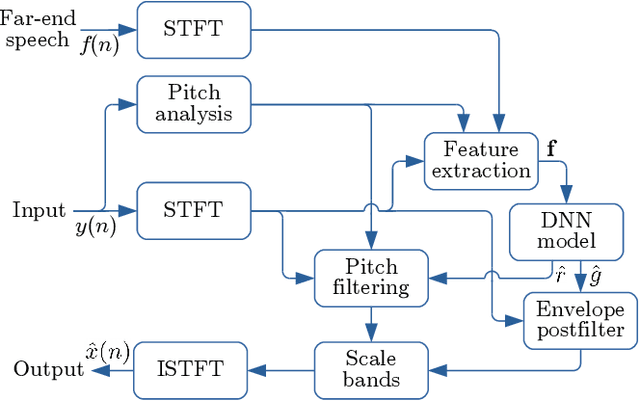
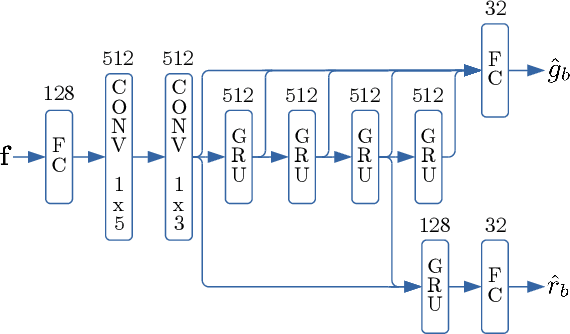
Speech enhancement algorithms based on deep learning have greatly surpassed their traditional counterparts and are now being considered for the task of removing acoustic echo from hands-free communication systems. This is a challenging problem due to both real-world constraints like loudspeaker non-linearities, and to limited compute capabilities in some communication systems. In this work, we propose a system combining a traditional acoustic echo canceller, and a low-complexity joint residual echo and noise suppressor based on a hybrid signal processing/deep neural network (DSP/DNN) approach. We show that the proposed system outperforms both traditional and other neural approaches, while requiring only 5.5% CPU for real-time operation. We further show that the system can scale to even lower complexity levels.