 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWALT: Web Agents that Learn Tools
Oct 01, 2025Web agents promise to automate complex browser tasks, but current methods remain brittle -- relying on step-by-step UI interactions and heavy LLM reasoning that break under dynamic layouts and long horizons. Humans, by contrast, exploit website-provided functionality through high-level operations like search, filter, and sort. We introduce WALT (Web Agents that Learn Tools), a framework that reverse-engineers latent website functionality into reusable invocable tools. Rather than hypothesizing ad-hoc skills, WALT exposes robust implementations of automations already designed into websites -- spanning discovery (search, filter, sort), communication (post, comment, upvote), and content management (create, edit, delete). Tools abstract away low-level execution: instead of reasoning about how to click and type, agents simply call search(query) or create(listing). This shifts the computational burden from fragile step-by-step reasoning to reliable tool invocation. On VisualWebArena and WebArena, WALT achieves higher success with fewer steps and less LLM-dependent reasoning, establishing a robust and generalizable paradigm for browser automation.
SCUBA: Salesforce Computer Use Benchmark
Sep 30, 2025

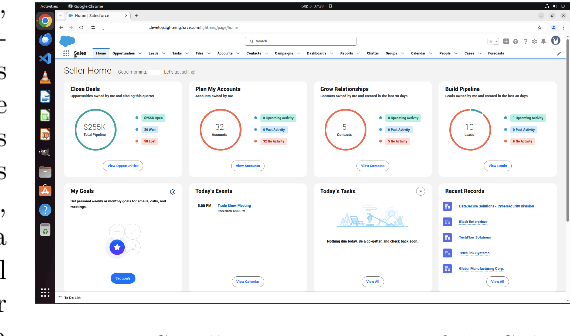

We introduce SCUBA, a benchmark designed to evaluate computer-use agents on customer relationship management (CRM) workflows within the Salesforce platform. SCUBA contains 300 task instances derived from real user interviews, spanning three primary personas, platform administrators, sales representatives, and service agents. The tasks test a range of enterprise-critical abilities, including Enterprise Software UI navigation, data manipulation, workflow automation, information retrieval, and troubleshooting. To ensure realism, SCUBA operates in Salesforce sandbox environments with support for parallel execution and fine-grained evaluation metrics to capture milestone progress. We benchmark a diverse set of agents under both zero-shot and demonstration-augmented settings. We observed huge performance gaps in different agent design paradigms and gaps between the open-source model and the closed-source model. In the zero-shot setting, open-source model powered computer-use agents that have strong performance on related benchmarks like OSWorld only have less than 5\% success rate on SCUBA, while methods built on closed-source models can still have up to 39% task success rate. In the demonstration-augmented settings, task success rates can be improved to 50\% while simultaneously reducing time and costs by 13% and 16%, respectively. These findings highlight both the challenges of enterprise tasks automation and the promise of agentic solutions. By offering a realistic benchmark with interpretable evaluation, SCUBA aims to accelerate progress in building reliable computer-use agents for complex business software ecosystems.
CoAct-1: Computer-using Agents with Coding as Actions
Aug 05, 2025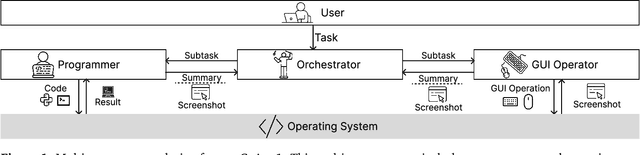
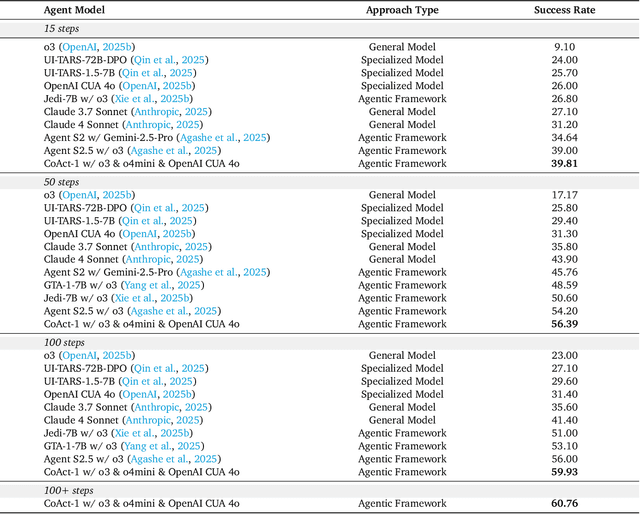
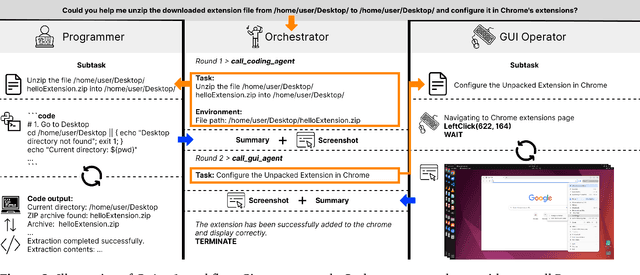

Autonomous agents that operate computers via Graphical User Interfaces (GUIs) often struggle with efficiency and reliability on complex, long-horizon tasks. While augmenting these agents with planners can improve task decomposition, they remain constrained by the inherent limitations of performing all actions through GUI manipulation, leading to brittleness and inefficiency. In this work, we introduce a more robust and flexible paradigm: enabling agents to use coding as a enhanced action. We present CoAct-1, a novel multi-agent system that synergistically combines GUI-based control with direct programmatic execution. CoAct-1 features an Orchestrator that dynamically delegates subtasks to either a conventional GUI Operator or a specialized Programmer agent, which can write and execute Python or Bash scripts. This hybrid approach allows the agent to bypass inefficient GUI action sequences for tasks like file management and data processing, while still leveraging visual interaction when necessary. We evaluate our system on the challenging OSWorld benchmark, where CoAct-1 achieves a new state-of-the-art success rate of 60.76%, significantly outperforming prior methods. Furthermore, our approach dramatically improves efficiency, reducing the average number of steps required to complete a task to just 10.15, compared to 15 for leading GUI agents. Our results demonstrate that integrating coding as a core action provides a more powerful, efficient, and scalable path toward generalized computer automation.
Trust but Verify: Programmatic VLM Evaluation in the Wild
Oct 17, 2024
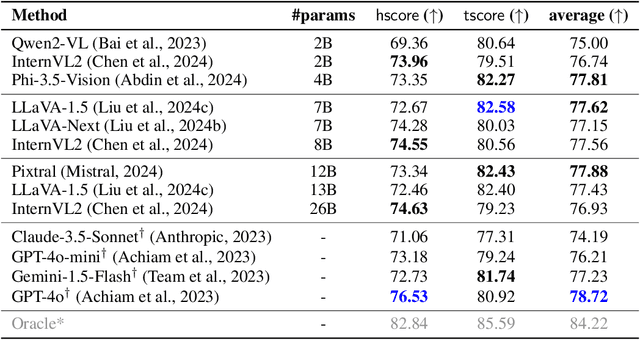

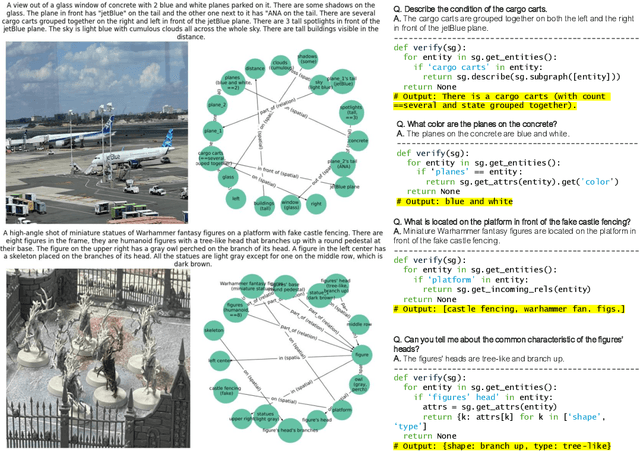
Vision-Language Models (VLMs) often generate plausible but incorrect responses to visual queries. However, reliably quantifying the effect of such hallucinations in free-form responses to open-ended queries is challenging as it requires visually verifying each claim within the response. We propose Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm for evaluating VLM responses to open-ended queries. To construct PROVE, we provide a large language model (LLM) with a high-fidelity scene-graph representation constructed from a hyper-detailed image caption, and prompt it to generate diverse question-answer (QA) pairs, as well as programs that can be executed over the scene graph object to verify each QA pair. We thus construct a benchmark of 10.5k challenging but visually grounded QA pairs. Next, to evaluate free-form model responses to queries in PROVE, we propose a programmatic evaluation strategy that measures both the helpfulness and truthfulness of a response within a unified scene graph-based framework. We benchmark the helpfulness-truthfulness trade-offs of a range of VLMs on PROVE, finding that very few are in-fact able to achieve a good balance between the two. Project page: \url{https://prove-explorer.netlify.app/}.
xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
Aug 16, 2024



This report introduces xGen-MM (also known as BLIP-3), a framework for developing Large Multimodal Models (LMMs). The framework comprises meticulously curated datasets, a training recipe, model architectures, and a resulting suite of LMMs. xGen-MM, short for xGen-MultiModal, expands the Salesforce xGen initiative on foundation AI models. Our models undergo rigorous evaluation across a range of tasks, including both single and multi-image benchmarks. Our pre-trained base model exhibits strong in-context learning capabilities and the instruction-tuned model demonstrates competitive performance among open-source LMMs with similar model sizes. In addition, we introduce a safety-tuned model with DPO, aiming to mitigate harmful behaviors such as hallucinations and improve safety. We open-source our models, curated large-scale datasets, and our fine-tuning codebase to facilitate further advancements in LMM research. Associated resources will be available on our project page above.
We're Not Using Videos Effectively: An Updated Domain Adaptive Video Segmentation Baseline
Feb 06, 2024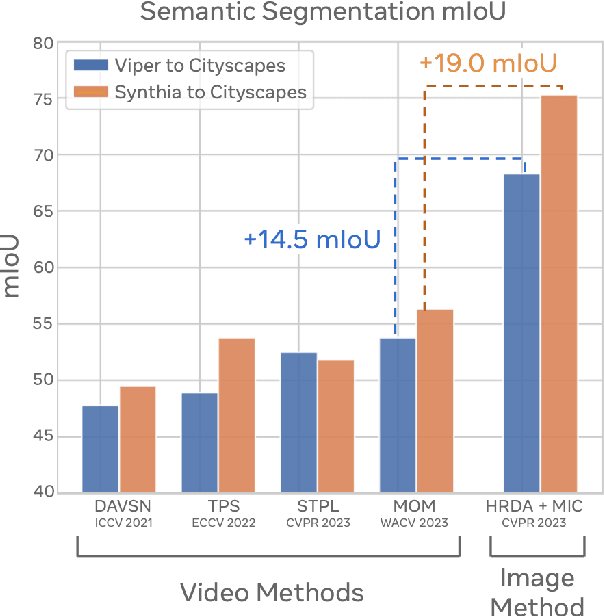

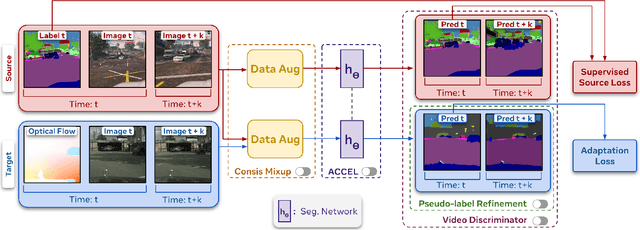
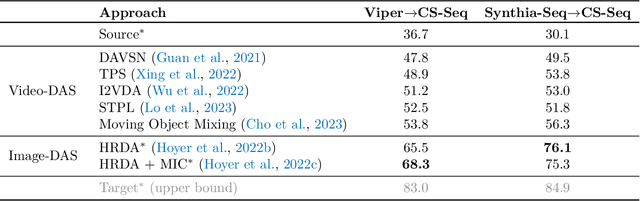
There has been abundant work in unsupervised domain adaptation for semantic segmentation (DAS) seeking to adapt a model trained on images from a labeled source domain to an unlabeled target domain. While the vast majority of prior work has studied this as a frame-level Image-DAS problem, a few Video-DAS works have sought to additionally leverage the temporal signal present in adjacent frames. However, Video-DAS works have historically studied a distinct set of benchmarks from Image-DAS, with minimal cross-benchmarking. In this work, we address this gap. Surprisingly, we find that (1) even after carefully controlling for data and model architecture, state-of-the-art Image-DAS methods (HRDA and HRDA+MIC) outperform Video-DAS methods on established Video-DAS benchmarks (+14.5 mIoU on Viper$\rightarrow$CityscapesSeq, +19.0 mIoU on Synthia$\rightarrow$CityscapesSeq), and (2) naive combinations of Image-DAS and Video-DAS techniques only lead to marginal improvements across datasets. To avoid siloed progress between Image-DAS and Video-DAS, we open-source our codebase with support for a comprehensive set of Video-DAS and Image-DAS methods on a common benchmark. Code available at https://github.com/SimarKareer/UnifiedVideoDA
AUGCAL: Improving Sim2Real Adaptation by Uncertainty Calibration on Augmented Synthetic Images
Dec 19, 2023

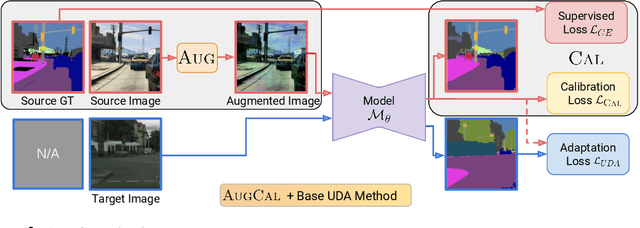

Synthetic data (SIM) drawn from simulators have emerged as a popular alternative for training models where acquiring annotated real-world images is difficult. However, transferring models trained on synthetic images to real-world applications can be challenging due to appearance disparities. A commonly employed solution to counter this SIM2REAL gap is unsupervised domain adaptation, where models are trained using labeled SIM data and unlabeled REAL data. Mispredictions made by such SIM2REAL adapted models are often associated with miscalibration - stemming from overconfident predictions on real data. In this paper, we introduce AUGCAL, a simple training-time patch for unsupervised adaptation that improves SIM2REAL adapted models by - (1) reducing overall miscalibration, (2) reducing overconfidence in incorrect predictions and (3) improving confidence score reliability by better guiding misclassification detection - all while retaining or improving SIM2REAL performance. Given a base SIM2REAL adaptation algorithm, at training time, AUGCAL involves replacing vanilla SIM images with strongly augmented views (AUG intervention) and additionally optimizing for a training time calibration loss on augmented SIM predictions (CAL intervention). We motivate AUGCAL using a brief analytical justification of how to reduce miscalibration on unlabeled REAL data. Through our experiments, we empirically show the efficacy of AUGCAL across multiple adaptation methods, backbones, tasks and shifts.
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
Nov 20, 2023



Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets. We release the raw results of our experiments along with code that allows researchers to put their own backbones through the gauntlet here: https://github.com/hsouri/Battle-of-the-Backbones
FACTS: First Amplify Correlations and Then Slice to Discover Bias
Sep 29, 2023



Computer vision datasets frequently contain spurious correlations between task-relevant labels and (easy to learn) latent task-irrelevant attributes (e.g. context). Models trained on such datasets learn "shortcuts" and underperform on bias-conflicting slices of data where the correlation does not hold. In this work, we study the problem of identifying such slices to inform downstream bias mitigation strategies. We propose First Amplify Correlations and Then Slice to Discover Bias (FACTS), wherein we first amplify correlations to fit a simple bias-aligned hypothesis via strongly regularized empirical risk minimization. Next, we perform correlation-aware slicing via mixture modeling in bias-aligned feature space to discover underperforming data slices that capture distinct correlations. Despite its simplicity, our method considerably improves over prior work (by as much as 35% precision@10) in correlation bias identification across a range of diverse evaluation settings. Our code is available at: https://github.com/yvsriram/FACTS.
ICON$^2$: Reliably Benchmarking Predictive Inequity in Object Detection
Jun 07, 2023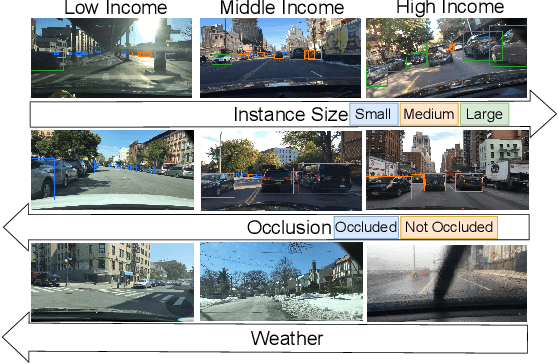
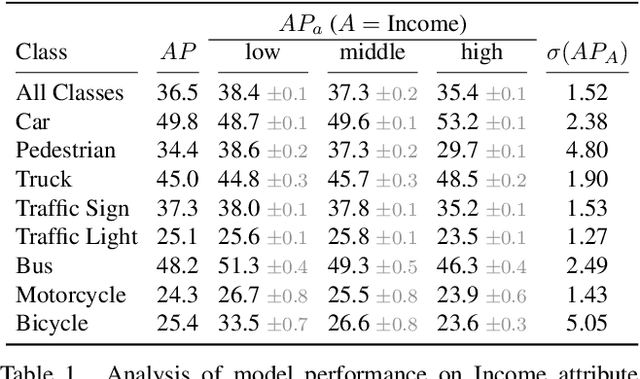
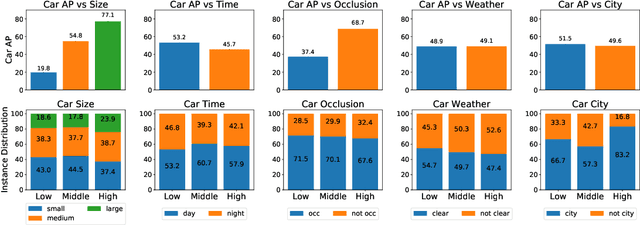
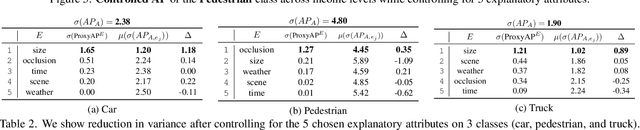
As computer vision systems are being increasingly deployed at scale in high-stakes applications like autonomous driving, concerns about social bias in these systems are rising. Analysis of fairness in real-world vision systems, such as object detection in driving scenes, has been limited to observing predictive inequity across attributes such as pedestrian skin tone, and lacks a consistent methodology to disentangle the role of confounding variables e.g. does my model perform worse for a certain skin tone, or are such scenes in my dataset more challenging due to occlusion and crowds? In this work, we introduce ICON$^2$, a framework for robustly answering this question. ICON$^2$ leverages prior knowledge on the deficiencies of object detection systems to identify performance discrepancies across sub-populations, compute correlations between these potential confounders and a given sensitive attribute, and control for the most likely confounders to obtain a more reliable estimate of model bias. Using our approach, we conduct an in-depth study on the performance of object detection with respect to income from the BDD100K driving dataset, revealing useful insights.