 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiteFix: Enhancing RAG Accuracy Through Post-Processing Citation Correction
Apr 22, 2025Retrieval Augmented Generation (RAG) has emerged as a powerful application of Large Language Models (LLMs), revolutionizing information search and consumption. RAG systems combine traditional search capabilities with LLMs to generate comprehensive answers to user queries, ideally with accurate citations. However, in our experience of developing a RAG product, LLMs often struggle with source attribution, aligning with other industry studies reporting citation accuracy rates of only about 74% for popular generative search engines. To address this, we present efficient post-processing algorithms to improve citation accuracy in LLM-generated responses, with minimal impact on latency and cost. Our approaches cross-check generated citations against retrieved articles using methods including keyword + semantic matching, fine tuned model with BERTScore, and a lightweight LLM-based technique. Our experimental results demonstrate a relative improvement of 15.46% in the overall accuracy metrics of our RAG system. This significant enhancement potentially enables a shift from our current larger language model to a relatively smaller model that is approximately 12x more cost-effective and 3x faster in inference time, while maintaining comparable performance. This research contributes to enhancing the reliability and trustworthiness of AI-generated content in information retrieval and summarization tasks which is critical to gain customer trust especially in commercial products.
We're Not Using Videos Effectively: An Updated Domain Adaptive Video Segmentation Baseline
Feb 06, 2024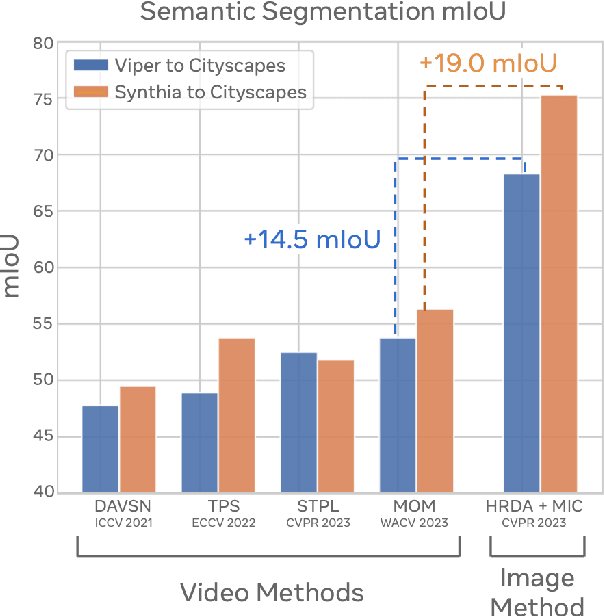

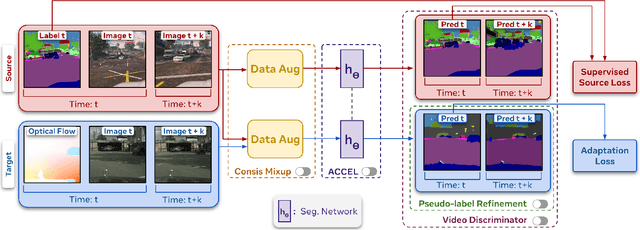
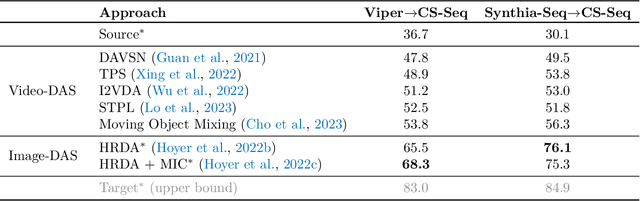
There has been abundant work in unsupervised domain adaptation for semantic segmentation (DAS) seeking to adapt a model trained on images from a labeled source domain to an unlabeled target domain. While the vast majority of prior work has studied this as a frame-level Image-DAS problem, a few Video-DAS works have sought to additionally leverage the temporal signal present in adjacent frames. However, Video-DAS works have historically studied a distinct set of benchmarks from Image-DAS, with minimal cross-benchmarking. In this work, we address this gap. Surprisingly, we find that (1) even after carefully controlling for data and model architecture, state-of-the-art Image-DAS methods (HRDA and HRDA+MIC) outperform Video-DAS methods on established Video-DAS benchmarks (+14.5 mIoU on Viper$\rightarrow$CityscapesSeq, +19.0 mIoU on Synthia$\rightarrow$CityscapesSeq), and (2) naive combinations of Image-DAS and Video-DAS techniques only lead to marginal improvements across datasets. To avoid siloed progress between Image-DAS and Video-DAS, we open-source our codebase with support for a comprehensive set of Video-DAS and Image-DAS methods on a common benchmark. Code available at https://github.com/SimarKareer/UnifiedVideoDA
Missing Modality Robustness in Semi-Supervised Multi-Modal Semantic Segmentation
Apr 21, 2023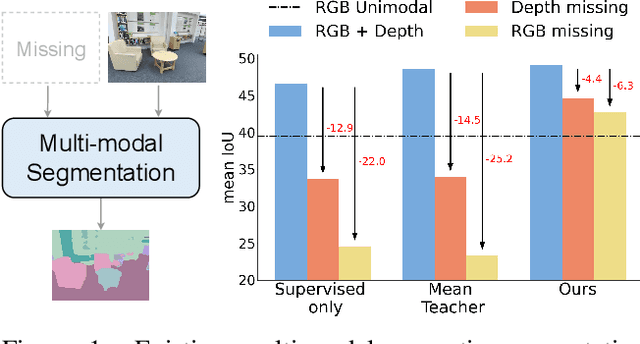

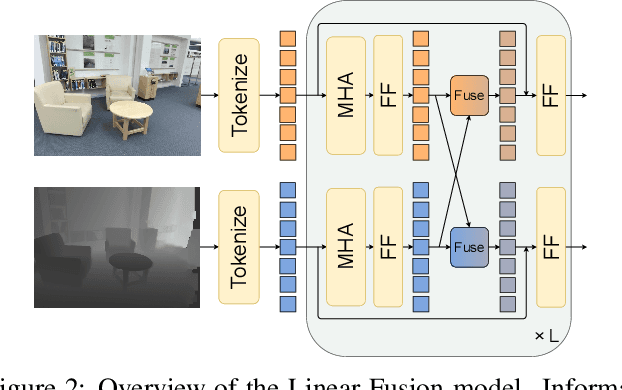
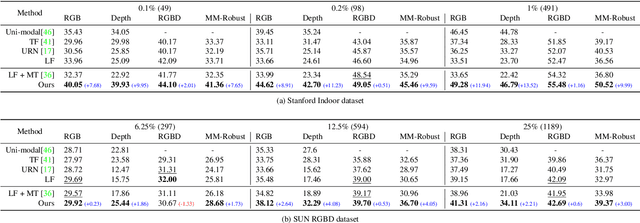
Using multiple spatial modalities has been proven helpful in improving semantic segmentation performance. However, there are several real-world challenges that have yet to be addressed: (a) improving label efficiency and (b) enhancing robustness in realistic scenarios where modalities are missing at the test time. To address these challenges, we first propose a simple yet efficient multi-modal fusion mechanism Linear Fusion, that performs better than the state-of-the-art multi-modal models even with limited supervision. Second, we propose M3L: Multi-modal Teacher for Masked Modality Learning, a semi-supervised framework that not only improves the multi-modal performance but also makes the model robust to the realistic missing modality scenario using unlabeled data. We create the first benchmark for semi-supervised multi-modal semantic segmentation and also report the robustness to missing modalities. Our proposal shows an absolute improvement of up to 10% on robust mIoU above the most competitive baselines. Our code is available at https://github.com/harshm121/M3L
Performance degradation of ImageNet trained models by simple image transformations
Jul 17, 2022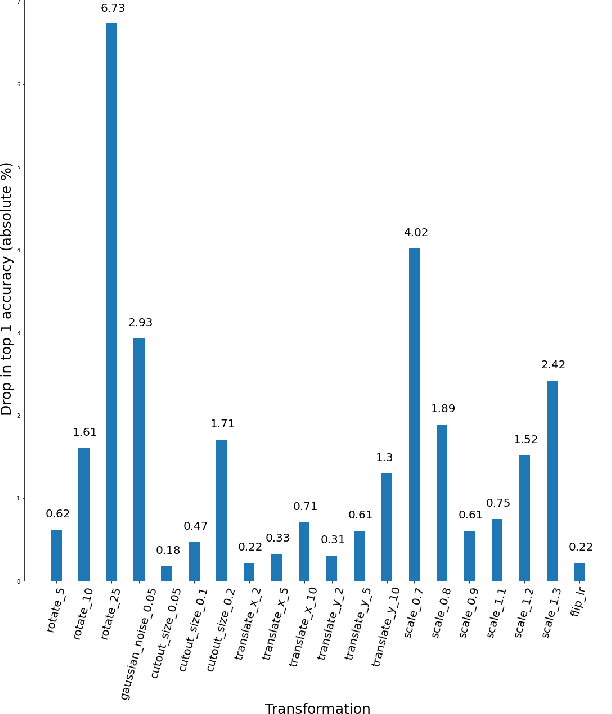

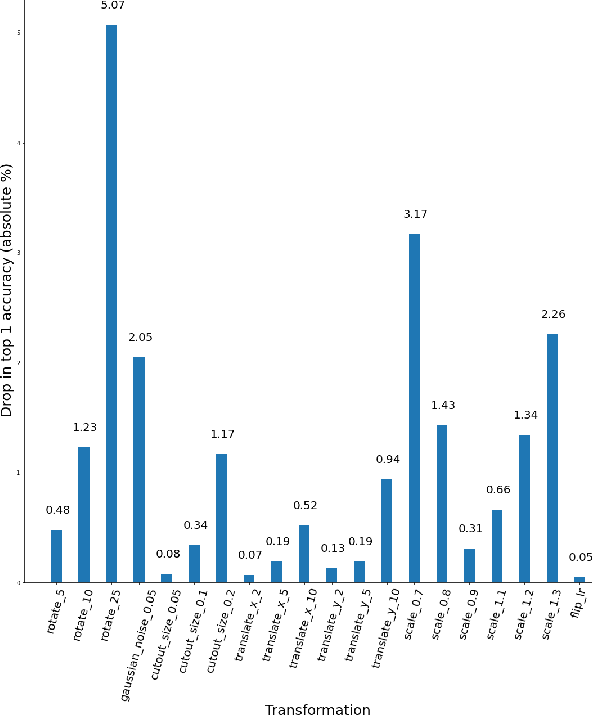
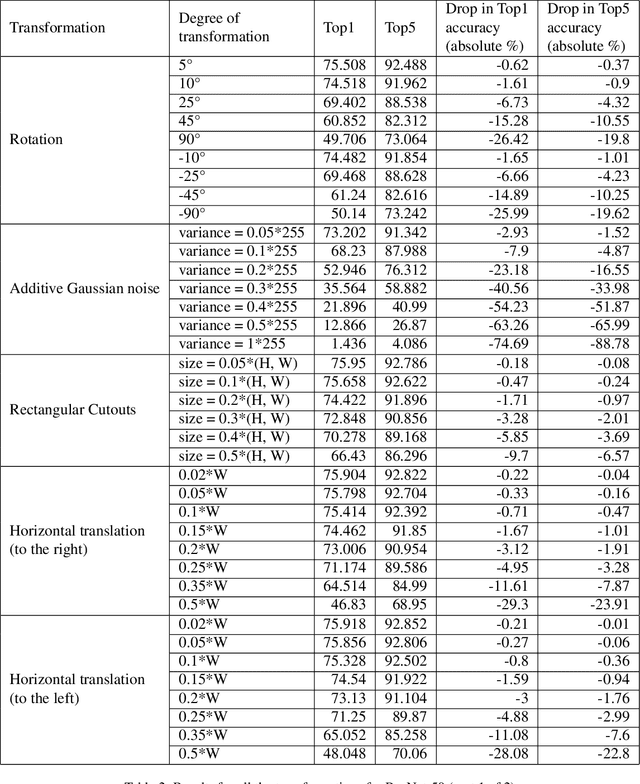
ImageNet trained PyTorch models are generally preferred as the off-the-shelf models for direct use or for initialisation in most computer vision tasks. In this paper, we simply test a representative set of these convolution and transformer based models under many simple image transformations like horizontal shifting, vertical shifting, scaling, rotation, presence of Gaussian noise, cutout, horizontal flip and vertical flip and report the performance drop caused by such transformations. We find that even simple transformations like rotating the image by 10{\deg} or zooming in by 20% can reduce the top-1 accuracy of models like ResNet152 by 1%+. The code is available at https://github.com/harshm121/imagenet-transformation-degradation.
An Application to Generate Style Guided Compatible Outfit
May 02, 2022Fashion recommendation has witnessed a phenomenal growth of research, particularly in the domains of shop-the-look, contextaware outfit creation, personalizing outfit creation etc. Majority of the work in this area focuses on better understanding of the notion of complimentary relationship between lifestyle items. Quite recently, some works have realised that style plays a vital role in fashion, especially in the understanding of compatibility learning and outfit creation. In this paper, we would like to present the end-to-end design of a methodology in which we aim to generate outfits guided by styles or themes using a novel style encoder network. We present an extensive analysis of different aspects of our method through various experiments. We also provide a demonstration api to showcase the ability of our work in generating outfits based on an anchor item and styles.
Recommendation of Compatible Outfits Conditioned on Style
Mar 30, 2022

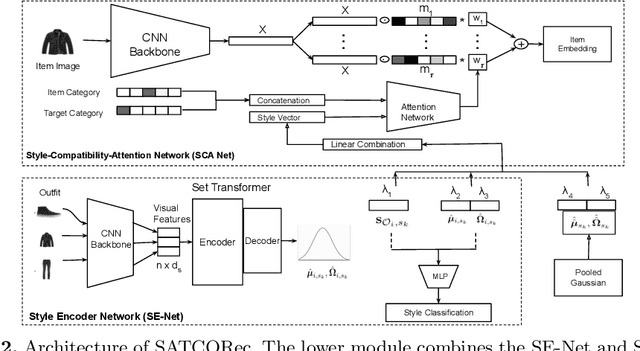

Recommendation in the fashion domain has seen a recent surge in research in various areas, for example, shop-the-look, context-aware outfit creation, personalizing outfit creation, etc. The majority of state of the art approaches in the domain of outfit recommendation pursue to improve compatibility among items so as to produce high quality outfits. Some recent works have realized that style is an important factor in fashion and have incorporated it in compatibility learning and outfit generation. These methods often depend on the availability of fine-grained product categories or the presence of rich item attributes (e.g., long-skirt, mini-skirt, etc.). In this work, we aim to generate outfits conditional on styles or themes as one would dress in real life, operating under the practical assumption that each item is mapped to a high level category as driven by the taxonomy of an online portal, like outdoor, formal etc and an image. We use a novel style encoder network that renders outfit styles in a smooth latent space. We present an extensive analysis of different aspects of our method and demonstrate its superiority over existing state of the art baselines through rigorous experiments.
MSN: Efficient Online Mask Selection Network for Video Instance Segmentation
Jun 19, 2021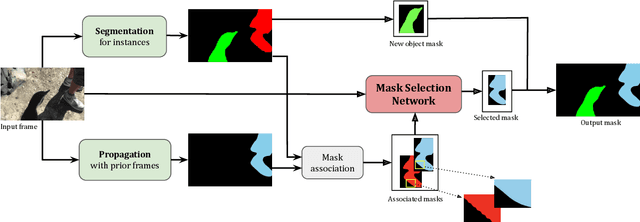


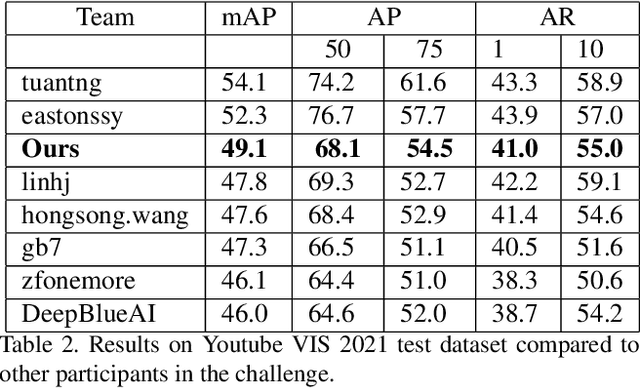
In this work we present a novel solution for Video Instance Segmentation(VIS), that is automatically generating instance level segmentation masks along with object class and tracking them in a video. Our method improves the masks from segmentation and propagation branches in an online manner using the Mask Selection Network (MSN) hence limiting the noise accumulation during mask tracking. We propose an effective design of MSN by using patch-based convolutional neural network. The network is able to distinguish between very subtle differences between the masks and choose the better masks out of the associated masks accurately. Further, we make use of temporal consistency and process the video sequences in both forward and reverse manner as a post processing step to recover lost objects. The proposed method can be used to adapt any video object segmentation method for the task of VIS. Our method achieves a score of 49.1 mAP on 2021 YouTube-VIS Challenge and was ranked third place among more than 30 global teams. Our code will be available at https://github.com/SHI-Labs/Mask-Selection-Networks.
Audience Creation for Consumables -- Simple and Scalable Precision Merchandising for a Growing Marketplace
Nov 17, 2020
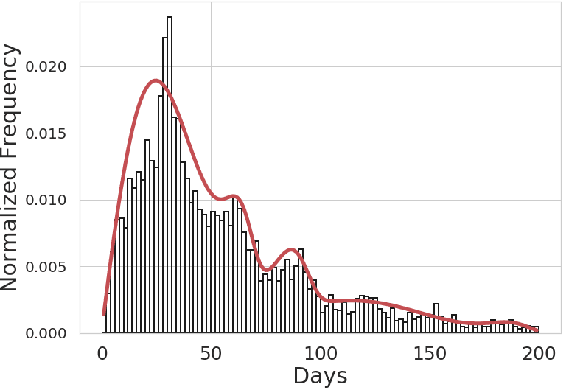
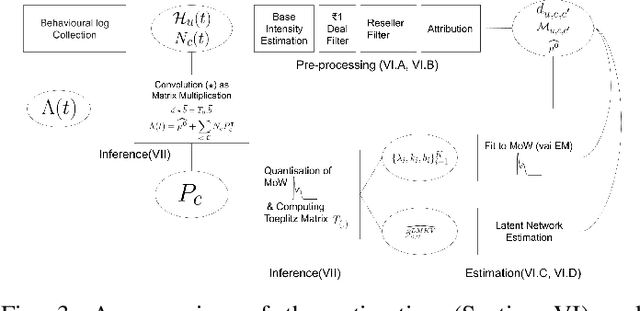
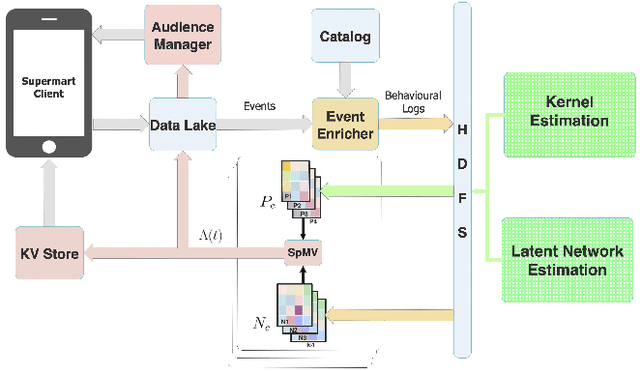
Consumable categories, such as grocery and fast-moving consumer goods, are quintessential to the growth of e-commerce marketplaces in developing countries. In this work, we present the design and implementation of a precision merchandising system, which creates audience sets from over 10 million consumers and is deployed at Flipkart Supermart, one of the largest online grocery stores in India. We employ temporal point process to model the latent periodicity and mutual-excitation in the purchase dynamics of consumables. Further, we develop a likelihood-free estimation procedure that is robust against data sparsity, censure and noise typical of a growing marketplace. Lastly, we scale the inference by quantizing the triggering kernels and exploiting sparse matrix-vector multiplication primitive available on a commercial distributed linear algebra backend. In operation spanning more than a year, we have witnessed a consistent increase in click-through rate in the range of 25-70% for banner-based merchandising in the storefront, and in the range of 12-26% for push notification-based campaigns.
SCL: Towards Accurate Domain Adaptive Object Detection via Gradient Detach Based Stacked Complementary Losses
Nov 21, 2019



Unsupervised domain adaptive object detection aims to learn a robust detector in the domain shift circumstance, where the training (source) domain is label-rich with bounding box annotations, while the testing (target) domain is label-agnostic and the feature distributions between training and testing domains are dissimilar or even totally different. In this paper, we propose a gradient detach based stacked complementary losses (SCL) method that uses detection losses as the primary objective, and cuts in several auxiliary losses in different network stages accompanying with gradient detach training to learn more discriminative representations. We argue that the prior methods mainly leverage more loss functions for training but ignore the interaction of different losses and also the compatible training strategy (gradient detach updating in our work). Thus, our proposed method is a more syncretic adaptation learning process. We conduct comprehensive experiments on seven datasets, the results demonstrate that our method performs favorably better than the state-of-the-art methods by a significant margin. For instance, from Cityscapes to FoggyCityscapes, we achieve 37.9% mAP, outperforming the previous art Strong-Weak by 3.6%.