 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASIM: Composite Aware Semantic Injection for Text to Motion Generation
Feb 04, 2025Recent advances in generative modeling and tokenization have driven significant progress in text-to-motion generation, leading to enhanced quality and realism in generated motions. However, effectively leveraging textual information for conditional motion generation remains an open challenge. We observe that current approaches, primarily relying on fixed-length text embeddings (e.g., CLIP) for global semantic injection, struggle to capture the composite nature of human motion, resulting in suboptimal motion quality and controllability. To address this limitation, we propose the Composite Aware Semantic Injection Mechanism (CASIM), comprising a composite-aware semantic encoder and a text-motion aligner that learns the dynamic correspondence between text and motion tokens. Notably, CASIM is model and representation-agnostic, readily integrating with both autoregressive and diffusion-based methods. Experiments on HumanML3D and KIT benchmarks demonstrate that CASIM consistently improves motion quality, text-motion alignment, and retrieval scores across state-of-the-art methods. Qualitative analyses further highlight the superiority of our composite-aware approach over fixed-length semantic injection, enabling precise motion control from text prompts and stronger generalization to unseen text inputs.
From Words to Worlds: Transforming One-line Prompt into Immersive Multi-modal Digital Stories with Communicative LLM Agent
Jun 15, 2024



Digital storytelling, essential in entertainment, education, and marketing, faces challenges in production scalability and flexibility. The StoryAgent framework, introduced in this paper, utilizes Large Language Models and generative tools to automate and refine digital storytelling. Employing a top-down story drafting and bottom-up asset generation approach, StoryAgent tackles key issues such as manual intervention, interactive scene orchestration, and narrative consistency. This framework enables efficient production of interactive and consistent narratives across multiple modalities, democratizing content creation and enhancing engagement. Our results demonstrate the framework's capability to produce coherent digital stories without reference videos, marking a significant advancement in automated digital storytelling.
BattleAgent: Multi-modal Dynamic Emulation on Historical Battles to Complement Historical Analysis
Apr 23, 2024



This paper presents BattleAgent, an emulation system that combines the Large Vision-Language Model and Multi-agent System. This novel system aims to simulate complex dynamic interactions among multiple agents, as well as between agents and their environments, over a period of time. It emulates both the decision-making processes of leaders and the viewpoints of ordinary participants, such as soldiers. The emulation showcases the current capabilities of agents, featuring fine-grained multi-modal interactions between agents and landscapes. It develops customizable agent structures to meet specific situational requirements, for example, a variety of battle-related activities like scouting and trench digging. These components collaborate to recreate historical events in a lively and comprehensive manner while offering insights into the thoughts and feelings of individuals from diverse viewpoints. The technological foundations of BattleAgent establish detailed and immersive settings for historical battles, enabling individual agents to partake in, observe, and dynamically respond to evolving battle scenarios. This methodology holds the potential to substantially deepen our understanding of historical events, particularly through individual accounts. Such initiatives can also aid historical research, as conventional historical narratives often lack documentation and prioritize the perspectives of decision-makers, thereby overlooking the experiences of ordinary individuals. BattelAgent illustrates AI's potential to revitalize the human aspect in crucial social events, thereby fostering a more nuanced collective understanding and driving the progressive development of human society.
On the Equivalency, Substitutability, and Flexibility of Synthetic Data
Mar 24, 2024We study, from an empirical standpoint, the efficacy of synthetic data in real-world scenarios. Leveraging synthetic data for training perception models has become a key strategy embraced by the community due to its efficiency, scalability, perfect annotations, and low costs. Despite proven advantages, few studies put their stress on how to efficiently generate synthetic datasets to solve real-world problems and to what extent synthetic data can reduce the effort for real-world data collection. To answer the questions, we systematically investigate several interesting properties of synthetic data -- the equivalency of synthetic data to real-world data, the substitutability of synthetic data for real data, and the flexibility of synthetic data generators to close up domain gaps. Leveraging the M3Act synthetic data generator, we conduct experiments on DanceTrack and MOT17. Our results suggest that synthetic data not only enhances model performance but also demonstrates substitutability for real data, with 60% to 80% replacement without performance loss. In addition, our study of the impact of synthetic data distributions on downstream performance reveals the importance of flexible data generators in narrowing domain gaps for improved model adaptability.
The Importance of Multimodal Emotion Conditioning and Affect Consistency for Embodied Conversational Agents
Sep 26, 2023



Previous studies regarding the perception of emotions for embodied virtual agents have shown the effectiveness of using virtual characters in conveying emotions through interactions with humans. However, creating an autonomous embodied conversational agent with expressive behaviors presents two major challenges. The first challenge is the difficulty of synthesizing the conversational behaviors for each modality that are as expressive as real human behaviors. The second challenge is that the affects are modeled independently, which makes it difficult to generate multimodal responses with consistent emotions across all modalities. In this work, we propose a conceptual framework, ACTOR (Affect-Consistent mulTimodal behaviOR generation), that aims to increase the perception of affects by generating multimodal behaviors conditioned on a consistent driving affect. We have conducted a user study with 199 participants to assess how the average person judges the affects perceived from multimodal behaviors that are consistent and inconsistent with respect to a driving affect. The result shows that among all model conditions, our affect-consistent framework receives the highest Likert scores for the perception of driving affects. Our statistical analysis suggests that making a modality affect-inconsistent significantly decreases the perception of driving affects. We also observe that multimodal behaviors conditioned on consistent affects are more expressive compared to behaviors with inconsistent affects. Therefore, we conclude that multimodal emotion conditioning and affect consistency are vital to enhancing the perception of affects for embodied conversational agents.
Learning from Synthetic Human Group Activities
Jul 16, 2023
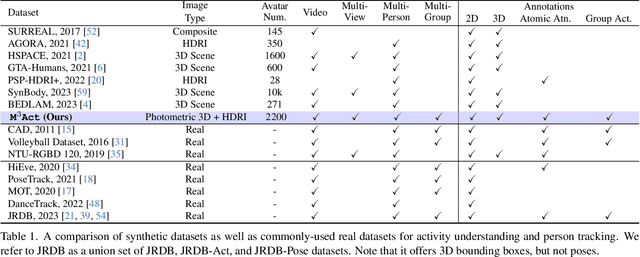
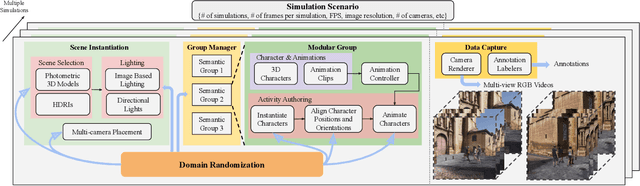
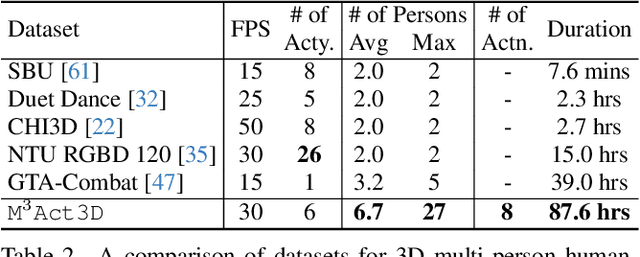
The understanding of complex human interactions and group activities has garnered attention in human-centric computer vision. However, the advancement of the related tasks is hindered due to the difficulty of obtaining large-scale labeled real-world datasets. To mitigate the issue, we propose M3Act, a multi-view multi-group multi-person human atomic action and group activity data generator. Powered by the Unity engine, M3Act contains simulation-ready 3D scenes and human assets, configurable lighting and camera systems, highly parameterized modular group activities, and a large degree of domain randomization during the data generation process. Our data generator is capable of generating large-scale datasets of human activities with multiple viewpoints, modalities (RGB images, 2D poses, 3D motions), and high-quality annotations for individual persons and multi-person groups (2D bounding boxes, instance segmentation masks, individual actions and group activity categories). Using M3Act, we perform synthetic data pre-training for 2D skeleton-based group activity recognition and RGB-based multi-person pose tracking. The results indicate that learning from our synthetic datasets largely improves the model performances on real-world datasets, with the highest gain of 5.59% and 7.32% respectively in group and person recognition accuracy on CAD2, as well as an improvement of 6.63 in MOTP on HiEve. Pre-training with our synthetic data also leads to faster model convergence on downstream tasks (up to 6.8% faster). Moreover, M3Act opens new research problems for 3D group activity generation. We release M3Act3D, an 87.6-hour 3D motion dataset of human activities with larger group sizes and higher complexity of inter-person interactions than previous multi-person datasets. We define multiple metrics and propose a competitive baseline for the novel task.
Transfer Learning from Monolingual ASR to Transcription-free Cross-lingual Voice Conversion
Sep 30, 2020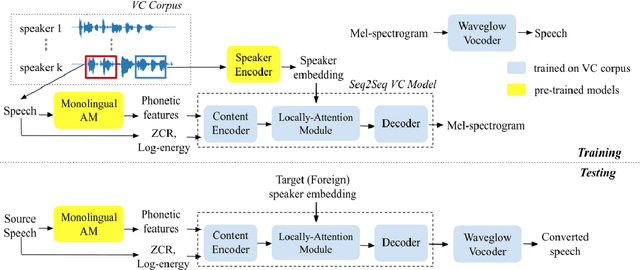
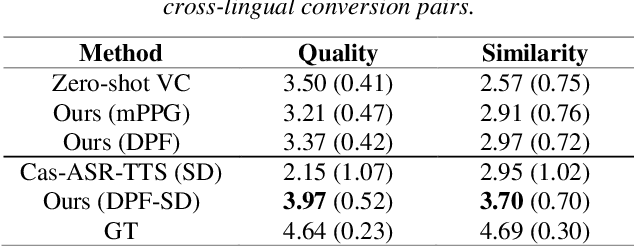

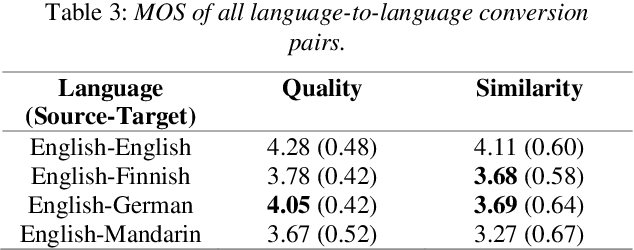
Cross-lingual voice conversion (VC) is a task that aims to synthesize target voices with the same content while source and target speakers speak in different languages. Its challenge lies in the fact that the source and target data are naturally non-parallel, and it is even difficult to bridge the gaps between languages with no transcriptions provided. In this paper, we focus on knowledge transfer from monolin-gual ASR to cross-lingual VC, in order to address the con-tent mismatch problem. To achieve this, we first train a monolingual acoustic model for the source language, use it to extract phonetic features for all the speech in the VC dataset, and then train a Seq2Seq conversion model to pre-dict the mel-spectrograms. We successfully address cross-lingual VC without any transcription or language-specific knowledge for foreign speech. We experiment this on Voice Conversion Challenge 2020 datasets and show that our speaker-dependent conversion model outperforms the zero-shot baseline, achieving MOS of 3.83 and 3.54 in speech quality and speaker similarity for cross-lingual conversion. When compared to Cascade ASR-TTS method, our proposed one significantly reduces the MOS drop be-tween intra- and cross-lingual conversion.