 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Optical Flow Prediction Improves Robot Control & Video Generation
Jan 15, 2026Future motion representations, such as optical flow, offer immense value for control and generative tasks. However, forecasting generalizable spatially dense motion representations remains a key challenge, and learning such forecasting from noisy, real-world data remains relatively unexplored. We introduce FOFPred, a novel language-conditioned optical flow forecasting model featuring a unified Vision-Language Model (VLM) and Diffusion architecture. This unique combination enables strong multimodal reasoning with pixel-level generative fidelity for future motion prediction. Our model is trained on web-scale human activity data-a highly scalable but unstructured source. To extract meaningful signals from this noisy video-caption data, we employ crucial data preprocessing techniques and our unified architecture with strong image pretraining. The resulting trained model is then extended to tackle two distinct downstream tasks in control and generation. Evaluations across robotic manipulation and video generation under language-driven settings establish the cross-domain versatility of FOFPred, confirming the value of a unified VLM-Diffusion architecture and scalable learning from diverse web data for future optical flow prediction.
Robotic VLA Benefits from Joint Learning with Motion Image Diffusion
Dec 19, 2025Vision-Language-Action (VLA) models have achieved remarkable progress in robotic manipulation by mapping multimodal observations and instructions directly to actions. However, they typically mimic expert trajectories without predictive motion reasoning, which limits their ability to reason about what actions to take. To address this limitation, we propose joint learning with motion image diffusion, a novel strategy that enhances VLA models with motion reasoning capabilities. Our method extends the VLA architecture with a dual-head design: while the action head predicts action chunks as in vanilla VLAs, an additional motion head, implemented as a Diffusion Transformer (DiT), predicts optical-flow-based motion images that capture future dynamics. The two heads are trained jointly, enabling the shared VLM backbone to learn representations that couple robot control with motion knowledge. This joint learning builds temporally coherent and physically grounded representations without modifying the inference pathway of standard VLAs, thereby maintaining test-time latency. Experiments in both simulation and real-world environments demonstrate that joint learning with motion image diffusion improves the success rate of pi-series VLAs to 97.5% on the LIBERO benchmark and 58.0% on the RoboTwin benchmark, yielding a 23% improvement in real-world performance and validating its effectiveness in enhancing the motion reasoning capability of large-scale VLAs.
Strefer: Empowering Video LLMs with Space-Time Referring and Reasoning via Synthetic Instruction Data
Sep 03, 2025



Next-generation AI companions must go beyond general video understanding to resolve spatial and temporal references in dynamic, real-world environments. Existing Video Large Language Models (Video LLMs), while capable of coarse-level comprehension, struggle with fine-grained, spatiotemporal reasoning, especially when user queries rely on time-based event references for temporal anchoring, or gestural cues for spatial anchoring to clarify object references and positions. To bridge this critical gap, we introduce Strefer, a synthetic instruction data generation framework designed to equip Video LLMs with spatiotemporal referring and reasoning capabilities. Strefer produces diverse instruction-tuning data using a data engine that pseudo-annotates temporally dense, fine-grained video metadata, capturing rich spatial and temporal information in a structured manner, including subjects, objects, their locations as masklets, and their action descriptions and timelines. Our approach enhances the ability of Video LLMs to interpret spatial and temporal references, fostering more versatile, space-time-aware reasoning essential for real-world AI companions. Without using proprietary models, costly human annotation, or the need to annotate large volumes of new videos, experimental evaluations show that models trained with data produced by Strefer outperform baselines on tasks requiring spatial and temporal disambiguation. Additionally, these models exhibit enhanced space-time-aware reasoning, establishing a new foundation for perceptually grounded, instruction-tuned Video LLMs.
CASIM: Composite Aware Semantic Injection for Text to Motion Generation
Feb 04, 2025Recent advances in generative modeling and tokenization have driven significant progress in text-to-motion generation, leading to enhanced quality and realism in generated motions. However, effectively leveraging textual information for conditional motion generation remains an open challenge. We observe that current approaches, primarily relying on fixed-length text embeddings (e.g., CLIP) for global semantic injection, struggle to capture the composite nature of human motion, resulting in suboptimal motion quality and controllability. To address this limitation, we propose the Composite Aware Semantic Injection Mechanism (CASIM), comprising a composite-aware semantic encoder and a text-motion aligner that learns the dynamic correspondence between text and motion tokens. Notably, CASIM is model and representation-agnostic, readily integrating with both autoregressive and diffusion-based methods. Experiments on HumanML3D and KIT benchmarks demonstrate that CASIM consistently improves motion quality, text-motion alignment, and retrieval scores across state-of-the-art methods. Qualitative analyses further highlight the superiority of our composite-aware approach over fixed-length semantic injection, enabling precise motion control from text prompts and stronger generalization to unseen text inputs.
Unifying Specialized Visual Encoders for Video Language Models
Jan 02, 2025



The recent advent of Large Language Models (LLMs) has ushered sophisticated reasoning capabilities into the realm of video through Video Large Language Models (VideoLLMs). However, VideoLLMs currently rely on a single vision encoder for all of their visual processing, which limits the amount and type of visual information that can be conveyed to the LLM. Our method, MERV, Multi-Encoder Representation of Videos, instead leverages multiple frozen visual encoders to create a unified representation of a video, providing the VideoLLM with a comprehensive set of specialized visual knowledge. Spatio-temporally aligning the features from each encoder allows us to tackle a wider range of open-ended and multiple-choice video understanding questions and outperform prior state-of-the-art works. MERV is up to 3.7% better in accuracy than Video-LLaVA across the standard suite video understanding benchmarks, while also having a better Video-ChatGPT score. We also improve upon SeViLA, the previous best on zero-shot Perception Test accuracy, by 2.2%. MERV introduces minimal extra parameters and trains faster than equivalent single-encoder methods while parallelizing the visual processing. Finally, we provide qualitative evidence that MERV successfully captures domain knowledge from each of its encoders. Our results offer promising directions in utilizing multiple vision encoders for comprehensive video understanding.
ViUniT: Visual Unit Tests for More Robust Visual Programming
Dec 12, 2024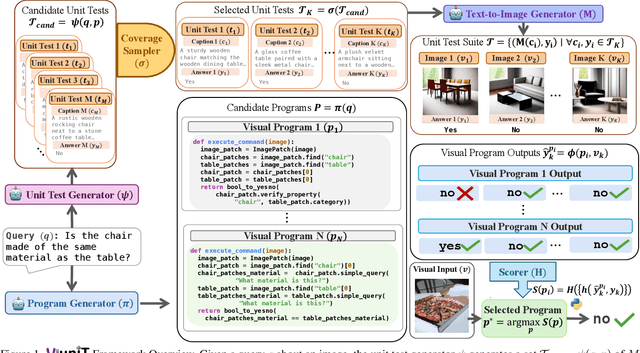
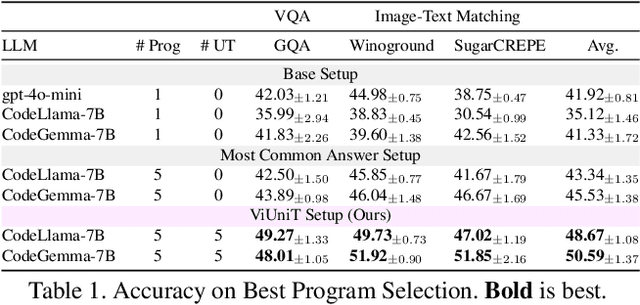
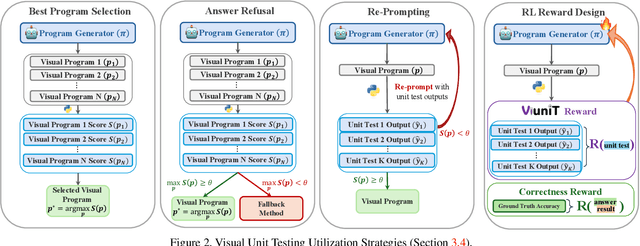
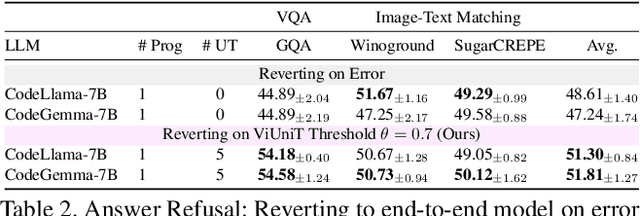
Programming based approaches to reasoning tasks have substantially expanded the types of questions models can answer about visual scenes. Yet on benchmark visual reasoning data, when models answer correctly, they produce incorrect programs 33% of the time. These models are often right for the wrong reasons and risk unexpected failures on new data. Unit tests play a foundational role in ensuring code correctness and could be used to repair such failures. We propose Visual Unit Testing (ViUniT), a framework to improve the reliability of visual programs by automatically generating unit tests. In our framework, a unit test is represented as a novel image and answer pair meant to verify the logical correctness of a program produced for a given query. Our method leverages a language model to create unit tests in the form of image descriptions and expected answers and image synthesis to produce corresponding images. We conduct a comprehensive analysis of what constitutes an effective visual unit test suite, exploring unit test generation, sampling strategies, image generation methods, and varying the number of programs and unit tests. Additionally, we introduce four applications of visual unit tests: best program selection, answer refusal, re-prompting, and unsupervised reward formulations for reinforcement learning. Experiments with two models across three datasets in visual question answering and image-text matching demonstrate that ViUniT improves model performance by 11.4%. Notably, it enables 7B open-source models to outperform gpt-4o-mini by an average of 7.7% and reduces the occurrence of programs that are correct for the wrong reasons by 40%.
xGen-MM-Vid (BLIP-3-Video): You Only Need 32 Tokens to Represent a Video Even in VLMs
Oct 21, 2024



We present xGen-MM-Vid (BLIP-3-Video): a multimodal language model for videos, particularly designed to efficiently capture temporal information over multiple frames. BLIP-3-Video takes advantage of the 'temporal encoder' in addition to the conventional visual tokenizer, which maps a sequence of tokens over multiple frames into a compact set of visual tokens. This enables BLIP3-Video to use much fewer visual tokens than its competing models (e.g., 32 vs. 4608 tokens). We explore different types of temporal encoders, including learnable spatio-temporal pooling as well as sequential models like Token Turing Machines. We experimentally confirm that BLIP-3-Video obtains video question-answering accuracies comparable to much larger state-of-the-art models (e.g., 34B), while being much smaller (i.e., 4B) and more efficient by using fewer visual tokens. The project website is at https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
Domain-Guided Weight Modulation for Semi-Supervised Domain Generalization
Sep 04, 2024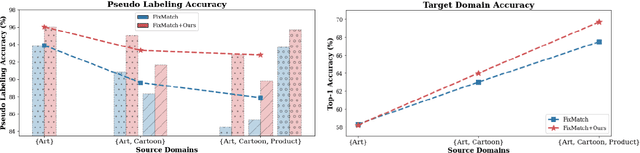
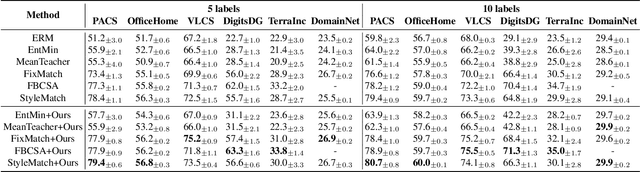
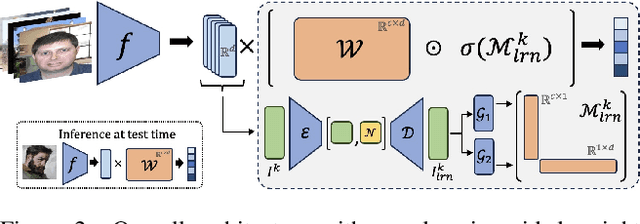

Unarguably, deep learning models capable of generalizing to unseen domain data while leveraging a few labels are of great practical significance due to low developmental costs. In search of this endeavor, we study the challenging problem of semi-supervised domain generalization (SSDG), where the goal is to learn a domain-generalizable model while using only a small fraction of labeled data and a relatively large fraction of unlabeled data. Domain generalization (DG) methods show subpar performance under the SSDG setting, whereas semi-supervised learning (SSL) methods demonstrate relatively better performance, however, they are considerably poor compared to the fully-supervised DG methods. Towards handling this new, but challenging problem of SSDG, we propose a novel method that can facilitate the generation of accurate pseudo-labels under various domain shifts. This is accomplished by retaining the domain-level specialism in the classifier during training corresponding to each source domain. Specifically, we first create domain-level information vectors on the fly which are then utilized to learn a domain-aware mask for modulating the classifier's weights. We provide a mathematical interpretation for the effect of this modulation procedure on both pseudo-labeling and model training. Our method is plug-and-play and can be readily applied to different SSL baselines for SSDG. Extensive experiments on six challenging datasets in two different SSDG settings show that our method provides visible gains over the various strong SSL-based SSDG baselines.
xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations
Aug 22, 2024



We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI's Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE). VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments. Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs. The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.
xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
Aug 16, 2024



This report introduces xGen-MM (also known as BLIP-3), a framework for developing Large Multimodal Models (LMMs). The framework comprises meticulously curated datasets, a training recipe, model architectures, and a resulting suite of LMMs. xGen-MM, short for xGen-MultiModal, expands the Salesforce xGen initiative on foundation AI models. Our models undergo rigorous evaluation across a range of tasks, including both single and multi-image benchmarks. Our pre-trained base model exhibits strong in-context learning capabilities and the instruction-tuned model demonstrates competitive performance among open-source LMMs with similar model sizes. In addition, we introduce a safety-tuned model with DPO, aiming to mitigate harmful behaviors such as hallucinations and improve safety. We open-source our models, curated large-scale datasets, and our fine-tuning codebase to facilitate further advancements in LMM research. Associated resources will be available on our project page above.