 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Generators are Robot Policies
Aug 01, 2025Despite tremendous progress in dexterous manipulation, current visuomotor policies remain fundamentally limited by two challenges: they struggle to generalize under perceptual or behavioral distribution shifts, and their performance is constrained by the size of human demonstration data. In this paper, we use video generation as a proxy for robot policy learning to address both limitations simultaneously. We propose Video Policy, a modular framework that combines video and action generation that can be trained end-to-end. Our results demonstrate that learning to generate videos of robot behavior allows for the extraction of policies with minimal demonstration data, significantly improving robustness and sample efficiency. Our method shows strong generalization to unseen objects, backgrounds, and tasks, both in simulation and the real world. We further highlight that task success is closely tied to the generated video, with action-free video data providing critical benefits for generalizing to novel tasks. By leveraging large-scale video generative models, we achieve superior performance compared to traditional behavior cloning, paving the way for more scalable and data-efficient robot policy learning.
Controlling the World by Sleight of Hand
Aug 13, 2024



Humans naturally build mental models of object interactions and dynamics, allowing them to imagine how their surroundings will change if they take a certain action. While generative models today have shown impressive results on generating/editing images unconditionally or conditioned on text, current methods do not provide the ability to perform object manipulation conditioned on actions, an important tool for world modeling and action planning. Therefore, we propose to learn an action-conditional generative models by learning from unlabeled videos of human hands interacting with objects. The vast quantity of such data on the internet allows for efficient scaling which can enable high-performing action-conditional models. Given an image, and the shape/location of a desired hand interaction, CosHand, synthesizes an image of a future after the interaction has occurred. Experiments show that the resulting model can predict the effects of hand-object interactions well, with strong generalization particularly to translation, stretching, and squeezing interactions of unseen objects in unseen environments. Further, CosHand can be sampled many times to predict multiple possible effects, modeling the uncertainty of forces in the interaction/environment. Finally, method generalizes to different embodiments, including non-human hands, i.e. robot hands, suggesting that generative video models can be powerful models for robotics.
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Jun 24, 2024



A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
PaperBot: Learning to Design Real-World Tools Using Paper
Mar 14, 2024


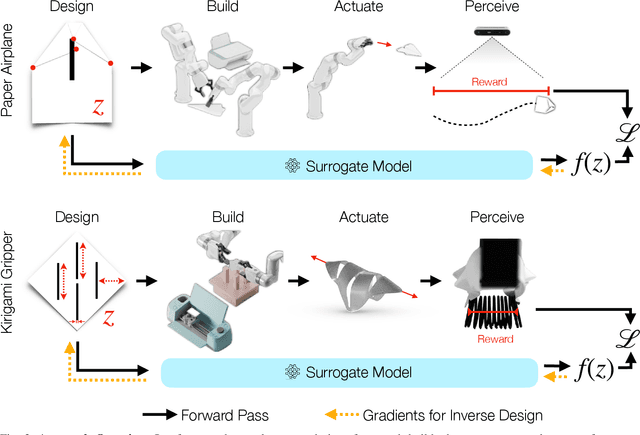
Paper is a cheap, recyclable, and clean material that is often used to make practical tools. Traditional tool design either relies on simulation or physical analysis, which is often inaccurate and time-consuming. In this paper, we propose PaperBot, an approach that directly learns to design and use a tool in the real world using paper without human intervention. We demonstrated the effectiveness and efficiency of PaperBot on two tool design tasks: 1. learning to fold and throw paper airplanes for maximum travel distance 2. learning to cut paper into grippers that exert maximum gripping force. We present a self-supervised learning framework that learns to perform a sequence of folding, cutting, and dynamic manipulation actions in order to optimize the design and use of a tool. We deploy our system to a real-world two-arm robotic system to solve challenging design tasks that involve aerodynamics (paper airplane) and friction (paper gripper) that are impossible to simulate accurately.
ICON$^2$: Reliably Benchmarking Predictive Inequity in Object Detection
Jun 07, 2023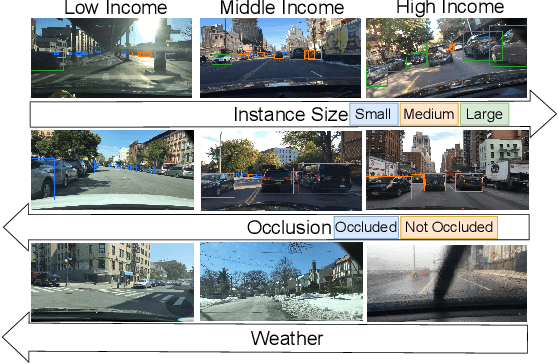
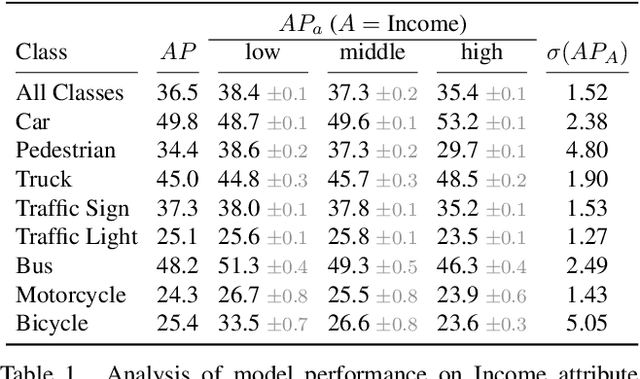
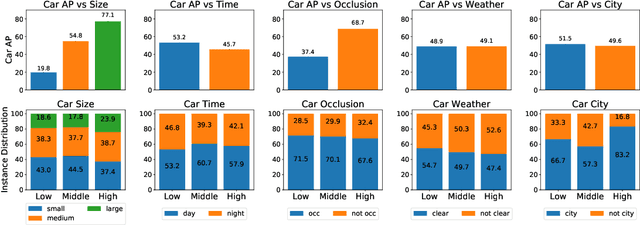
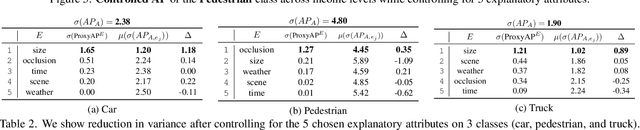
As computer vision systems are being increasingly deployed at scale in high-stakes applications like autonomous driving, concerns about social bias in these systems are rising. Analysis of fairness in real-world vision systems, such as object detection in driving scenes, has been limited to observing predictive inequity across attributes such as pedestrian skin tone, and lacks a consistent methodology to disentangle the role of confounding variables e.g. does my model perform worse for a certain skin tone, or are such scenes in my dataset more challenging due to occlusion and crowds? In this work, we introduce ICON$^2$, a framework for robustly answering this question. ICON$^2$ leverages prior knowledge on the deficiencies of object detection systems to identify performance discrepancies across sub-populations, compute correlations between these potential confounders and a given sensitive attribute, and control for the most likely confounders to obtain a more reliable estimate of model bias. Using our approach, we conduct an in-depth study on the performance of object detection with respect to income from the BDD100K driving dataset, revealing useful insights.
Mitigating Bias in Visual Transformers via Targeted Alignment
Feb 08, 2023As transformer architectures become increasingly prevalent in computer vision, it is critical to understand their fairness implications. We perform the first study of the fairness of transformers applied to computer vision and benchmark several bias mitigation approaches from prior work. We visualize the feature space of the transformer self-attention modules and discover that a significant portion of the bias is encoded in the query matrix. With this knowledge, we propose TADeT, a targeted alignment strategy for debiasing transformers that aims to discover and remove bias primarily from query matrix features. We measure performance using Balanced Accuracy and Standard Accuracy, and fairness using Equalized Odds and Balanced Accuracy Difference. TADeT consistently leads to improved fairness over prior work on multiple attribute prediction tasks on the CelebA dataset, without compromising performance.
UDIS: Unsupervised Discovery of Bias in Deep Visual Recognition Models
Oct 29, 2021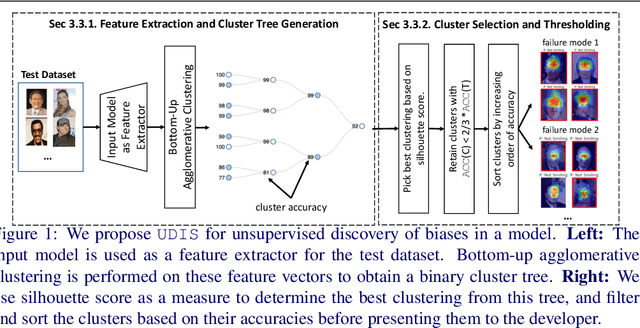


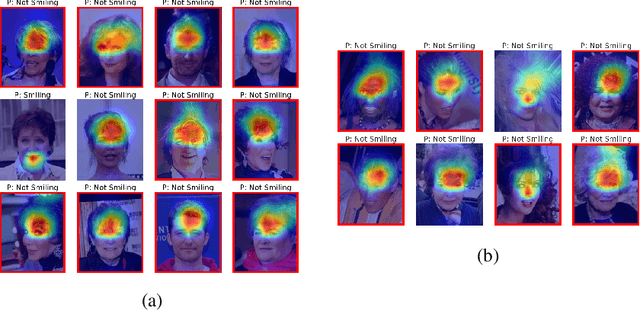
Deep learning models have been shown to learn spurious correlations from data that sometimes lead to systematic failures for certain subpopulations. Prior work has typically diagnosed this by crowdsourcing annotations for various protected attributes and measuring performance, which is both expensive to acquire and difficult to scale. In this work, we propose UDIS, an unsupervised algorithm for surfacing and analyzing such failure modes. UDIS identifies subpopulations via hierarchical clustering of dataset embeddings and surfaces systematic failure modes by visualizing low performing clusters along with their gradient-weighted class-activation maps. We show the effectiveness of UDIS in identifying failure modes in models trained for image classification on the CelebA and MSCOCO datasets.