 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiteFix: Enhancing RAG Accuracy Through Post-Processing Citation Correction
Apr 22, 2025Retrieval Augmented Generation (RAG) has emerged as a powerful application of Large Language Models (LLMs), revolutionizing information search and consumption. RAG systems combine traditional search capabilities with LLMs to generate comprehensive answers to user queries, ideally with accurate citations. However, in our experience of developing a RAG product, LLMs often struggle with source attribution, aligning with other industry studies reporting citation accuracy rates of only about 74% for popular generative search engines. To address this, we present efficient post-processing algorithms to improve citation accuracy in LLM-generated responses, with minimal impact on latency and cost. Our approaches cross-check generated citations against retrieved articles using methods including keyword + semantic matching, fine tuned model with BERTScore, and a lightweight LLM-based technique. Our experimental results demonstrate a relative improvement of 15.46% in the overall accuracy metrics of our RAG system. This significant enhancement potentially enables a shift from our current larger language model to a relatively smaller model that is approximately 12x more cost-effective and 3x faster in inference time, while maintaining comparable performance. This research contributes to enhancing the reliability and trustworthiness of AI-generated content in information retrieval and summarization tasks which is critical to gain customer trust especially in commercial products.
Contradiction Detection in RAG Systems: Evaluating LLMs as Context Validators for Improved Information Consistency
Mar 31, 2025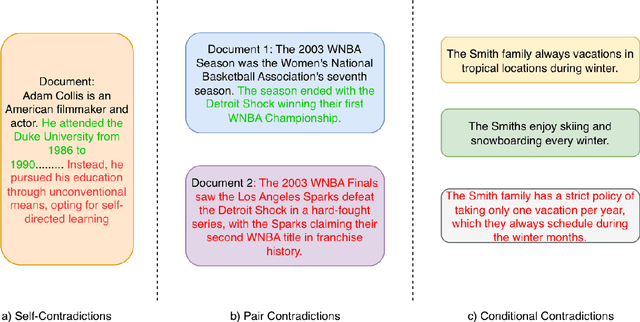
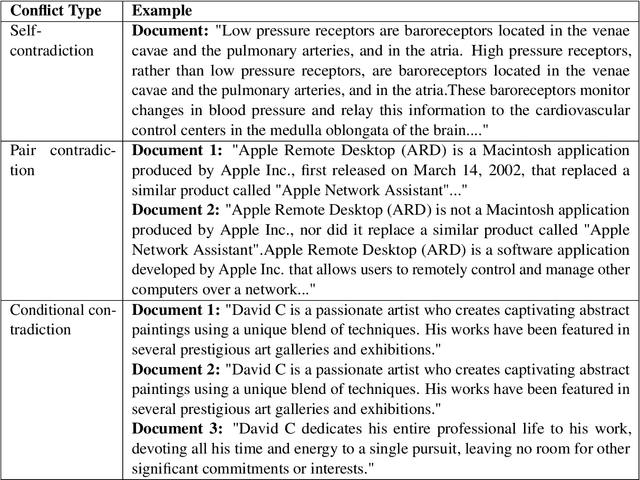
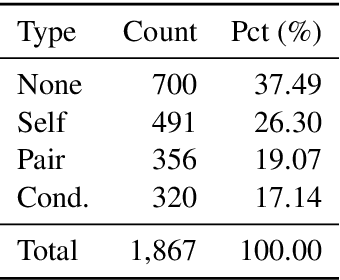
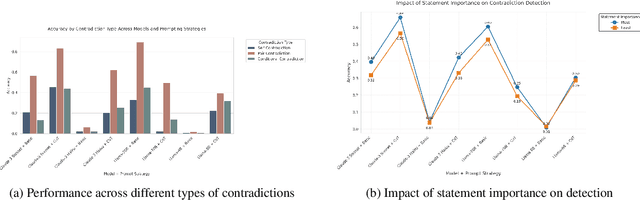
Retrieval Augmented Generation (RAG) systems have emerged as a powerful method for enhancing large language models (LLMs) with up-to-date information. However, the retrieval step in RAG can sometimes surface documents containing contradictory information, particularly in rapidly evolving domains such as news. These contradictions can significantly impact the performance of LLMs, leading to inconsistent or erroneous outputs. This study addresses this critical challenge in two ways. First, we present a novel data generation framework to simulate different types of contradictions that may occur in the retrieval stage of a RAG system. Second, we evaluate the robustness of different LLMs in performing as context validators, assessing their ability to detect contradictory information within retrieved document sets. Our experimental results reveal that context validation remains a challenging task even for state-of-the-art LLMs, with performance varying significantly across different types of contradictions. While larger models generally perform better at contradiction detection, the effectiveness of different prompting strategies varies across tasks and model architectures. We find that chain-of-thought prompting shows notable improvements for some models but may hinder performance in others, highlighting the complexity of the task and the need for more robust approaches to context validation in RAG systems.
Robust Audio Anomaly Detection
Feb 03, 2022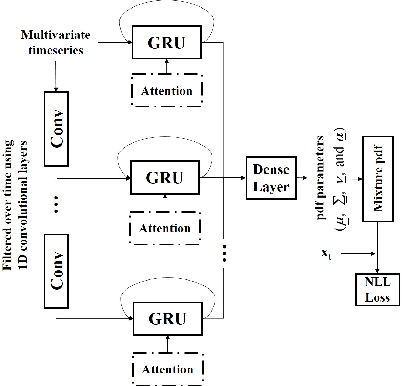
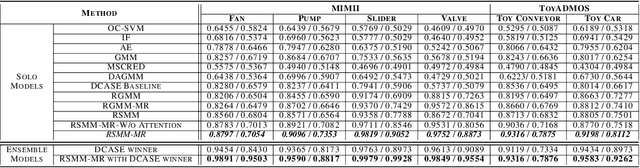

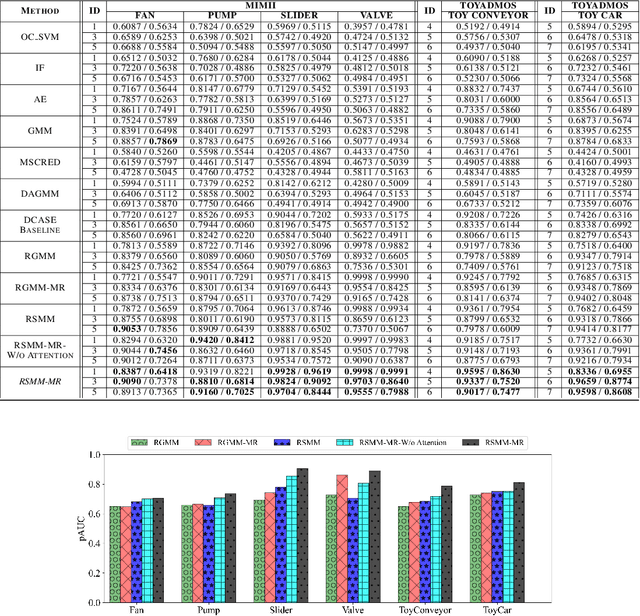
We propose an outlier robust multivariate time series model which can be used for detecting previously unseen anomalous sounds based on noisy training data. The presented approach doesn't assume the presence of labeled anomalies in the training dataset and uses a novel deep neural network architecture to learn the temporal dynamics of the multivariate time series at multiple resolutions while being robust to contaminations in the training dataset. The temporal dynamics are modeled using recurrent layers augmented with attention mechanism. These recurrent layers are built on top of convolutional layers allowing the network to extract features at multiple resolutions. The output of the network is an outlier robust probability density function modeling the conditional probability of future samples given the time series history. State-of-the-art approaches using other multiresolution architectures are contrasted with our proposed approach. We validate our solution using publicly available machine sound datasets. We demonstrate the effectiveness of our approach in anomaly detection by comparing against several state-of-the-art models.
* Accepted paper at RobustML Workshop@ICLR 2021
Low-Complexity, Real-Time Joint Neural Echo Control and Speech Enhancement Based On PercepNet
Feb 10, 2021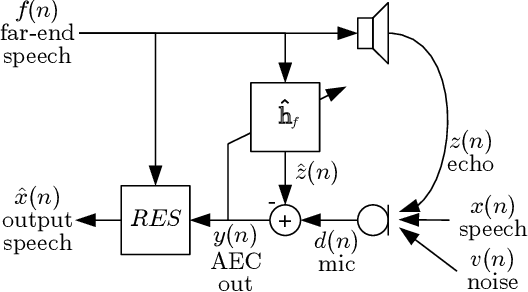
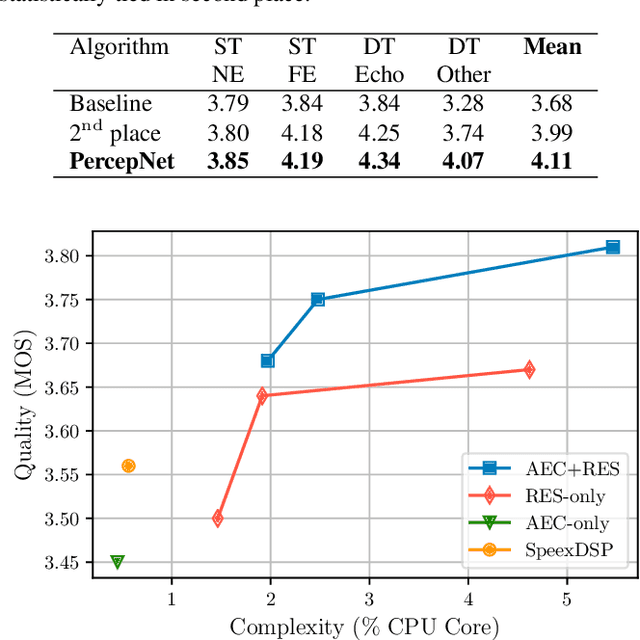
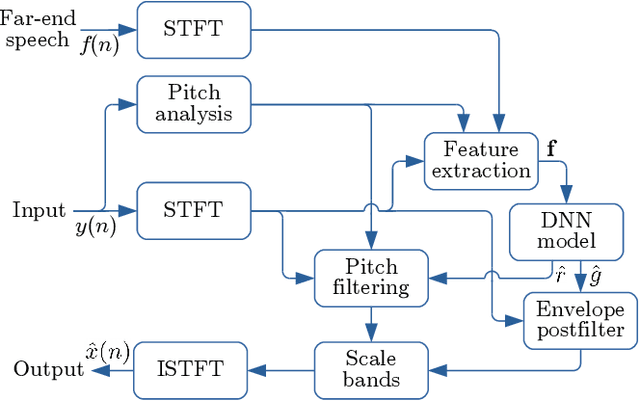
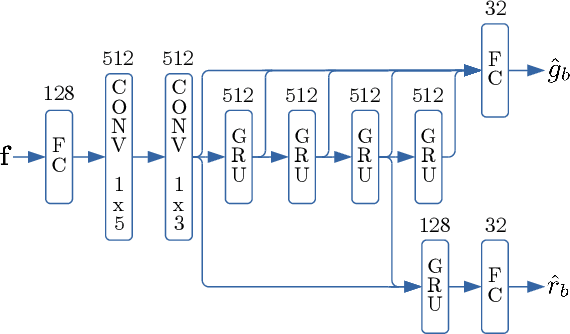
Speech enhancement algorithms based on deep learning have greatly surpassed their traditional counterparts and are now being considered for the task of removing acoustic echo from hands-free communication systems. This is a challenging problem due to both real-world constraints like loudspeaker non-linearities, and to limited compute capabilities in some communication systems. In this work, we propose a system combining a traditional acoustic echo canceller, and a low-complexity joint residual echo and noise suppressor based on a hybrid signal processing/deep neural network (DSP/DNN) approach. We show that the proposed system outperforms both traditional and other neural approaches, while requiring only 5.5% CPU for real-time operation. We further show that the system can scale to even lower complexity levels.