 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTicktack : Long Span Temporal Alignment of Large Language Models Leveraging Sexagenary Cycle Time Expression
Mar 07, 2025Large language models (LLMs) suffer from temporal misalignment issues especially across long span of time. The issue arises from knowing that LLMs are trained on large amounts of data where temporal information is rather sparse over long times, such as thousands of years, resulting in insufficient learning or catastrophic forgetting by the LLMs. This paper proposes a methodology named "Ticktack" for addressing the LLM's long-time span misalignment in a yearly setting. Specifically, we first propose to utilize the sexagenary year expression instead of the Gregorian year expression employed by LLMs, achieving a more uniform distribution in yearly granularity. Then, we employ polar coordinates to model the sexagenary cycle of 60 terms and the year order within each term, with additional temporal encoding to ensure LLMs understand them. Finally, we present a temporal representational alignment approach for post-training LLMs that effectively distinguishes time points with relevant knowledge, hence improving performance on time-related tasks, particularly over a long period. We also create a long time span benchmark for evaluation. Experimental results prove the effectiveness of our proposal.
Towards Comprehensive Preference Data Collection for Reward Modeling
Jun 24, 2024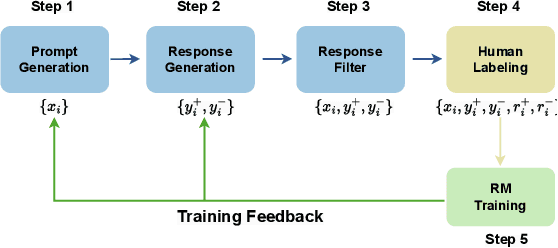

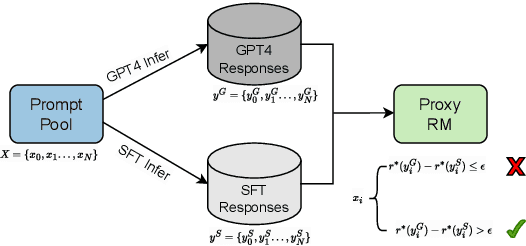
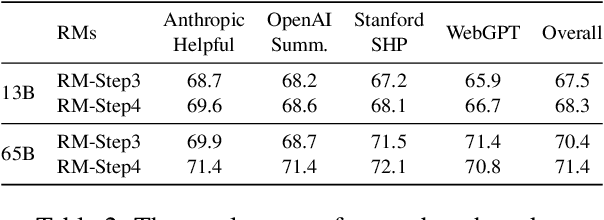
Reinforcement Learning from Human Feedback (RLHF) facilitates the alignment of large language models (LLMs) with human preferences, thereby enhancing the quality of responses generated. A critical component of RLHF is the reward model, which is trained on preference data and outputs a scalar reward during the inference stage. However, the collection of preference data still lacks thorough investigation. Recent studies indicate that preference data is collected either by AI or humans, where chosen and rejected instances are identified among pairwise responses. We question whether this process effectively filters out noise and ensures sufficient diversity in collected data. To address these concerns, for the first time, we propose a comprehensive framework for preference data collection, decomposing the process into four incremental steps: Prompt Generation, Response Generation, Response Filtering, and Human Labeling. This structured approach ensures the collection of high-quality preferences while reducing reliance on human labor. We conducted comprehensive experiments based on the data collected at different stages, demonstrating the effectiveness of the proposed data collection method.
Automatic Business Process Structure Discovery using Ordered Neurons LSTM: A Preliminary Study
Jan 05, 2020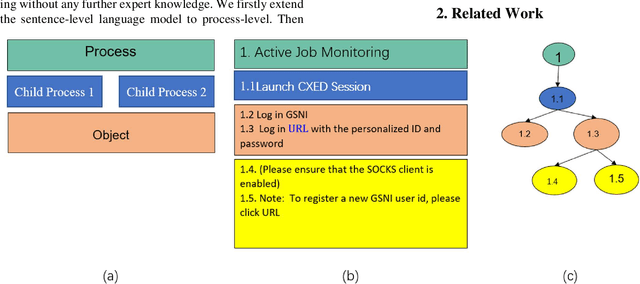
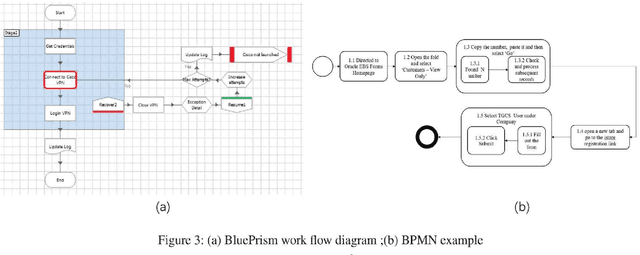
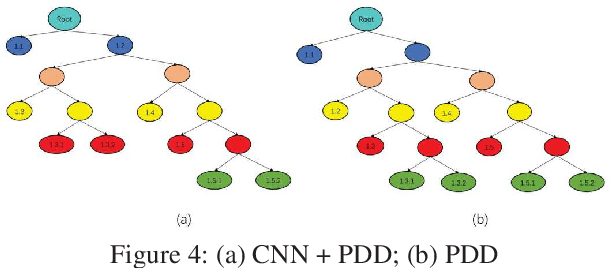
Automatic process discovery from textual process documentations is highly desirable to reduce time and cost of Business Process Management (BPM) implementation in organizations. However, existing automatic process discovery approaches mainly focus on identifying activities out of the documentations. Deriving the structural relationships between activities, which is important in the whole process discovery scope, is still a challenge. In fact, a business process has latent semantic hierarchical structure which defines different levels of detail to reflect the complex business logic. Recent findings in neural machine learning area show that the meaningful linguistic structure can be induced by joint language modeling and structure learning. Inspired by these findings, we propose to retrieve the latent hierarchical structure present in the textual business process documents by building a neural network that leverages a novel recurrent architecture, Ordered Neurons LSTM (ON-LSTM), with process-level language model objective. We tested the proposed approach on data set of Process Description Documents (PDD) from our practical Robotic Process Automation (RPA) projects. Preliminary experiments showed promising results.