 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoralBench: Moral Evaluation of LLMs
Jun 06, 2024



In the rapidly evolving field of artificial intelligence, large language models (LLMs) have emerged as powerful tools for a myriad of applications, from natural language processing to decision-making support systems. However, as these models become increasingly integrated into societal frameworks, the imperative to ensure they operate within ethical and moral boundaries has never been more critical. This paper introduces a novel benchmark designed to measure and compare the moral reasoning capabilities of LLMs. We present the first comprehensive dataset specifically curated to probe the moral dimensions of LLM outputs, addressing a wide range of ethical dilemmas and scenarios reflective of real-world complexities. The main contribution of this work lies in the development of benchmark datasets and metrics for assessing the moral identity of LLMs, which accounts for nuance, contextual sensitivity, and alignment with human ethical standards. Our methodology involves a multi-faceted approach, combining quantitative analysis with qualitative insights from ethics scholars to ensure a thorough evaluation of model performance. By applying our benchmark across several leading LLMs, we uncover significant variations in moral reasoning capabilities of different models. These findings highlight the importance of considering moral reasoning in the development and evaluation of LLMs, as well as the need for ongoing research to address the biases and limitations uncovered in our study. We publicly release the benchmark at https://drive.google.com/drive/u/0/folders/1k93YZJserYc2CkqP8d4B3M3sgd3kA8W7 and also open-source the code of the project at https://github.com/agiresearch/MoralBench.
BattleAgent: Multi-modal Dynamic Emulation on Historical Battles to Complement Historical Analysis
Apr 23, 2024



This paper presents BattleAgent, an emulation system that combines the Large Vision-Language Model and Multi-agent System. This novel system aims to simulate complex dynamic interactions among multiple agents, as well as between agents and their environments, over a period of time. It emulates both the decision-making processes of leaders and the viewpoints of ordinary participants, such as soldiers. The emulation showcases the current capabilities of agents, featuring fine-grained multi-modal interactions between agents and landscapes. It develops customizable agent structures to meet specific situational requirements, for example, a variety of battle-related activities like scouting and trench digging. These components collaborate to recreate historical events in a lively and comprehensive manner while offering insights into the thoughts and feelings of individuals from diverse viewpoints. The technological foundations of BattleAgent establish detailed and immersive settings for historical battles, enabling individual agents to partake in, observe, and dynamically respond to evolving battle scenarios. This methodology holds the potential to substantially deepen our understanding of historical events, particularly through individual accounts. Such initiatives can also aid historical research, as conventional historical narratives often lack documentation and prioritize the perspectives of decision-makers, thereby overlooking the experiences of ordinary individuals. BattelAgent illustrates AI's potential to revitalize the human aspect in crucial social events, thereby fostering a more nuanced collective understanding and driving the progressive development of human society.
PAP-REC: Personalized Automatic Prompt for Recommendation Language Model
Feb 01, 2024



Recently emerged prompt-based Recommendation Language Models (RLM) can solve multiple recommendation tasks uniformly. The RLMs make full use of the inherited knowledge learned from the abundant pre-training data to solve the downstream recommendation tasks by prompts, without introducing additional parameters or network training. However, handcrafted prompts require significant expertise and human effort since slightly rewriting prompts may cause massive performance changes. In this paper, we propose PAP-REC, a framework to generate the Personalized Automatic Prompt for RECommendation language models to mitigate the inefficiency and ineffectiveness problems derived from manually designed prompts. Specifically, personalized automatic prompts allow different users to have different prompt tokens for the same task, automatically generated using a gradient-based method. One challenge for personalized automatic prompt generation for recommendation language models is the extremely large search space, leading to a long convergence time. To effectively and efficiently address the problem, we develop surrogate metrics and leverage an alternative updating schedule for prompting recommendation language models. Experimental results show that our PAP-REC framework manages to generate personalized prompts, and the automatically generated prompts outperform manually constructed prompts and also outperform various baseline recommendation models. The source code of the work is available at https://github.com/rutgerswiselab/PAP-REC.
War and Peace : Large Language Model-based Multi-Agent Simulation of World Wars
Nov 28, 2023Can we avoid wars at the crossroads of history? This question has been pursued by individuals, scholars, policymakers, and organizations throughout human history. In this research, we attempt to answer the question based on the recent advances of Artificial Intelligence (AI) and Large Language Models (LLMs). We propose \textbf{WarAgent}, an LLM-powered multi-agent AI system, to simulate the participating countries, their decisions, and the consequences, in historical international conflicts, including the World War I (WWI), the World War II (WWII), and the Warring States Period (WSP) in Ancient China. By evaluating the simulation effectiveness, we examine the advancements and limitations of cutting-edge AI systems' abilities in studying complex collective human behaviors such as international conflicts under diverse settings. In these simulations, the emergent interactions among agents also offer a novel perspective for examining the triggers and conditions that lead to war. Our findings offer data-driven and AI-augmented insights that can redefine how we approach conflict resolution and peacekeeping strategies. The implications stretch beyond historical analysis, offering a blueprint for using AI to understand human history and possibly prevent future international conflicts. Code and data are available at \url{https://github.com/agiresearch/WarAgent}.
User-Controllable Recommendation via Counterfactual Retrospective and Prospective Explanations
Aug 02, 2023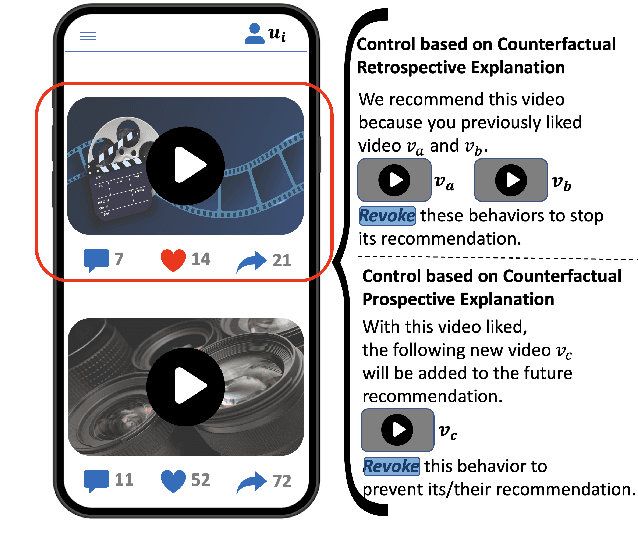
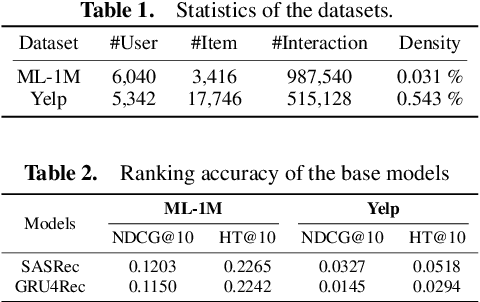
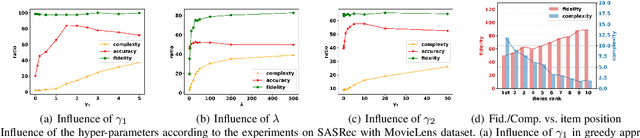
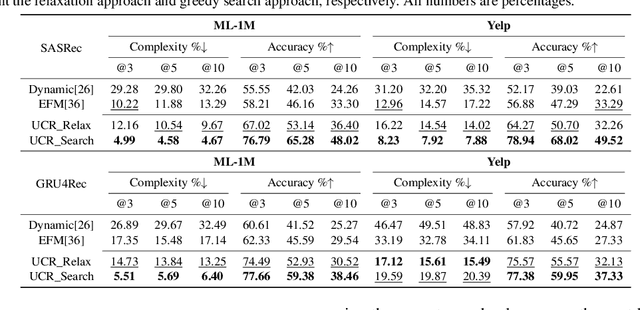
Modern recommender systems utilize users' historical behaviors to generate personalized recommendations. However, these systems often lack user controllability, leading to diminished user satisfaction and trust in the systems. Acknowledging the recent advancements in explainable recommender systems that enhance users' understanding of recommendation mechanisms, we propose leveraging these advancements to improve user controllability. In this paper, we present a user-controllable recommender system that seamlessly integrates explainability and controllability within a unified framework. By providing both retrospective and prospective explanations through counterfactual reasoning, users can customize their control over the system by interacting with these explanations. Furthermore, we introduce and assess two attributes of controllability in recommendation systems: the complexity of controllability and the accuracy of controllability. Experimental evaluations on MovieLens and Yelp datasets substantiate the effectiveness of our proposed framework. Additionally, our experiments demonstrate that offering users control options can potentially enhance recommendation accuracy in the future. Source code and data are available at \url{https://github.com/chrisjtan/ucr}.
GenRec: Large Language Model for Generative Recommendation
Jul 04, 2023In recent years, large language models (LLM) have emerged as powerful tools for diverse natural language processing tasks. However, their potential for recommender systems under the generative recommendation paradigm remains relatively unexplored. This paper presents an innovative approach to recommendation systems using large language models (LLMs) based on text data. In this paper, we present a novel LLM for generative recommendation (GenRec) that utilized the expressive power of LLM to directly generate the target item to recommend, rather than calculating ranking score for each candidate item one by one as in traditional discriminative recommendation. GenRec uses LLM's understanding ability to interpret context, learn user preferences, and generate relevant recommendation. Our proposed approach leverages the vast knowledge encoded in large language models to accomplish recommendation tasks. We first we formulate specialized prompts to enhance the ability of LLM to comprehend recommendation tasks. Subsequently, we use these prompts to fine-tune the LLaMA backbone LLM on a dataset of user-item interactions, represented by textual data, to capture user preferences and item characteristics. Our research underscores the potential of LLM-based generative recommendation in revolutionizing the domain of recommendation systems and offers a foundational framework for future explorations in this field. We conduct extensive experiments on benchmark datasets, and the experiments shows that our GenRec has significant better results on large dataset.
Counterfactual Collaborative Reasoning
Jun 30, 2023Causal reasoning and logical reasoning are two important types of reasoning abilities for human intelligence. However, their relationship has not been extensively explored under machine intelligence context. In this paper, we explore how the two reasoning abilities can be jointly modeled to enhance both accuracy and explainability of machine learning models. More specifically, by integrating two important types of reasoning ability -- counterfactual reasoning and (neural) logical reasoning -- we propose Counterfactual Collaborative Reasoning (CCR), which conducts counterfactual logic reasoning to improve the performance. In particular, we use recommender system as an example to show how CCR alleviate data scarcity, improve accuracy and enhance transparency. Technically, we leverage counterfactual reasoning to generate "difficult" counterfactual training examples for data augmentation, which -- together with the original training examples -- can enhance the model performance. Since the augmented data is model irrelevant, they can be used to enhance any model, enabling the wide applicability of the technique. Besides, most of the existing data augmentation methods focus on "implicit data augmentation" over users' implicit feedback, while our framework conducts "explicit data augmentation" over users explicit feedback based on counterfactual logic reasoning. Experiments on three real-world datasets show that CCR achieves better performance than non-augmented models and implicitly augmented models, and also improves model transparency by generating counterfactual explanations.
UP5: Unbiased Foundation Model for Fairness-aware Recommendation
May 20, 2023



Recent advancements in foundation models such as large language models (LLM) have propelled them to the forefront of recommender systems (RS). Moreover, fairness in RS is critical since many users apply it for decision-making and demand fulfillment. However, at present, there is a lack of understanding regarding the level of fairness exhibited by recommendation foundation models and the appropriate methods for equitably treating different groups of users in foundation models. In this paper, we focus on user-side unfairness problem and show through a thorough examination that there is unfairness involved in LLMs that lead to unfair recommendation results. To eliminate bias from LLM for fairness-aware recommendation, we introduce a novel Unbiased P5 (UP5) foundation model based on Counterfactually-Fair-Prompting (CFP) techniques. CFP includes two sub-modules: a personalized prefix prompt that enhances fairness with respect to individual sensitive attributes, and a Prompt Mixture that integrates multiple counterfactually-fair prompts for a set of sensitive attributes. Experiments are conducted on two real-world datasets, MovieLens-1M and Insurance, and results are compared with both matching-based and sequential-based fairness-aware recommendation models. The results show that UP5 achieves better recommendation performance and meanwhile exhibits a high level of fairness.
OpenAGI: When LLM Meets Domain Experts
Apr 12, 2023



Human intelligence has the remarkable ability to assemble basic skills into complex ones so as to solve complex tasks. This ability is equally important for Artificial Intelligence (AI), and thus, we assert that in addition to the development of large, comprehensive intelligent models, it is equally crucial to equip such models with the capability to harness various domain-specific expert models for complex task-solving in the pursuit of Artificial General Intelligence (AGI). Recent developments in Large Language Models (LLMs) have demonstrated remarkable learning and reasoning abilities, making them promising as a controller to select, synthesize, and execute external models to solve complex tasks. In this project, we develop OpenAGI, an open-source AGI research platform, specifically designed to offer complex, multi-step tasks and accompanied by task-specific datasets, evaluation metrics, and a diverse range of extensible models. OpenAGI formulates complex tasks as natural language queries, serving as input to the LLM. The LLM subsequently selects, synthesizes, and executes models provided by OpenAGI to address the task. Furthermore, we propose a Reinforcement Learning from Task Feedback (RLTF) mechanism, which uses the task-solving result as feedback to improve the LLM's task-solving ability. Thus, the LLM is responsible for synthesizing various external models for solving complex tasks, while RLTF provides feedback to improve its task-solving ability, enabling a feedback loop for self-improving AI. We believe that the paradigm of LLMs operating various expert models for complex task-solving is a promising approach towards AGI. To facilitate the community's long-term improvement and evaluation of AGI's ability, we open-source the code, benchmark, and evaluation methods of the OpenAGI project at https://github.com/agiresearch/OpenAGI.
Causal Inference for Recommendation: Foundations, Methods and Applications
Jan 08, 2023



Recommender systems are important and powerful tools for various personalized services. Traditionally, these systems use data mining and machine learning techniques to make recommendations based on correlations found in the data. However, relying solely on correlation without considering the underlying causal mechanism may lead to various practical issues such as fairness, explainability, robustness, bias, echo chamber and controllability problems. Therefore, researchers in related area have begun incorporating causality into recommendation systems to address these issues. In this survey, we review the existing literature on causal inference in recommender systems. We discuss the fundamental concepts of both recommender systems and causal inference as well as their relationship, and review the existing work on causal methods for different problems in recommender systems. Finally, we discuss open problems and future directions in the field of causal inference for recommendations.