 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContradiction Detection in RAG Systems: Evaluating LLMs as Context Validators for Improved Information Consistency
Mar 31, 2025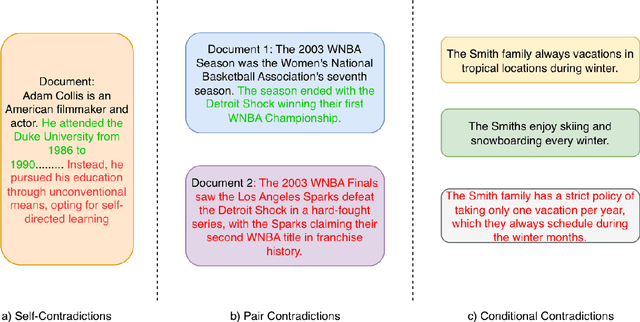
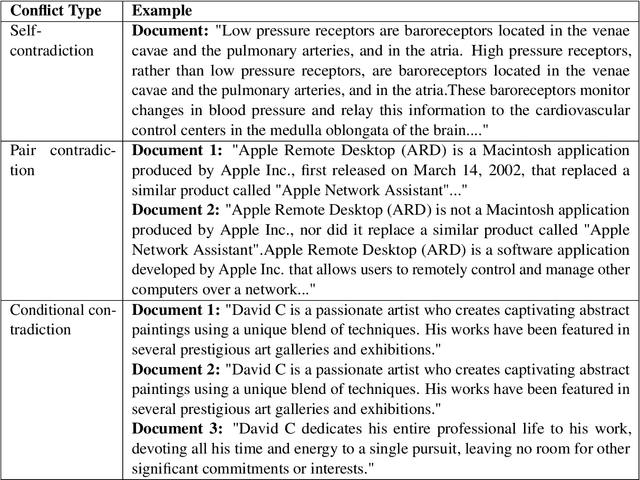
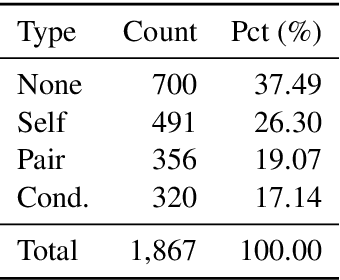
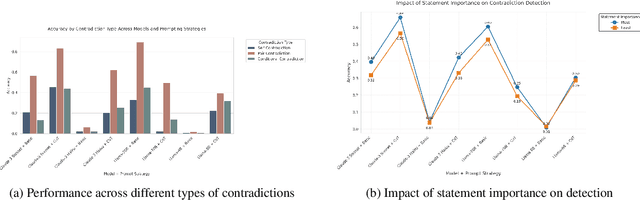
Retrieval Augmented Generation (RAG) systems have emerged as a powerful method for enhancing large language models (LLMs) with up-to-date information. However, the retrieval step in RAG can sometimes surface documents containing contradictory information, particularly in rapidly evolving domains such as news. These contradictions can significantly impact the performance of LLMs, leading to inconsistent or erroneous outputs. This study addresses this critical challenge in two ways. First, we present a novel data generation framework to simulate different types of contradictions that may occur in the retrieval stage of a RAG system. Second, we evaluate the robustness of different LLMs in performing as context validators, assessing their ability to detect contradictory information within retrieved document sets. Our experimental results reveal that context validation remains a challenging task even for state-of-the-art LLMs, with performance varying significantly across different types of contradictions. While larger models generally perform better at contradiction detection, the effectiveness of different prompting strategies varies across tasks and model architectures. We find that chain-of-thought prompting shows notable improvements for some models but may hinder performance in others, highlighting the complexity of the task and the need for more robust approaches to context validation in RAG systems.
Evaluating Co-Creativity using Total Information Flow
Feb 09, 2024



Co-creativity in music refers to two or more musicians or musical agents interacting with one another by composing or improvising music. However, this is a very subjective process and each musician has their own preference as to which improvisation is better for some context. In this paper, we aim to create a measure based on total information flow to quantitatively evaluate the co-creativity process in music. In other words, our measure is an indication of how "good" a creative musical process is. Our main hypothesis is that a good musical creation would maximize information flow between the participants captured by music voices recorded in separate tracks. We propose a method to compute the information flow using pre-trained generative models as entropy estimators. We demonstrate how our method matches with human perception using a qualitative study.
PosCUDA: Position based Convolution for Unlearnable Audio Datasets
Jan 04, 2024Deep learning models require large amounts of clean data to acheive good performance. To avoid the cost of expensive data acquisition, researchers use the abundant data available on the internet. This raises significant privacy concerns on the potential misuse of personal data for model training without authorisation. Recent works such as CUDA propose solutions to this problem by adding class-wise blurs to make datasets unlearnable, i.e a model can never use the acquired dataset for learning. However these methods often reduce the quality of the data making it useless for practical applications. We introduce PosCUDA, a position based convolution for creating unlearnable audio datasets. PosCUDA uses class-wise convolutions on small patches of audio. The location of the patches are based on a private key for each class, hence the model learns the relations between positional blurs and labels, while failing to generalize. We empirically show that PosCUDA can achieve unlearnability while maintaining the quality of the original audio datasets. Our proposed method is also robust to different audio feature representations such as MFCC, raw audio and different architectures such as transformers, convolutional networks etc.
Bias-Free FedGAN
Mar 17, 2021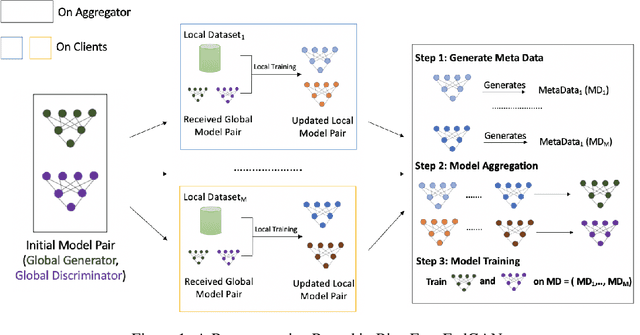

Federated Generative Adversarial Network (FedGAN) is a communication-efficient approach to train a GAN across distributed clients without clients having to share their sensitive training data. In this paper, we experimentally show that FedGAN generates biased data points under non-independent-and-identically-distributed (non-iid) settings. Also, we propose Bias-Free FedGAN, an approach to generate bias-free synthetic datasets using FedGAN. Bias-Free FedGAN has the same communication cost as that of FedGAN. Experimental results on image datasets (MNIST and FashionMNIST) validate our claims.
DPD-InfoGAN: Differentially Private Distributed InfoGAN
Oct 24, 2020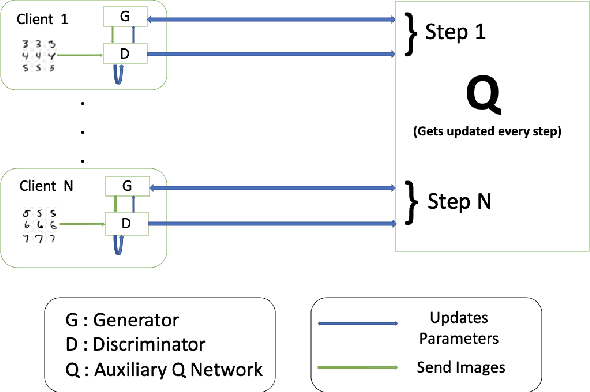
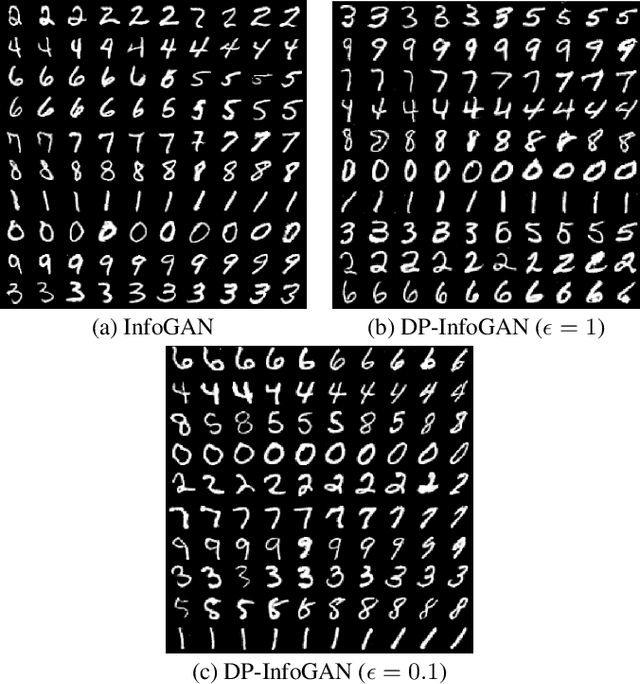


Generative Adversarial Networks (GANs) are deep learning architectures capable of generating synthetic datasets. Despite producing high-quality synthetic images, the default GAN has no control over the kinds of images it generates. The Information Maximizing GAN (InfoGAN) is a variant of the default GAN that introduces feature-control variables that are automatically learned by the framework, hence providing greater control over the different kinds of images produced. Due to the high model complexity of InfoGAN, the generative distribution tends to be concentrated around the training data points. This is a critical problem as the models may inadvertently expose the sensitive and private information present in the dataset. To address this problem, we propose a differentially private version of InfoGAN (DP-InfoGAN). We also extend our framework to a distributed setting (DPD-InfoGAN) to allow clients to learn different attributes present in other clients' datasets in a privacy-preserving manner. In our experiments, we show that both DP-InfoGAN and DPD-InfoGAN can synthesize high-quality images with flexible control over image attributes while preserving privacy.
Deep Learning for Skin Lesion Classification
Mar 13, 2017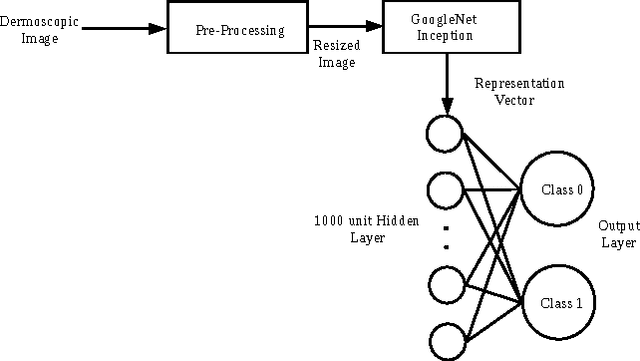
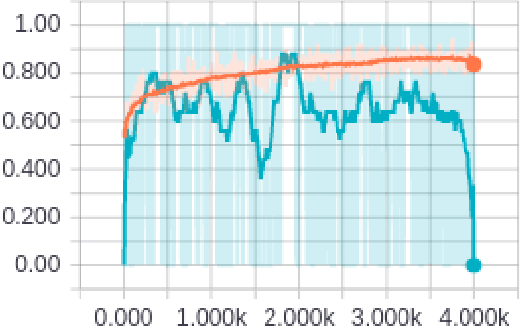
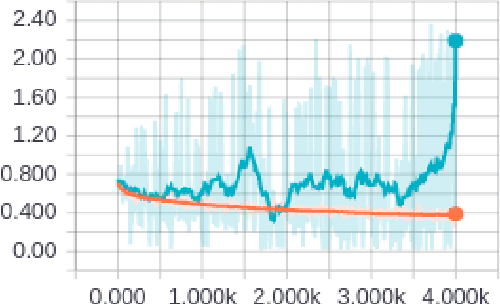
Melanoma, a malignant form of skin cancer is very threatening to life. Diagnosis of melanoma at an earlier stage is highly needed as it has a very high cure rate. Benign and malignant forms of skin cancer can be detected by analyzing the lesions present on the surface of the skin using dermoscopic images. In this work, an automated skin lesion detection system has been developed which learns the representation of the image using Google's pretrained CNN model known as Inception-v3 \cite{cnn}. After obtaining the representation vector for our input dermoscopic images we have trained two layer feed forward neural network to classify the images as malignant or benign. The system also classifies the images based on the cause of the cancer either due to melanocytic or non-melanocytic cells using a different neural network. These classification tasks are part of the challenge organized by International Skin Imaging Collaboration (ISIC) 2017. Our system learns to classify the images based on the model built using the training images given in the challenge and the experimental results were evaluated using validation and test sets. Our system has achieved an overall accuracy of 65.8\% for the validation set.