 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating how LLM annotations represent diverse views on contentious topics
Mar 29, 2025Researchers have proposed the use of generative large language models (LLMs) to label data for both research and applied settings. This literature emphasizes the improved performance of LLMs relative to other natural language models, noting that LLMs typically outperform other models on standard metrics such as accuracy, precision, recall, and F1 score. However, previous literature has also highlighted the bias embedded in language models, particularly around contentious topics such as potentially toxic content. This bias could result in labels applied by LLMs that disproportionately align with majority groups over a more diverse set of viewpoints. In this paper, we evaluate how LLMs represent diverse viewpoints on these contentious tasks. Across four annotation tasks on four datasets, we show that LLMs do not show substantial disagreement with annotators on the basis of demographics. Instead, the model, prompt, and disagreement between human annotators on the labeling task are far more predictive of LLM agreement. Our findings suggest that when using LLMs to annotate data, under-representing the views of particular groups is not a substantial concern. We conclude with a discussion of the implications for researchers and practitioners.
Characterizing Online Toxicity During the 2022 Mpox Outbreak: A Computational Analysis of Topical and Network Dynamics
Aug 21, 2024



Background: Online toxicity, encompassing behaviors such as harassment, bullying, hate speech, and the dissemination of misinformation, has become a pressing social concern in the digital age. The 2022 Mpox outbreak, initially termed "Monkeypox" but subsequently renamed to mitigate associated stigmas and societal concerns, serves as a poignant backdrop to this issue. Objective: In this research, we undertake a comprehensive analysis of the toxic online discourse surrounding the 2022 Mpox outbreak. Our objective is to dissect its origins, characterize its nature and content, trace its dissemination patterns, and assess its broader societal implications, with the goal of providing insights that can inform strategies to mitigate such toxicity in future crises. Methods: We collected more than 1.6 million unique tweets and analyzed them from five dimensions, including context, extent, content, speaker, and intent. Utilizing BERT-based topic modeling and social network community clustering, we delineated the toxic dynamics on Twitter. Results: We identified five high-level topic categories in the toxic online discourse on Twitter, including disease (46.6%), health policy and healthcare (19.3%), homophobia (23.9%), politics (6.0%), and racism (4.1%). Through the toxicity diffusion networks of mentions, retweets, and the top users, we found that retweets of toxic content were widespread, while influential users rarely engaged with or countered this toxicity through retweets. Conclusions: By tracking topical dynamics, we can track the changing popularity of toxic content online, providing a better understanding of societal challenges. Network dynamics spotlight key social media influencers and their intents, indicating that addressing these central figures in toxic discourse can enhance crisis communication and inform policy-making.
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Jun 17, 2024



Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
War and Peace : Large Language Model-based Multi-Agent Simulation of World Wars
Nov 28, 2023Can we avoid wars at the crossroads of history? This question has been pursued by individuals, scholars, policymakers, and organizations throughout human history. In this research, we attempt to answer the question based on the recent advances of Artificial Intelligence (AI) and Large Language Models (LLMs). We propose \textbf{WarAgent}, an LLM-powered multi-agent AI system, to simulate the participating countries, their decisions, and the consequences, in historical international conflicts, including the World War I (WWI), the World War II (WWII), and the Warring States Period (WSP) in Ancient China. By evaluating the simulation effectiveness, we examine the advancements and limitations of cutting-edge AI systems' abilities in studying complex collective human behaviors such as international conflicts under diverse settings. In these simulations, the emergent interactions among agents also offer a novel perspective for examining the triggers and conditions that lead to war. Our findings offer data-driven and AI-augmented insights that can redefine how we approach conflict resolution and peacekeeping strategies. The implications stretch beyond historical analysis, offering a blueprint for using AI to understand human history and possibly prevent future international conflicts. Code and data are available at \url{https://github.com/agiresearch/WarAgent}.
How We Define Harm Impacts Data Annotations: Explaining How Annotators Distinguish Hateful, Offensive, and Toxic Comments
Sep 12, 2023Computational social science research has made advances in machine learning and natural language processing that support content moderators in detecting harmful content. These advances often rely on training datasets annotated by crowdworkers for harmful content. In designing instructions for annotation tasks to generate training data for these algorithms, researchers often treat the harm concepts that we train algorithms to detect - 'hateful', 'offensive', 'toxic', 'racist', 'sexist', etc. - as interchangeable. In this work, we studied whether the way that researchers define 'harm' affects annotation outcomes. Using Venn diagrams, information gain comparisons, and content analyses, we reveal that annotators do not use the concepts 'hateful', 'offensive', and 'toxic' interchangeably. We identify that features of harm definitions and annotators' individual characteristics explain much of how annotators use these terms differently. Our results offer empirical evidence discouraging the common practice of using harm concepts interchangeably in content moderation research. Instead, researchers should make specific choices about which harm concepts to analyze based on their research goals. Recognizing that researchers are often resource constrained, we also encourage researchers to provide information to bound their findings when their concepts of interest differ from concepts that off-the-shelf harmful content detection algorithms identify. Finally, we encourage algorithm providers to ensure their instruments can adapt to contextually-specific content detection goals (e.g., soliciting instrument users' feedback).
Investigating disaster response through social media data and the Susceptible-Infected-Recovered (SIR) model: A case study of 2020 Western U.S. wildfire season
Aug 10, 2023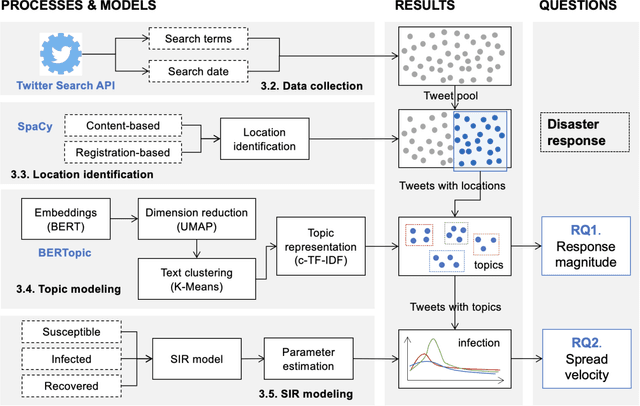

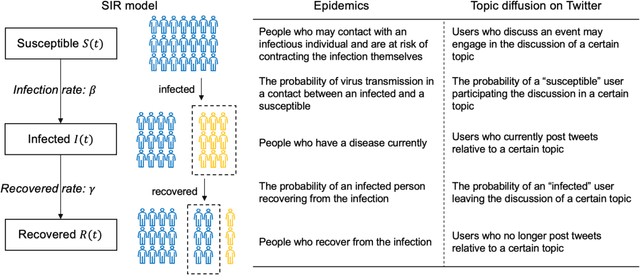
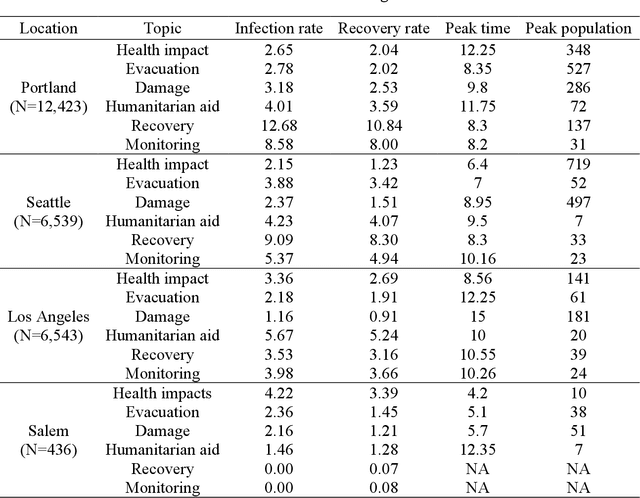
Effective disaster response is critical for affected communities. Responders and decision-makers would benefit from reliable, timely measures of the issues impacting their communities during a disaster, and social media offers a potentially rich data source. Social media can reflect public concerns and demands during a disaster, offering valuable insights for decision-makers to understand evolving situations and optimize resource allocation. We used Bidirectional Encoder Representations from Transformers (BERT) topic modeling to cluster topics from Twitter data. Then, we conducted a temporal-spatial analysis to examine the distribution of these topics across different regions during the 2020 western U.S. wildfire season. Our results show that Twitter users mainly focused on three topics:"health impact," "damage," and "evacuation." We used the Susceptible-Infected-Recovered (SIR) theory to explore the magnitude and velocity of topic diffusion on Twitter. The results displayed a clear relationship between topic trends and wildfire propagation patterns. The estimated parameters obtained from the SIR model in selected cities revealed that residents exhibited a high level of several concerns during the wildfire. Our study details how the SIR model and topic modeling using social media data can provide decision-makers with a quantitative approach to measure disaster response and support their decision-making processes.
DataChat: Prototyping a Conversational Agent for Dataset Search and Visualization
May 26, 2023Data users need relevant context and research expertise to effectively search for and identify relevant datasets. Leading data providers, such as the Inter-university Consortium for Political and Social Research (ICPSR), offer standardized metadata and search tools to support data search. Metadata standards emphasize the machine-readability of data and its documentation. There are opportunities to enhance dataset search by improving users' ability to learn about, and make sense of, information about data. Prior research has shown that context and expertise are two main barriers users face in effectively searching for, evaluating, and deciding whether to reuse data. In this paper, we propose a novel chatbot-based search system, DataChat, that leverages a graph database and a large language model to provide novel ways for users to interact with and search for research data. DataChat complements data archives' and institutional repositories' ongoing efforts to curate, preserve, and share research data for reuse by making it easier for users to explore and learn about available research data.
"HOT" ChatGPT: The promise of ChatGPT in detecting and discriminating hateful, offensive, and toxic comments on social media
Apr 20, 2023Harmful content is pervasive on social media, poisoning online communities and negatively impacting participation. A common approach to address this issue is to develop detection models that rely on human annotations. However, the tasks required to build such models expose annotators to harmful and offensive content and may require significant time and cost to complete. Generative AI models have the potential to understand and detect harmful content. To investigate this potential, we used ChatGPT and compared its performance with MTurker annotations for three frequently discussed concepts related to harmful content: Hateful, Offensive, and Toxic (HOT). We designed five prompts to interact with ChatGPT and conducted four experiments eliciting HOT classifications. Our results show that ChatGPT can achieve an accuracy of approximately 80% when compared to MTurker annotations. Specifically, the model displays a more consistent classification for non-HOT comments than HOT comments compared to human annotations. Our findings also suggest that ChatGPT classifications align with provided HOT definitions, but ChatGPT classifies "hateful" and "offensive" as subsets of "toxic." Moreover, the choice of prompts used to interact with ChatGPT impacts its performance. Based on these in-sights, our study provides several meaningful implications for employing ChatGPT to detect HOT content, particularly regarding the reliability and consistency of its performance, its understand-ing and reasoning of the HOT concept, and the impact of prompts on its performance. Overall, our study provides guidance about the potential of using generative AI models to moderate large volumes of user-generated content on social media.
A Bibliometric Review of Large Language Models Research from 2017 to 2023
Apr 03, 2023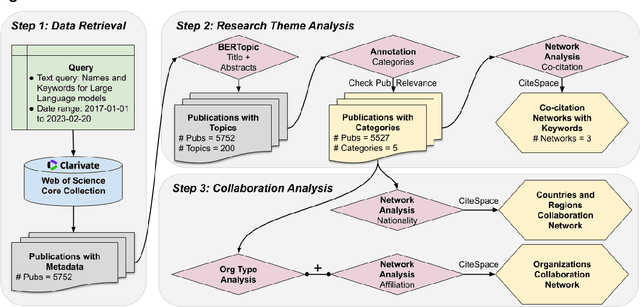

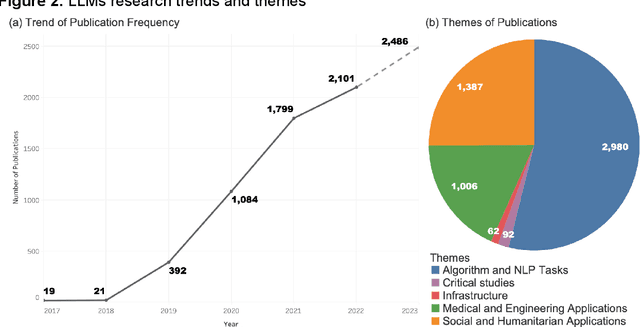
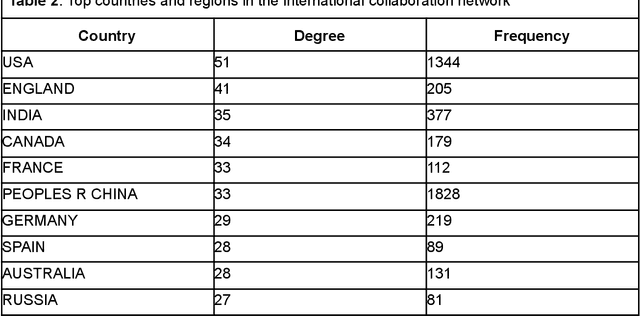
Large language models (LLMs) are a class of language models that have demonstrated outstanding performance across a range of natural language processing (NLP) tasks and have become a highly sought-after research area, because of their ability to generate human-like language and their potential to revolutionize science and technology. In this study, we conduct bibliometric and discourse analyses of scholarly literature on LLMs. Synthesizing over 5,000 publications, this paper serves as a roadmap for researchers, practitioners, and policymakers to navigate the current landscape of LLMs research. We present the research trends from 2017 to early 2023, identifying patterns in research paradigms and collaborations. We start with analyzing the core algorithm developments and NLP tasks that are fundamental in LLMs research. We then investigate the applications of LLMs in various fields and domains including medicine, engineering, social science, and humanities. Our review also reveals the dynamic, fast-paced evolution of LLMs research. Overall, this paper offers valuable insights into the current state, impact, and potential of LLMs research and its applications.
A Natural Language Processing Pipeline for Detecting Informal Data References in Academic Literature
May 23, 2022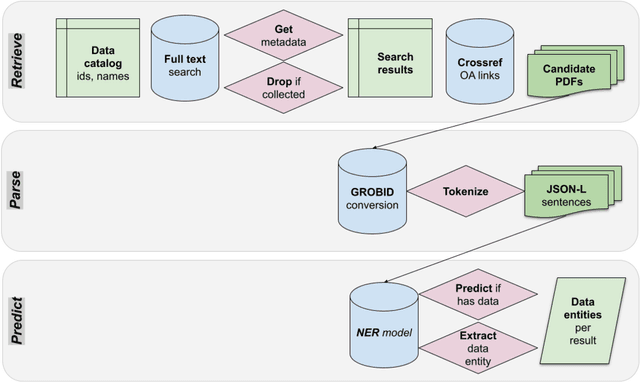

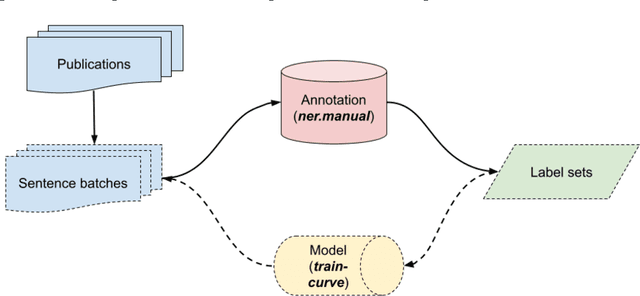

Discovering authoritative links between publications and the datasets that they use can be a labor-intensive process. We introduce a natural language processing pipeline that retrieves and reviews publications for informal references to research datasets, which complements the work of data librarians. We first describe the components of the pipeline and then apply it to expand an authoritative bibliography linking thousands of social science studies to the data-related publications in which they are used. The pipeline increases recall for literature to review for inclusion in data-related collections of publications and makes it possible to detect informal data references at scale. We contribute (1) a novel Named Entity Recognition (NER) model that reliably detects informal data references and (2) a dataset connecting items from social science literature with datasets they reference. Together, these contributions enable future work on data reference, data citation networks, and data reuse.