 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"HOT" ChatGPT: The promise of ChatGPT in detecting and discriminating hateful, offensive, and toxic comments on social media
Paper and Code
Apr 20, 2023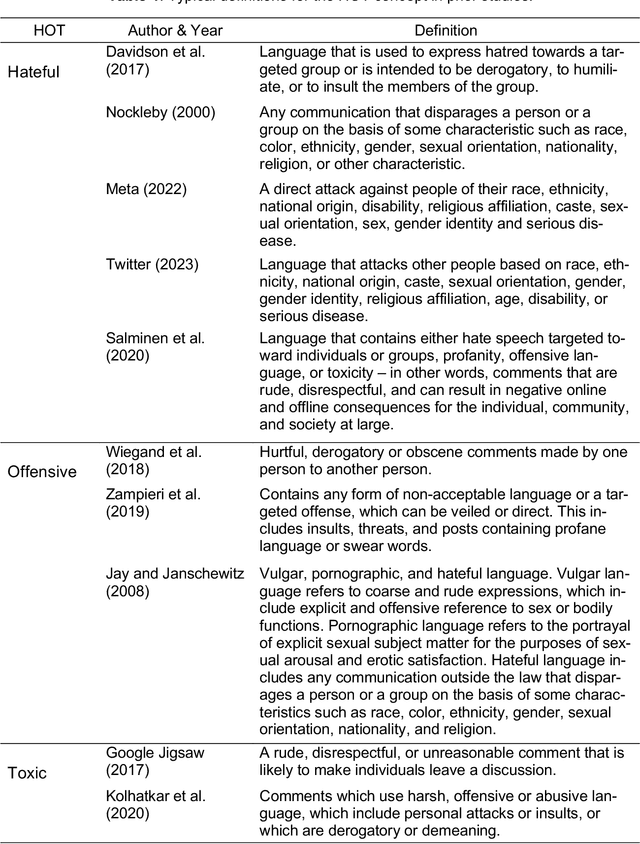
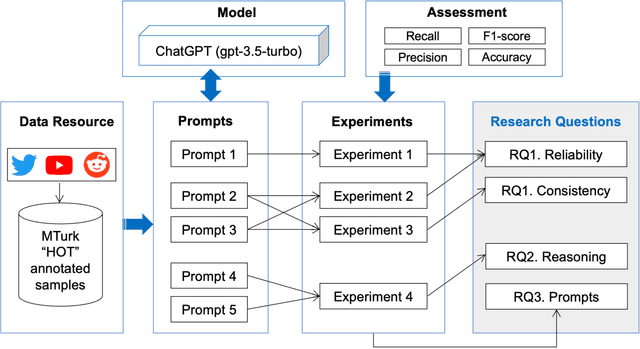


Harmful content is pervasive on social media, poisoning online communities and negatively impacting participation. A common approach to address this issue is to develop detection models that rely on human annotations. However, the tasks required to build such models expose annotators to harmful and offensive content and may require significant time and cost to complete. Generative AI models have the potential to understand and detect harmful content. To investigate this potential, we used ChatGPT and compared its performance with MTurker annotations for three frequently discussed concepts related to harmful content: Hateful, Offensive, and Toxic (HOT). We designed five prompts to interact with ChatGPT and conducted four experiments eliciting HOT classifications. Our results show that ChatGPT can achieve an accuracy of approximately 80% when compared to MTurker annotations. Specifically, the model displays a more consistent classification for non-HOT comments than HOT comments compared to human annotations. Our findings also suggest that ChatGPT classifications align with provided HOT definitions, but ChatGPT classifies "hateful" and "offensive" as subsets of "toxic." Moreover, the choice of prompts used to interact with ChatGPT impacts its performance. Based on these in-sights, our study provides several meaningful implications for employing ChatGPT to detect HOT content, particularly regarding the reliability and consistency of its performance, its understand-ing and reasoning of the HOT concept, and the impact of prompts on its performance. Overall, our study provides guidance about the potential of using generative AI models to moderate large volumes of user-generated content on social media.