 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Procedural Knowledge from Technical Documents
Oct 20, 2020
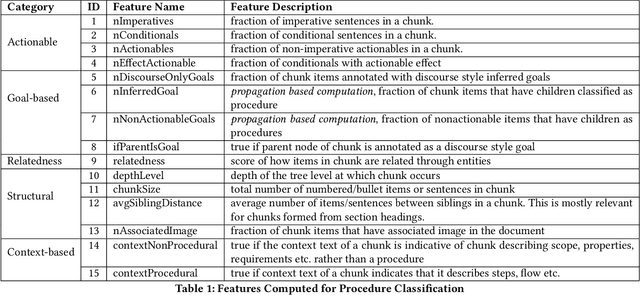
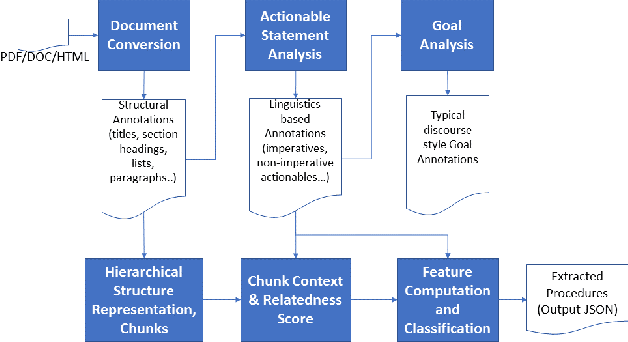

Procedures are an important knowledge component of documents that can be leveraged by cognitive assistants for automation, question-answering or driving a conversation. It is a challenging problem to parse big dense documents like product manuals, user guides to automatically understand which parts are talking about procedures and subsequently extract them. Most of the existing research has focused on extracting flows in given procedures or understanding the procedures in order to answer conceptual questions. Identifying and extracting multiple procedures automatically from documents of diverse formats remains a relatively less addressed problem. In this work, we cover some of this ground by -- 1) Providing insights on how structural and linguistic properties of documents can be grouped to define types of procedures, 2) Analyzing documents to extract the relevant linguistic and structural properties, and 3) Formulating procedure identification as a classification problem that leverages the features of the document derived from the above analysis. We first implemented and deployed unsupervised techniques which were used in different use cases. Based on the evaluation in different use cases, we figured out the weaknesses of the unsupervised approach. We then designed an improved version which was supervised. We demonstrate that our technique is effective in identifying procedures from big and complex documents alike by achieving accuracy of 89%.
Automatic Business Process Structure Discovery using Ordered Neurons LSTM: A Preliminary Study
Jan 05, 2020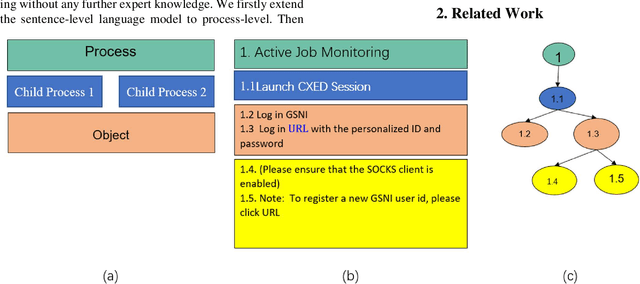
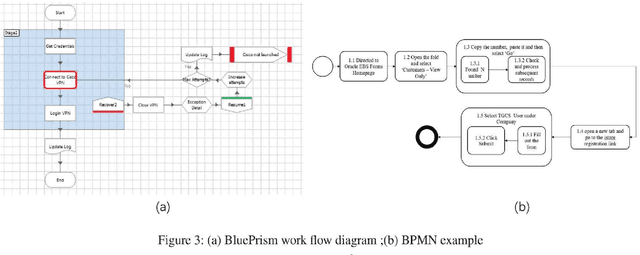
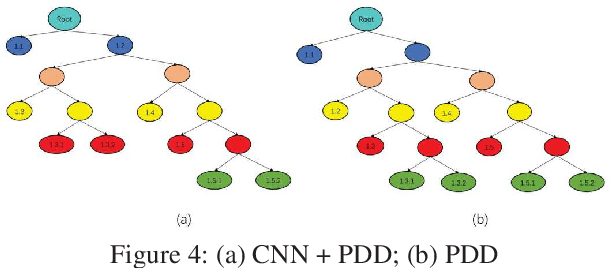
Automatic process discovery from textual process documentations is highly desirable to reduce time and cost of Business Process Management (BPM) implementation in organizations. However, existing automatic process discovery approaches mainly focus on identifying activities out of the documentations. Deriving the structural relationships between activities, which is important in the whole process discovery scope, is still a challenge. In fact, a business process has latent semantic hierarchical structure which defines different levels of detail to reflect the complex business logic. Recent findings in neural machine learning area show that the meaningful linguistic structure can be induced by joint language modeling and structure learning. Inspired by these findings, we propose to retrieve the latent hierarchical structure present in the textual business process documents by building a neural network that leverages a novel recurrent architecture, Ordered Neurons LSTM (ON-LSTM), with process-level language model objective. We tested the proposed approach on data set of Process Description Documents (PDD) from our practical Robotic Process Automation (RPA) projects. Preliminary experiments showed promising results.
Improving IT Support by Enhancing Incident Management Process with Multi-modal Analysis
Aug 04, 2019
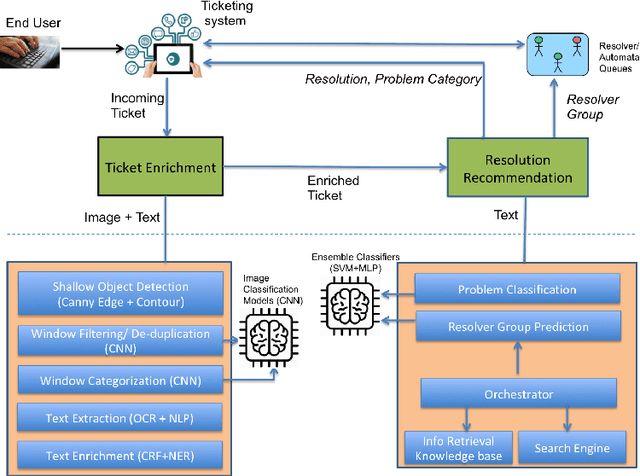
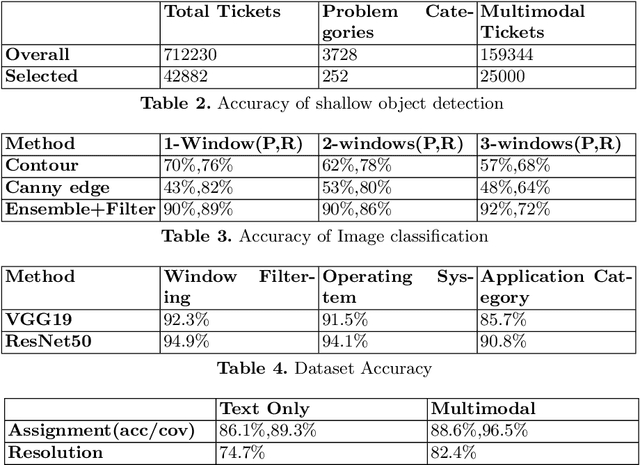
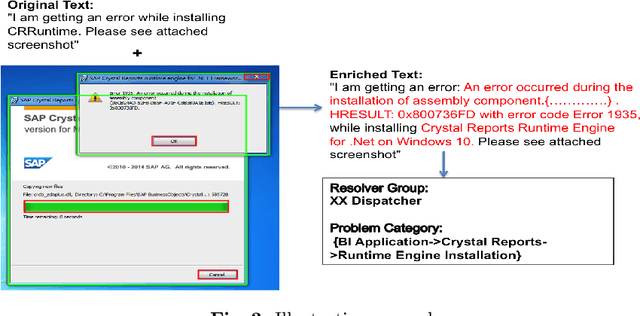
IT support services industry is going through a major transformation with AI becoming commonplace. There has been a lot of effort in the direction of automation at every human touchpoint in the IT support processes. Incident management is one such process which has been a beacon process for AI based automation. The vision is to automate the process from the time an incident/ticket arrives till it is resolved and closed. While text is the primary mode of communicating the incidents, there has been a growing trend of using alternate modalities like image to communicate the problem. A large fraction of IT support tickets today contain attached image data in the form of screenshots, log messages, invoices and so on. These attachments help in better explanation of the problem which aids in faster resolution. Anybody who aspires to provide AI based IT support, it is essential to build systems which can handle multi-modal content. In this paper we present how incident management in IT support domain can be made much more effective using multi-modal analysis. The information extracted from different modalities are correlated to enrich the information in the ticket and used for better ticket routing and resolution. We evaluate our system using about 25000 real tickets containing attachments from selected problem areas. Our results demonstrate significant improvements in both routing and resolution with the use of multi-modal ticket analysis compared to only text based analysis.
Cognitive system to achieve human-level accuracy in automated assignment of helpdesk email tickets
Aug 09, 2018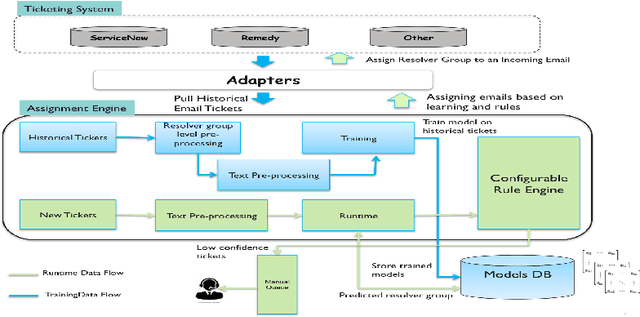
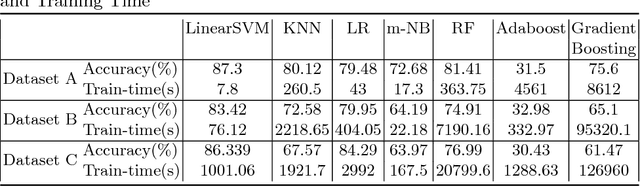
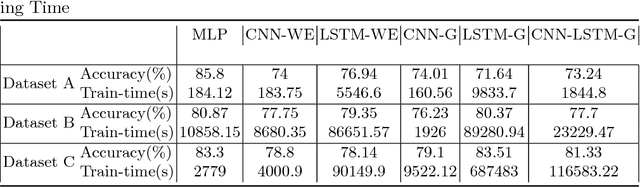
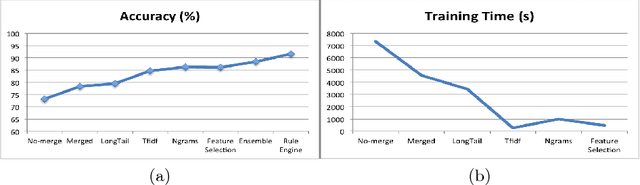
Ticket assignment/dispatch is a crucial part of service delivery business with lot of scope for automation and optimization. In this paper, we present an end-to-end automated helpdesk email ticket assignment system, which is also offered as a service. The objective of the system is to determine the nature of the problem mentioned in an incoming email ticket and then automatically dispatch it to an appropriate resolver group (or team) for resolution. The proposed system uses an ensemble classifier augmented with a configurable rule engine. While design of classifier that is accurate is one of the main challenges, we also need to address the need of designing a system that is robust and adaptive to changing business needs. We discuss some of the main design challenges associated with email ticket assignment automation and how we solve them. The design decisions for our system are driven by high accuracy, coverage, business continuity, scalability and optimal usage of computational resources. Our system has been deployed in production of three major service providers and currently assigning over 40,000 emails per month, on an average, with an accuracy close to 90% and covering at least 90% of email tickets. This translates to achieving human-level accuracy and results in a net saving of about 23000 man-hours of effort per annum.