 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEGRL: Improving Machine Translation by Post-Editing Guided Reinforcement Learning
Feb 03, 2026Reinforcement learning (RL) has shown strong promise for LLM-based machine translation, with recent methods such as GRPO demonstrating notable gains; nevertheless, translation-oriented RL remains challenged by noisy learning signals arising from Monte Carlo return estimation, as well as a large trajectory space that favors global exploration over fine-grained local optimization. We introduce \textbf{PEGRL}, a \textit{two-stage} RL framework that uses post-editing as an auxiliary task to stabilize training and guide overall optimization. At each iteration, translation outputs are sampled to construct post-editing inputs, allowing return estimation in the post-editing stage to benefit from conditioning on the current translation behavior, while jointly supporting both global exploration and fine-grained local optimization. A task-specific weighting scheme further balances the contributions of translation and post-editing objectives, yielding a biased yet more sample-efficient estimator. Experiments on English$\to$Finnish, English$\to$Turkish, and English$\leftrightarrow$Chinese show consistent gains over RL baselines, and for English$\to$Turkish, performance on COMET-KIWI is comparable to advanced LLM-based systems (DeepSeek-V3.2).
Align to the Pivot: Dual Alignment with Self-Feedback for Multilingual Math Reasoning
Jan 25, 2026Despite the impressive reasoning abilities demonstrated by large language models (LLMs), empirical evidence indicates that they are not language agnostic as expected, leading to performance declines in multilingual settings, especially for low-resource languages. We attribute the decline to the model's inconsistent multilingual understanding and reasoning alignment. To address this, we present Pivot-Aligned Self-Feedback Multilingual Reasoning (PASMR), aiming to improve the alignment of multilingual math reasoning abilities in LLMs. This approach designates the model's primary language as the pivot language. During training, the model first translates questions into the pivot language to facilitate better alignment of reasoning patterns. The reasoning process in the target language is then supervised by the pivot language's reasoning answers, thereby establishing a cross-lingual self-feedback mechanism without relying on external correct answers or reward models. Extensive experimental results demonstrate that our method enhances both the model's understanding of questions and its reasoning capabilities, leading to notable task improvements.
Understanding LLMs' Cross-Lingual Context Retrieval: How Good It Is And Where It Comes From
Apr 15, 2025
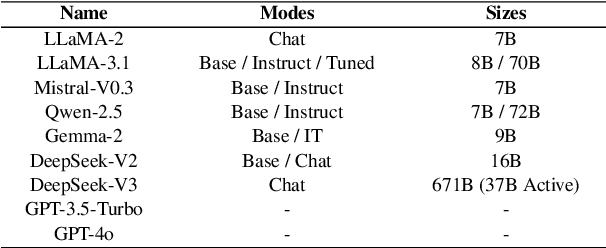
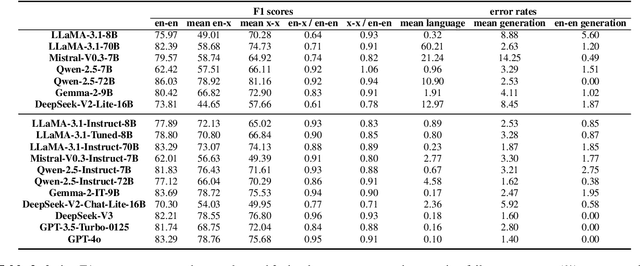
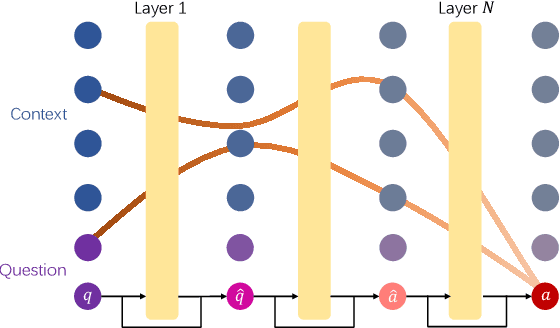
The ability of cross-lingual context retrieval is a fundamental aspect of cross-lingual alignment of large language models (LLMs), where the model extracts context information in one language based on requests in another language. Despite its importance in real-life applications, this ability has not been adequately investigated for state-of-the-art models. In this paper, we evaluate the cross-lingual context retrieval ability of over 40 LLMs across 12 languages to understand the source of this ability, using cross-lingual machine reading comprehension (xMRC) as a representative scenario. Our results show that several small, post-trained open LLMs show strong cross-lingual context retrieval ability, comparable to closed-source LLMs such as GPT-4o, and their estimated oracle performances greatly improve after post-training. Our interpretability analysis shows that the cross-lingual context retrieval process can be divided into two main phases: question encoding and answer retrieval, which are formed in pre-training and post-training, respectively. The phasing stability correlates with xMRC performance, and the xMRC bottleneck lies at the last model layers in the second phase, where the effect of post-training can be evidently observed. Our results also indicate that larger-scale pretraining cannot improve the xMRC performance. Instead, larger LLMs need further multilingual post-training to fully unlock their cross-lingual context retrieval potential. Our code and is available at https://github.com/NJUNLP/Cross-Lingual-Context-Retrieval
Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training
Apr 02, 2025Large language models (LLMs) exhibit remarkable multilingual capabilities despite the extreme language imbalance in the pre-training data. In this paper, we closely examine the reasons behind this phenomenon, focusing on the pre-training corpus. We find that the existence of code-switching, alternating between different languages within a context, is key to multilingual capabilities. We conduct an analysis to investigate code-switching in the pre-training corpus, examining its presence and categorizing it into four types within two quadrants. We then assess its impact on multilingual performance. These types of code-switching data are unbalanced in proportions and demonstrate different effects on facilitating language transfer. To better explore the power of code-switching for language alignment during pre-training, we investigate the strategy of synthetic code-switching. We continuously scale up the synthetic code-switching data and observe remarkable improvements in both benchmarks and representation space. Extensive experiments indicate that incorporating synthetic code-switching data enables better language alignment and generalizes well to high, medium, and low-resource languages with pre-training corpora of varying qualities.
Ticktack : Long Span Temporal Alignment of Large Language Models Leveraging Sexagenary Cycle Time Expression
Mar 07, 2025Large language models (LLMs) suffer from temporal misalignment issues especially across long span of time. The issue arises from knowing that LLMs are trained on large amounts of data where temporal information is rather sparse over long times, such as thousands of years, resulting in insufficient learning or catastrophic forgetting by the LLMs. This paper proposes a methodology named "Ticktack" for addressing the LLM's long-time span misalignment in a yearly setting. Specifically, we first propose to utilize the sexagenary year expression instead of the Gregorian year expression employed by LLMs, achieving a more uniform distribution in yearly granularity. Then, we employ polar coordinates to model the sexagenary cycle of 60 terms and the year order within each term, with additional temporal encoding to ensure LLMs understand them. Finally, we present a temporal representational alignment approach for post-training LLMs that effectively distinguishes time points with relevant knowledge, hence improving performance on time-related tasks, particularly over a long period. We also create a long time span benchmark for evaluation. Experimental results prove the effectiveness of our proposal.
A new framework for X-ray absorption spectroscopy data analysis based on machine learning: XASDAML
Feb 23, 2025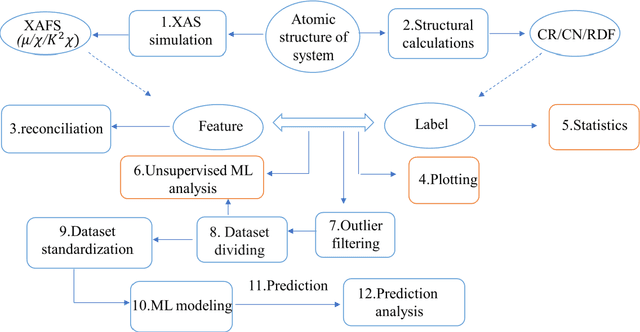

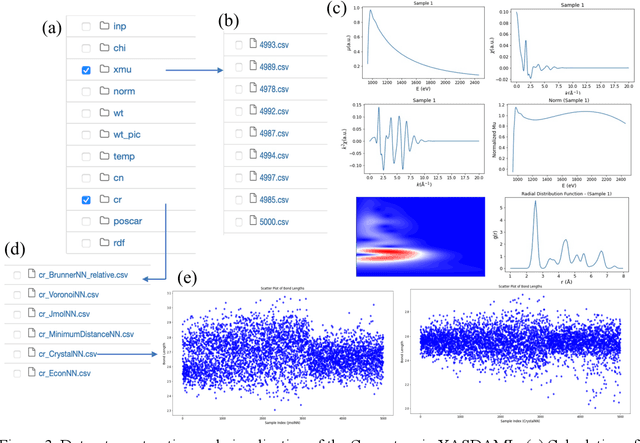
X-ray absorption spectroscopy (XAS) is a powerful technique to probe the electronic and structural properties of materials. With the rapid growth in both the volume and complexity of XAS datasets driven by advancements in synchrotron radiation facilities, there is an increasing demand for advanced computational tools capable of efficiently analyzing large-scale data. To address these needs, we introduce XASDAML,a flexible, machine learning based framework that integrates the entire data-processing workflow-including dataset construction for spectra and structural descriptors, data filtering, ML modeling, prediction, and model evaluation-into a unified platform. Additionally, it supports comprehensive statistical analysis, leveraging methods such as principal component analysis and clustering to reveal potential patterns and relationships within large datasets. Each module operates independently, allowing users to modify or upgrade modules in response to evolving research needs or technological advances. Moreover, the platform provides a user-friendly interface via Jupyter Notebook, making it accessible to researchers at varying levels of expertise. The versatility and effectiveness of XASDAML are exemplified by its application to a copper dataset, where it efficiently manages large and complex data, supports both supervised and unsupervised machine learning models, provides comprehensive statistics for structural descriptors, generates spectral plots, and accurately predicts coordination numbers and bond lengths. Furthermore, the platform streamlining the integration of XAS with machine learning and lowering the barriers to entry for new users.
MoE-LPR: Multilingual Extension of Large Language Models through Mixture-of-Experts with Language Priors Routing
Aug 21, 2024



Large Language Models (LLMs) are often English-centric due to the disproportionate distribution of languages in their pre-training data. Enhancing non-English language capabilities through post-pretraining often results in catastrophic forgetting of the ability of original languages. Previous methods either achieve good expansion with severe forgetting or slight forgetting with poor expansion, indicating the challenge of balancing language expansion while preventing forgetting. In this paper, we propose a method called MoE-LPR (Mixture-of-Experts with Language Priors Routing) to alleviate this problem. MoE-LPR employs a two-stage training approach to enhance the multilingual capability. First, the model is post-pretrained into a Mixture-of-Experts (MoE) architecture by upcycling, where all the original parameters are frozen and new experts are added. In this stage, we focus improving the ability on expanded languages, without using any original language data. Then, the model reviews the knowledge of the original languages with replay data amounting to less than 1% of post-pretraining, where we incorporate language priors routing to better recover the abilities of the original languages. Evaluations on multiple benchmarks show that MoE-LPR outperforms other post-pretraining methods. Freezing original parameters preserves original language knowledge while adding new experts preserves the learning ability. Reviewing with LPR enables effective utilization of multilingual knowledge within the parameters. Additionally, the MoE architecture maintains the same inference overhead while increasing total model parameters. Extensive experiments demonstrate MoE-LPR's effectiveness in improving expanded languages and preserving original language proficiency with superior scalability. Code and scripts are freely available at https://github.com/zjwang21/MoE-LPR.git.
Large Language Models Are Cross-Lingual Knowledge-Free Reasoners
Jun 24, 2024



Large Language Models have demonstrated impressive reasoning capabilities across multiple languages. However, the relationship between capabilities in different languages is less explored. In this work, we decompose the process of reasoning tasks into two separated parts: knowledge retrieval and knowledge-free reasoning, and analyze the cross-lingual transferability of them. With adapted and constructed knowledge-free reasoning datasets, we show that the knowledge-free reasoning capability can be nearly perfectly transferred across various source-target language directions despite the secondary impact of resource in some specific target languages, while cross-lingual knowledge retrieval significantly hinders the transfer. Moreover, by analyzing the hidden states and feed-forward network neuron activation during the reasoning tasks, we show that higher similarity of hidden representations and larger overlap of activated neurons could explain the better cross-lingual transferability of knowledge-free reasoning than knowledge retrieval. Thus, we hypothesize that knowledge-free reasoning embeds in some language-shared mechanism, while knowledge is stored separately in different languages.
Large Language Models are Good Spontaneous Multilingual Learners: Is the Multilingual Annotated Data Necessary?
May 22, 2024



Recently, Large Language Models (LLMs) have shown impressive language capabilities. However, most of the existing LLMs are all English-centric, which have very unstable and unbalanced performance across different languages. Multilingual alignment is an effective method to enhance the LLMs' multilingual capabilities. In this work, we explore the multilingual alignment paradigm which utilizes translation data and comprehensively investigate the spontaneous multilingual improvement of LLMs. We find that LLMs only instruction-tuned on question translation data without annotated answers are able to get significant multilingual performance enhancement even across a wide range of languages unseen during instruction-tuning. Additionally, we utilize different settings and mechanistic interpretability methods to comprehensively analyze the LLM's performance in the multilingual scenario.
Real-time Neuron Segmentation for Voltage Imaging
Mar 25, 2024In voltage imaging, where the membrane potentials of individual neurons are recorded at from hundreds to thousand frames per second using fluorescence microscopy, data processing presents a challenge. Even a fraction of a minute of recording with a limited image size yields gigabytes of video data consisting of tens of thousands of frames, which can be time-consuming to process. Moreover, millisecond-level short exposures lead to noisy video frames, obscuring neuron footprints especially in deep-brain samples where noisy signals are buried in background fluorescence. To address this challenge, we propose a fast neuron segmentation method able to detect multiple, potentially overlapping, spiking neurons from noisy video frames, and implement a data processing pipeline incorporating the proposed segmentation method along with GPU-accelerated motion correction. By testing on existing datasets as well as on new datasets we introduce, we show that our pipeline extracts neuron footprints that agree well with human annotation even from cluttered datasets, and demonstrate real-time processing of voltage imaging data on a single desktop computer for the first time.