 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGSPNet: A framework for parcel-scale crop fine-grained semantic change detection from UAV high-resolution imagery with agricultural geographic scene constraints
Jan 11, 2024Real-time and accurate information on fine-grained changes in crop cultivation is of great significance for crop growth monitoring, yield prediction and agricultural structure adjustment. Aiming at the problems of serious spectral confusion in visible high-resolution unmanned aerial vehicle (UAV) images of different phases, interference of large complex background and salt-and-pepper noise by existing semantic change detection (SCD) algorithms, in order to effectively extract deep image features of crops and meet the demand of agricultural practical engineering applications, this paper designs and proposes an agricultural geographic scene and parcel-scale constrained SCD framework for crops (AGSPNet). AGSPNet framework contains three parts: agricultural geographic scene (AGS) division module, parcel edge extraction module and crop SCD module. Meanwhile, we produce and introduce an UAV image SCD dataset (CSCD) dedicated to agricultural monitoring, encompassing multiple semantic variation types of crops in complex geographical scene. We conduct comparative experiments and accuracy evaluations in two test areas of this dataset, and the results show that the crop SCD results of AGSPNet consistently outperform other deep learning SCD models in terms of quantity and quality, with the evaluation metrics F1-score, kappa, OA, and mIoU obtaining improvements of 0.038, 0.021, 0.011 and 0.062, respectively, on average over the sub-optimal method. The method proposed in this paper can clearly detect the fine-grained change information of crop types in complex scenes, which can provide scientific and technical support for smart agriculture monitoring and management, food policy formulation and food security assurance.
Dynamic Knowledge Distillation for Black-box Hypothesis Transfer Learning
Aug 07, 2020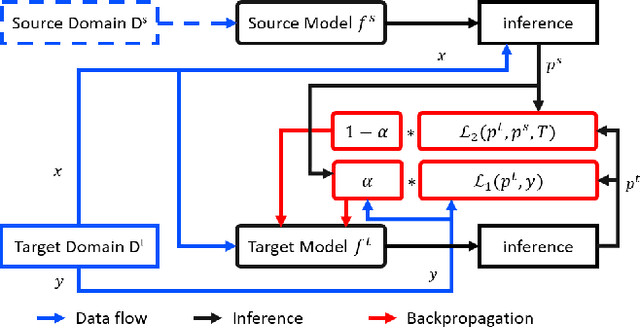
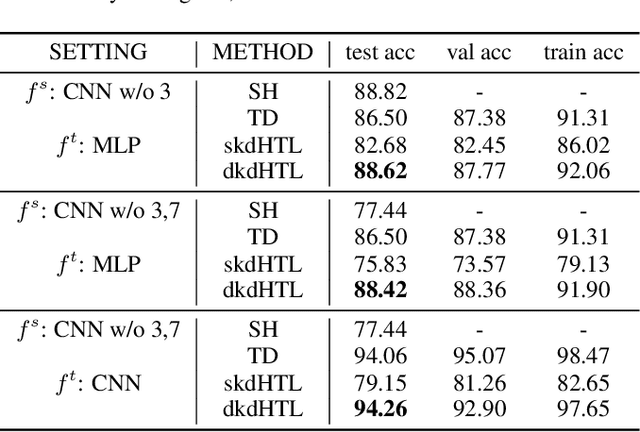
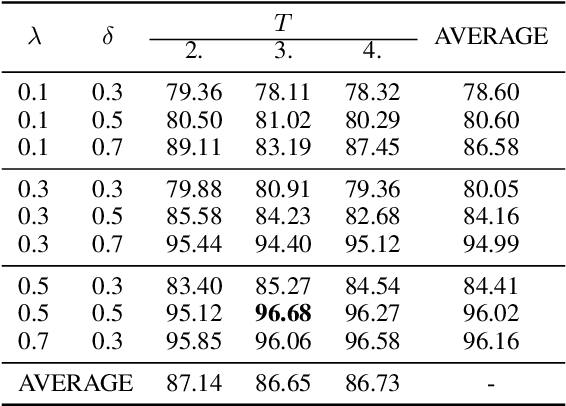
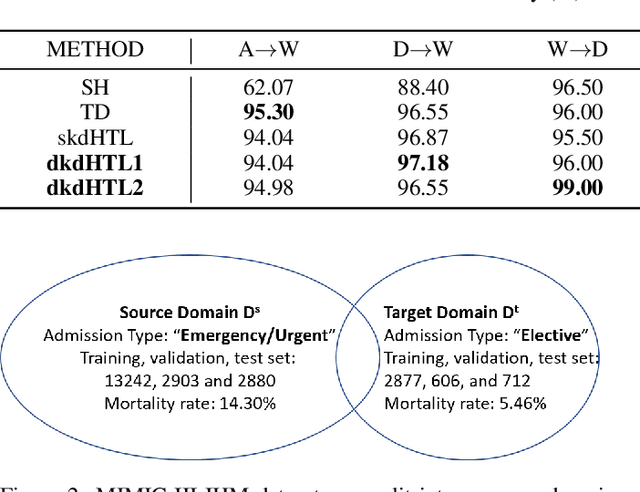
In real world applications like healthcare, it is usually difficult to build a machine learning prediction model that works universally well across different institutions. At the same time, the available model is often proprietary, i.e., neither the model parameter nor the data set used for model training is accessible. In consequence, leveraging the knowledge hidden in the available model (aka. the hypothesis) and adapting it to a local data set becomes extremely challenging. Motivated by this situation, in this paper we aim to address such a specific case within the hypothesis transfer learning framework, in which 1) the source hypothesis is a black-box model and 2) the source domain data is unavailable. In particular, we introduce a novel algorithm called dynamic knowledge distillation for hypothesis transfer learning (dkdHTL). In this method, we use knowledge distillation with instance-wise weighting mechanism to adaptively transfer the "dark" knowledge from the source hypothesis to the target domain.The weighting coefficients of the distillation loss and the standard loss are determined by the consistency between the predicted probability of the source hypothesis and the target ground-truth label.Empirical results on both transfer learning benchmark datasets and a healthcare dataset demonstrate the effectiveness of our method.
Unlocking the Power of Deep PICO Extraction: Step-wise Medical NER Identification
Apr 30, 2020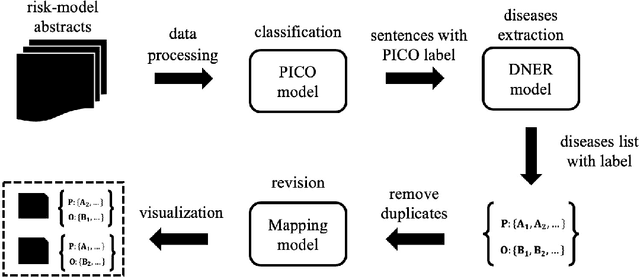



The PICO framework (Population, Intervention, Comparison, and Outcome) is usually used to formulate evidence in the medical domain. The major task of PICO extraction is to extract sentences from medical literature and classify them into each class. However, in most circumstances, there will be more than one evidences in an extracted sentence even it has been categorized to a certain class. In order to address this problem, we propose a step-wise disease Named Entity Recognition (DNER) extraction and PICO identification method. With our method, sentences in paper title and abstract are first classified into different classes of PICO, and medical entities are then identified and classified into P and O. Different kinds of deep learning frameworks are used and experimental results show that our method will achieve high performance and fine-grained extraction results comparing with conventional PICO extraction works.
Automatic Business Process Structure Discovery using Ordered Neurons LSTM: A Preliminary Study
Jan 05, 2020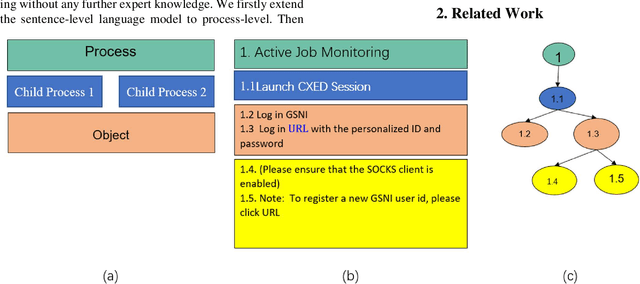
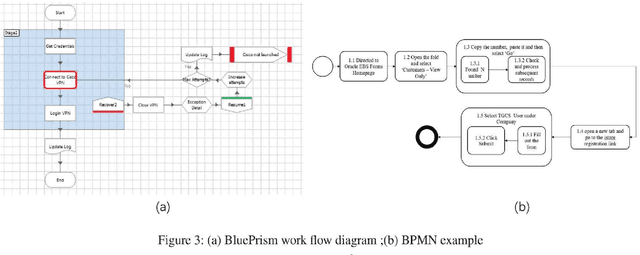
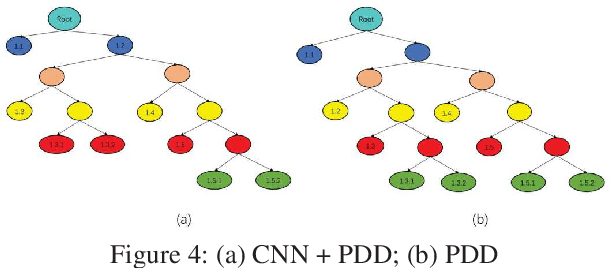
Automatic process discovery from textual process documentations is highly desirable to reduce time and cost of Business Process Management (BPM) implementation in organizations. However, existing automatic process discovery approaches mainly focus on identifying activities out of the documentations. Deriving the structural relationships between activities, which is important in the whole process discovery scope, is still a challenge. In fact, a business process has latent semantic hierarchical structure which defines different levels of detail to reflect the complex business logic. Recent findings in neural machine learning area show that the meaningful linguistic structure can be induced by joint language modeling and structure learning. Inspired by these findings, we propose to retrieve the latent hierarchical structure present in the textual business process documents by building a neural network that leverages a novel recurrent architecture, Ordered Neurons LSTM (ON-LSTM), with process-level language model objective. We tested the proposed approach on data set of Process Description Documents (PDD) from our practical Robotic Process Automation (RPA) projects. Preliminary experiments showed promising results.
Towards End-to-End Learning for Efficient Dialogue Agent by Modeling Looking-ahead Ability
Aug 15, 2019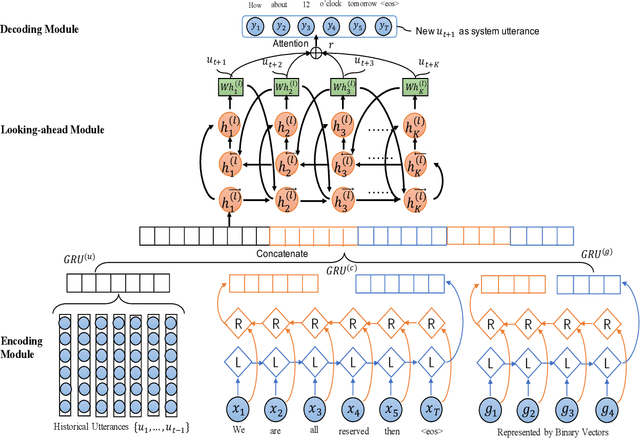
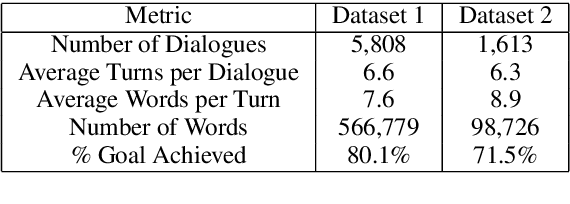
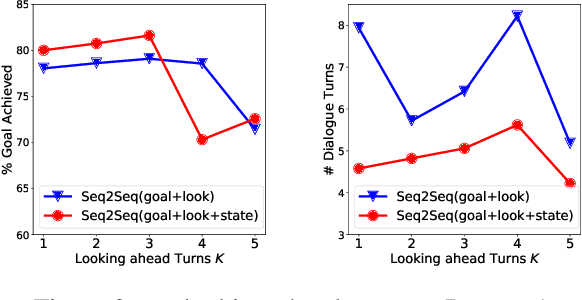
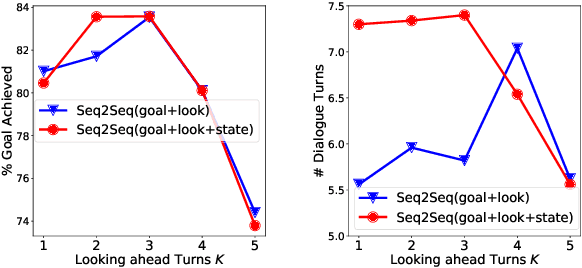
Learning an efficient manager of dialogue agent from data with little manual intervention is important, especially for goal-oriented dialogues. However, existing methods either take too many manual efforts (e.g. reinforcement learning methods) or cannot guarantee the dialogue efficiency (e.g. sequence-to-sequence methods). In this paper, we address this problem by proposing a novel end-to-end learning model to train a dialogue agent that can look ahead for several future turns and generate an optimal response to make the dialogue efficient. Our method is data-driven and does not require too much manual work for intervention during system design. We evaluate our method on two datasets of different scenarios and the experimental results demonstrate the efficiency of our model.
Outcome-Driven Clustering of Acute Coronary Syndrome Patients using Multi-Task Neural Network with Attention
Mar 27, 2019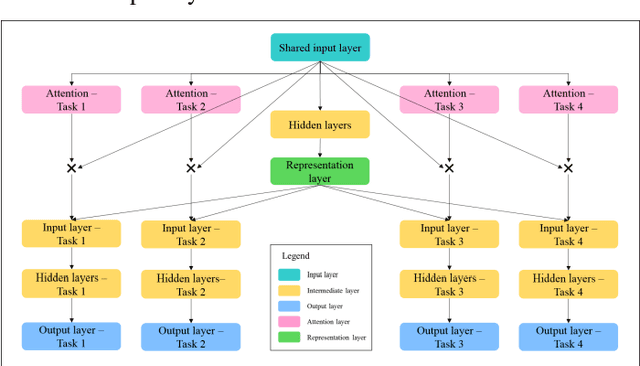
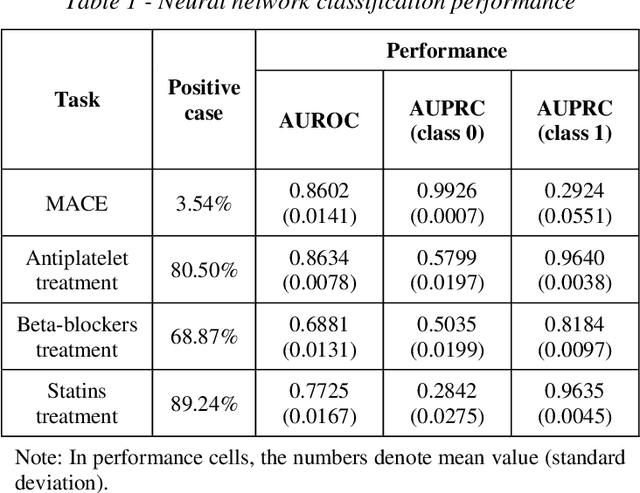
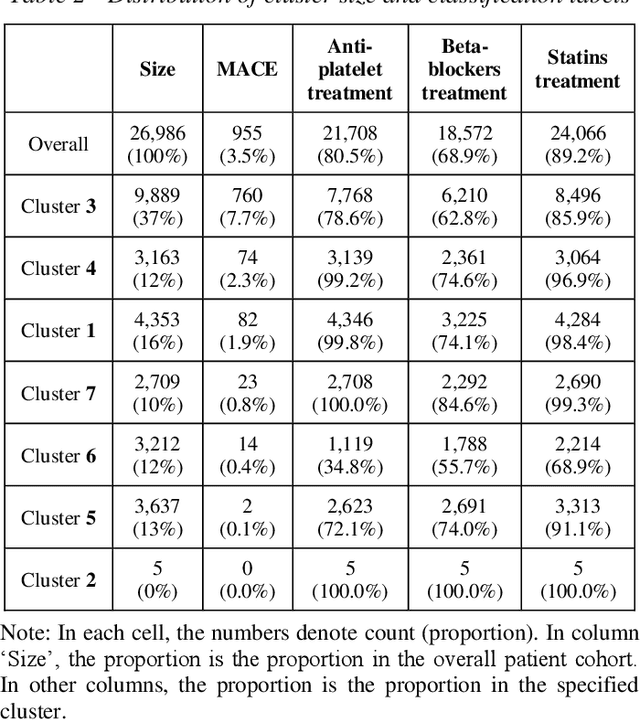
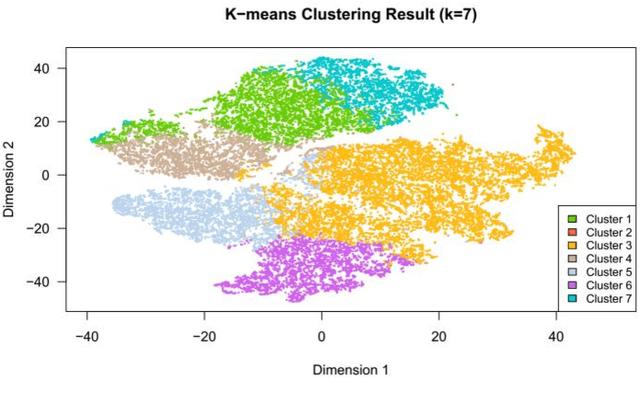
Cluster analysis aims at separating patients into phenotypically heterogenous groups and defining therapeutically homogeneous patient subclasses. It is an important approach in data-driven disease classification and subtyping. Acute coronary syndrome (ACS) is a syndrome due to sudden decrease of coronary artery blood flow, where disease classification would help to inform therapeutic strategies and provide prognostic insights. Here we conducted outcome-driven cluster analysis of ACS patients, which jointly considers treatment and patient outcome as indicators for patient state. Multi-task neural network with attention was used as a modeling framework, including learning of the patient state, cluster analysis, and feature importance profiling. Seven patient clusters were discovered. The clusters have different characteristics, as well as different risk profiles to the outcome of in-hospital major adverse cardiac events. The results demonstrate cluster analysis using outcome-driven multi-task neural network as promising for patient classification and subtyping.