 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
SPARC: Separating Perception And Reasoning Circuits for Test-time Scaling of VLMs
Feb 06, 2026Despite recent successes, test-time scaling - i.e., dynamically expanding the token budget during inference as needed - remains brittle for vision-language models (VLMs): unstructured chains-of-thought about images entangle perception and reasoning, leading to long, disorganized contexts where small perceptual mistakes may cascade into completely wrong answers. Moreover, expensive reinforcement learning with hand-crafted rewards is required to achieve good performance. Here, we introduce SPARC (Separating Perception And Reasoning Circuits), a modular framework that explicitly decouples visual perception from reasoning. Inspired by sequential sensory-to-cognitive processing in the brain, SPARC implements a two-stage pipeline where the model first performs explicit visual search to localize question-relevant regions, then conditions its reasoning on those regions to produce the final answer. This separation enables independent test-time scaling with asymmetric compute allocation (e.g., prioritizing perceptual processing under distribution shift), supports selective optimization (e.g., improving the perceptual stage alone when it is the bottleneck for end-to-end performance), and accommodates compressed contexts by running global search at lower image resolutions and allocating high-resolution processing only to selected regions, thereby reducing total visual tokens count and compute. Across challenging visual reasoning benchmarks, SPARC outperforms monolithic baselines and strong visual-grounding approaches. For instance, SPARC improves the accuracy of Qwen3VL-4B on the $V^*$ VQA benchmark by 6.7 percentage points, and it surpasses "thinking with images" by 4.6 points on a challenging OOD task despite requiring a 200$\times$ lower token budget.
DAVE: A VLM Vision Encoder for Document Understanding and Web Agents
Dec 19, 2025While Vision-language models (VLMs) have demonstrated remarkable performance across multi-modal tasks, their choice of vision encoders presents a fundamental weakness: their low-level features lack the robust structural and spatial information essential for document understanding and web agents. To bridge this gap, we introduce DAVE, a vision encoder purpose-built for VLMs and tailored for these tasks. Our training pipeline is designed to leverage abundant unlabeled data to bypass the need for costly large-scale annotations for document and web images. We begin with a self-supervised pretraining stage on unlabeled images, followed by a supervised autoregressive pretraining stage, where the model learns tasks like parsing and localization from limited, high-quality data. Within the supervised stage, we adopt two strategies to improve our encoder's alignment with both general visual knowledge and diverse document and web agentic tasks: (i) We introduce a novel model-merging scheme, combining encoders trained with different text decoders to ensure broad compatibility with different web agentic architectures. (ii) We use ensemble training to fuse features from pretrained generalist encoders (e.g., SigLIP2) with our own document and web-specific representations. Extensive experiments on classic document tasks, VQAs, web localization, and agent-based benchmarks validate the effectiveness of our approach, establishing DAVE as a strong vision encoder for document and web applications.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025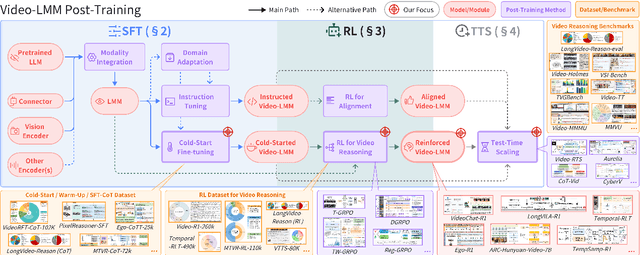
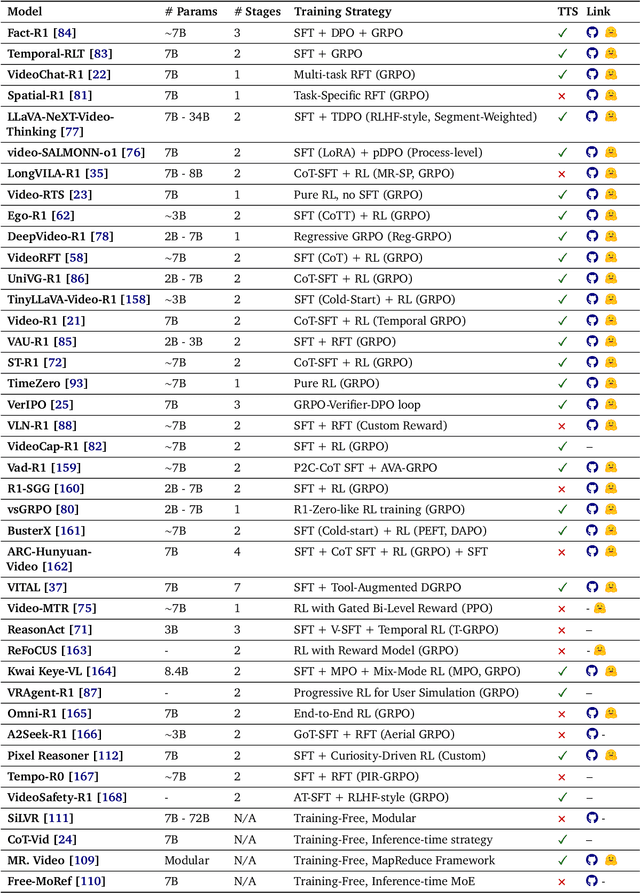
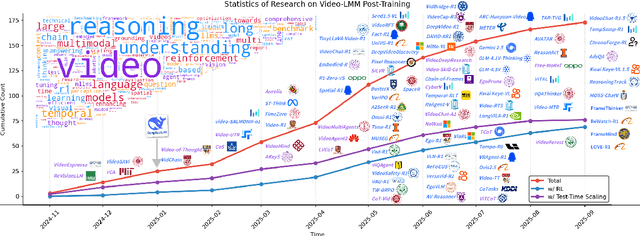
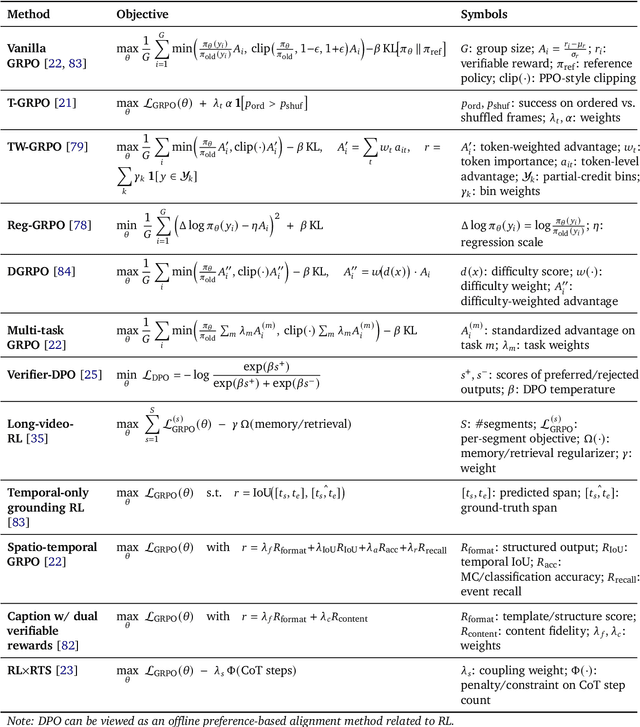
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
MMIG-Bench: Towards Comprehensive and Explainable Evaluation of Multi-Modal Image Generation Models
May 26, 2025Recent multimodal image generators such as GPT-4o, Gemini 2.0 Flash, and Gemini 2.5 Pro excel at following complex instructions, editing images and maintaining concept consistency. However, they are still evaluated by disjoint toolkits: text-to-image (T2I) benchmarks that lacks multi-modal conditioning, and customized image generation benchmarks that overlook compositional semantics and common knowledge. We propose MMIG-Bench, a comprehensive Multi-Modal Image Generation Benchmark that unifies these tasks by pairing 4,850 richly annotated text prompts with 1,750 multi-view reference images across 380 subjects, spanning humans, animals, objects, and artistic styles. MMIG-Bench is equipped with a three-level evaluation framework: (1) low-level metrics for visual artifacts and identity preservation of objects; (2) novel Aspect Matching Score (AMS): a VQA-based mid-level metric that delivers fine-grained prompt-image alignment and shows strong correlation with human judgments; and (3) high-level metrics for aesthetics and human preference. Using MMIG-Bench, we benchmark 17 state-of-the-art models, including Gemini 2.5 Pro, FLUX, DreamBooth, and IP-Adapter, and validate our metrics with 32k human ratings, yielding in-depth insights into architecture and data design. We will release the dataset and evaluation code to foster rigorous, unified evaluation and accelerate future innovations in multi-modal image generation.
MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness
May 26, 2025Understanding perspective is fundamental to human visual perception, yet the extent to which multimodal large language models (MLLMs) internalize perspective geometry remains unclear. We introduce MMPerspective, the first benchmark specifically designed to systematically evaluate MLLMs' understanding of perspective through 10 carefully crafted tasks across three complementary dimensions: Perspective Perception, Reasoning, and Robustness. Our benchmark comprises 2,711 real-world and synthetic image instances with 5,083 question-answer pairs that probe key capabilities, such as vanishing point perception and counting, perspective type reasoning, line relationship understanding in 3D space, invariance to perspective-preserving transformations, etc. Through a comprehensive evaluation of 43 state-of-the-art MLLMs, we uncover significant limitations: while models demonstrate competence on surface-level perceptual tasks, they struggle with compositional reasoning and maintaining spatial consistency under perturbations. Our analysis further reveals intriguing patterns between model architecture, scale, and perspective capabilities, highlighting both robustness bottlenecks and the benefits of chain-of-thought prompting. MMPerspective establishes a valuable testbed for diagnosing and advancing spatial understanding in vision-language systems. Resources available at: https://yunlong10.github.io/MMPerspective/
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
Generative AI for Cel-Animation: A Survey
Jan 08, 2025



Traditional Celluloid (Cel) Animation production pipeline encompasses multiple essential steps, including storyboarding, layout design, keyframe animation, inbetweening, and colorization, which demand substantial manual effort, technical expertise, and significant time investment. These challenges have historically impeded the efficiency and scalability of Cel-Animation production. The rise of generative artificial intelligence (GenAI), encompassing large language models, multimodal models, and diffusion models, offers innovative solutions by automating tasks such as inbetween frame generation, colorization, and storyboard creation. This survey explores how GenAI integration is revolutionizing traditional animation workflows by lowering technical barriers, broadening accessibility for a wider range of creators through tools like AniDoc, ToonCrafter, and AniSora, and enabling artists to focus more on creative expression and artistic innovation. Despite its potential, issues such as maintaining visual consistency, ensuring stylistic coherence, and addressing ethical considerations continue to pose challenges. Furthermore, this paper discusses future directions and explores potential advancements in AI-assisted animation. For further exploration and resources, please visit our GitHub repository: https://github.com/yunlong10/Awesome-AI4Animation
FINECAPTION: Compositional Image Captioning Focusing on Wherever You Want at Any Granularity
Nov 23, 2024



The advent of large Vision-Language Models (VLMs) has significantly advanced multimodal tasks, enabling more sophisticated and accurate reasoning across various applications, including image and video captioning, visual question answering, and cross-modal retrieval. Despite their superior capabilities, VLMs struggle with fine-grained image regional composition information perception. Specifically, they have difficulty accurately aligning the segmentation masks with the corresponding semantics and precisely describing the compositional aspects of the referred regions. However, compositionality - the ability to understand and generate novel combinations of known visual and textual components - is critical for facilitating coherent reasoning and understanding across modalities by VLMs. To address this issue, we propose FINECAPTION, a novel VLM that can recognize arbitrary masks as referential inputs and process high-resolution images for compositional image captioning at different granularity levels. To support this endeavor, we introduce COMPOSITIONCAP, a new dataset for multi-grained region compositional image captioning, which introduces the task of compositional attribute-aware regional image captioning. Empirical results demonstrate the effectiveness of our proposed model compared to other state-of-the-art VLMs. Additionally, we analyze the capabilities of current VLMs in recognizing various visual prompts for compositional region image captioning, highlighting areas for improvement in VLM design and training.