 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating how LLM annotations represent diverse views on contentious topics
Mar 29, 2025



Researchers have proposed the use of generative large language models (LLMs) to label data for both research and applied settings. This literature emphasizes the improved performance of LLMs relative to other natural language models, noting that LLMs typically outperform other models on standard metrics such as accuracy, precision, recall, and F1 score. However, previous literature has also highlighted the bias embedded in language models, particularly around contentious topics such as potentially toxic content. This bias could result in labels applied by LLMs that disproportionately align with majority groups over a more diverse set of viewpoints. In this paper, we evaluate how LLMs represent diverse viewpoints on these contentious tasks. Across four annotation tasks on four datasets, we show that LLMs do not show substantial disagreement with annotators on the basis of demographics. Instead, the model, prompt, and disagreement between human annotators on the labeling task are far more predictive of LLM agreement. Our findings suggest that when using LLMs to annotate data, under-representing the views of particular groups is not a substantial concern. We conclude with a discussion of the implications for researchers and practitioners.
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Jun 17, 2024



Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
"HOT" ChatGPT: The promise of ChatGPT in detecting and discriminating hateful, offensive, and toxic comments on social media
Apr 20, 2023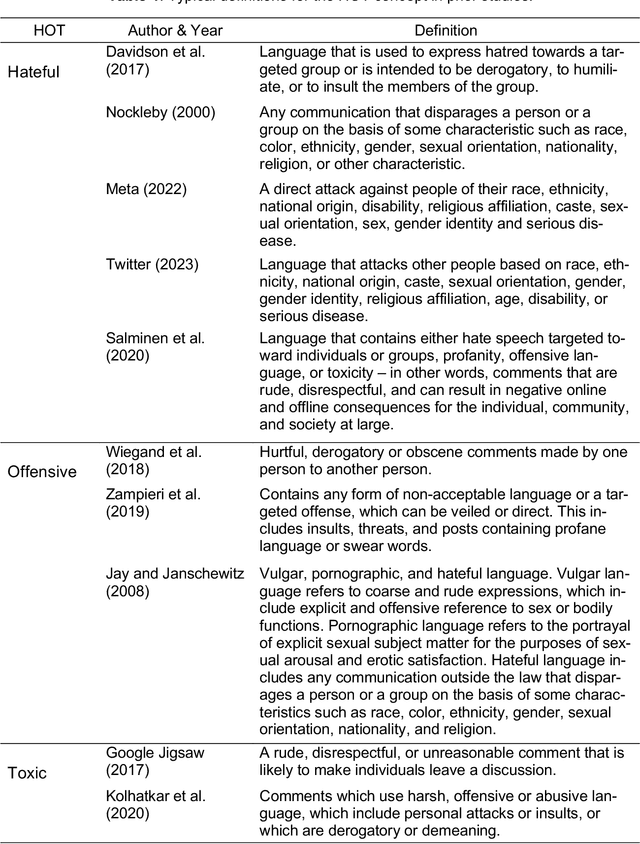
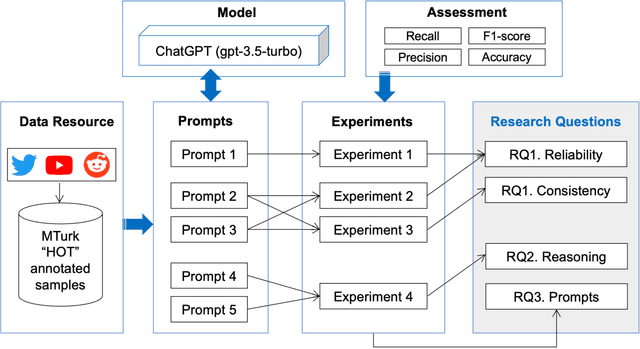


Harmful content is pervasive on social media, poisoning online communities and negatively impacting participation. A common approach to address this issue is to develop detection models that rely on human annotations. However, the tasks required to build such models expose annotators to harmful and offensive content and may require significant time and cost to complete. Generative AI models have the potential to understand and detect harmful content. To investigate this potential, we used ChatGPT and compared its performance with MTurker annotations for three frequently discussed concepts related to harmful content: Hateful, Offensive, and Toxic (HOT). We designed five prompts to interact with ChatGPT and conducted four experiments eliciting HOT classifications. Our results show that ChatGPT can achieve an accuracy of approximately 80% when compared to MTurker annotations. Specifically, the model displays a more consistent classification for non-HOT comments than HOT comments compared to human annotations. Our findings also suggest that ChatGPT classifications align with provided HOT definitions, but ChatGPT classifies "hateful" and "offensive" as subsets of "toxic." Moreover, the choice of prompts used to interact with ChatGPT impacts its performance. Based on these in-sights, our study provides several meaningful implications for employing ChatGPT to detect HOT content, particularly regarding the reliability and consistency of its performance, its understand-ing and reasoning of the HOT concept, and the impact of prompts on its performance. Overall, our study provides guidance about the potential of using generative AI models to moderate large volumes of user-generated content on social media.
Extracting Procedural Knowledge from Technical Documents
Oct 20, 2020
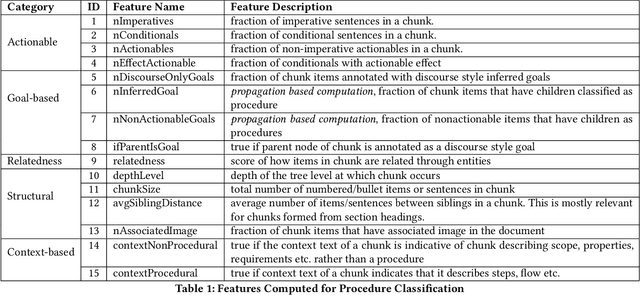
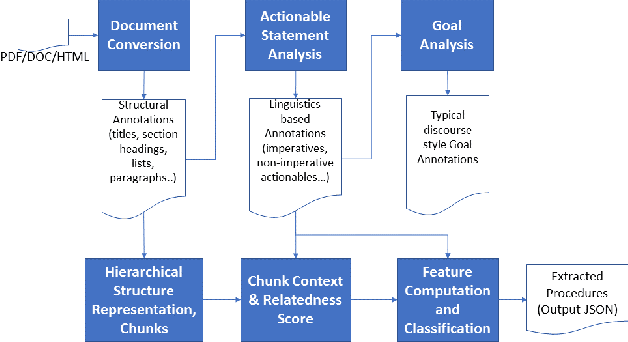

Procedures are an important knowledge component of documents that can be leveraged by cognitive assistants for automation, question-answering or driving a conversation. It is a challenging problem to parse big dense documents like product manuals, user guides to automatically understand which parts are talking about procedures and subsequently extract them. Most of the existing research has focused on extracting flows in given procedures or understanding the procedures in order to answer conceptual questions. Identifying and extracting multiple procedures automatically from documents of diverse formats remains a relatively less addressed problem. In this work, we cover some of this ground by -- 1) Providing insights on how structural and linguistic properties of documents can be grouped to define types of procedures, 2) Analyzing documents to extract the relevant linguistic and structural properties, and 3) Formulating procedure identification as a classification problem that leverages the features of the document derived from the above analysis. We first implemented and deployed unsupervised techniques which were used in different use cases. Based on the evaluation in different use cases, we figured out the weaknesses of the unsupervised approach. We then designed an improved version which was supervised. We demonstrate that our technique is effective in identifying procedures from big and complex documents alike by achieving accuracy of 89%.
Adversarial Adaptation of Scene Graph Models for Understanding Civic Issues
Jan 29, 2019
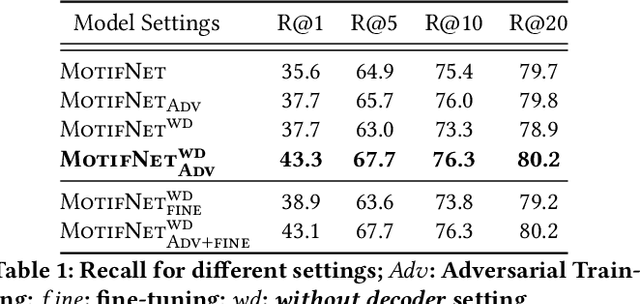
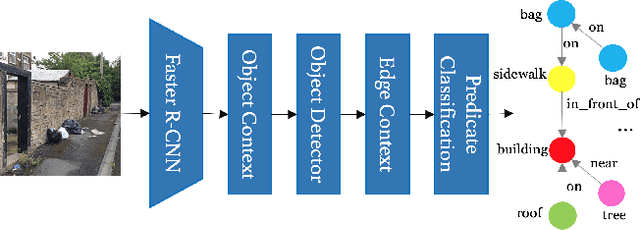
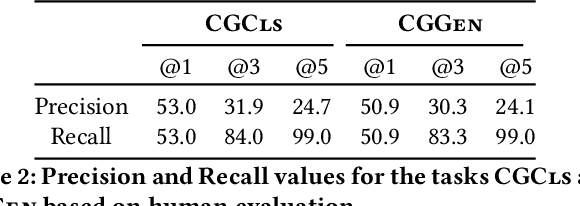
Citizen engagement and technology usage are two emerging trends driven by smart city initiatives. Governments around the world are adopting technology for faster resolution of civic issues. Typically, citizens report issues, such as broken roads, garbage dumps, etc. through web portals and mobile apps, in order for the government authorities to take appropriate actions. Several mediums -- text, image, audio, video -- are used to report these issues. Through a user study with 13 citizens and 3 authorities, we found that image is the most preferred medium to report civic issues. However, analyzing civic issue related images is challenging for the authorities as it requires manual effort. Moreover, previous works have been limited to identifying a specific set of issues from images. In this work, given an image, we propose to generate a Civic Issue Graph consisting of a set of objects and the semantic relations between them, which are representative of the underlying civic issue. We also release two multi-modal (text and images) datasets, that can help in further analysis of civic issues from images. We present a novel approach for adversarial training of existing scene graph models that enables the use of scene graphs for new applications in the absence of any labelled training data. We conduct several experiments to analyze the efficacy of our approach, and using human evaluation, we establish the appropriateness of our model at representing different civic issues.