 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Procedural Knowledge from Technical Documents
Paper and Code
Oct 20, 2020
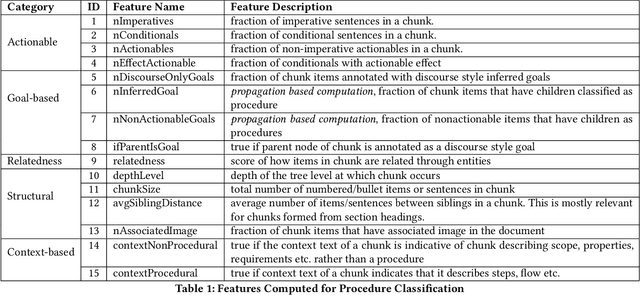
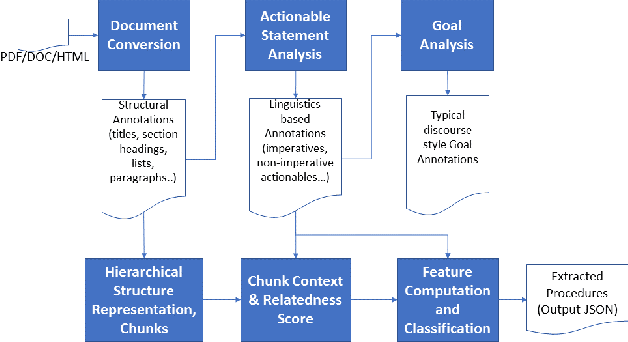

Procedures are an important knowledge component of documents that can be leveraged by cognitive assistants for automation, question-answering or driving a conversation. It is a challenging problem to parse big dense documents like product manuals, user guides to automatically understand which parts are talking about procedures and subsequently extract them. Most of the existing research has focused on extracting flows in given procedures or understanding the procedures in order to answer conceptual questions. Identifying and extracting multiple procedures automatically from documents of diverse formats remains a relatively less addressed problem. In this work, we cover some of this ground by -- 1) Providing insights on how structural and linguistic properties of documents can be grouped to define types of procedures, 2) Analyzing documents to extract the relevant linguistic and structural properties, and 3) Formulating procedure identification as a classification problem that leverages the features of the document derived from the above analysis. We first implemented and deployed unsupervised techniques which were used in different use cases. Based on the evaluation in different use cases, we figured out the weaknesses of the unsupervised approach. We then designed an improved version which was supervised. We demonstrate that our technique is effective in identifying procedures from big and complex documents alike by achieving accuracy of 89%.