 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LLMs' Cross-Lingual Context Retrieval: How Good It Is And Where It Comes From
Apr 15, 2025
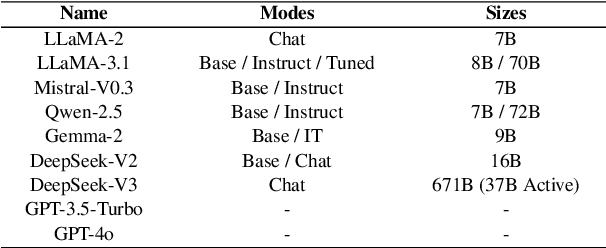
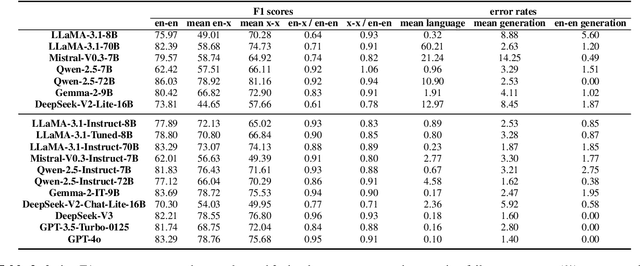
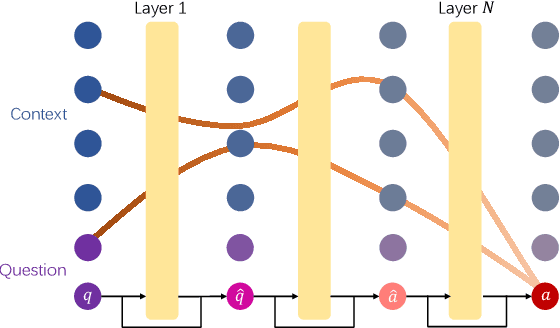
The ability of cross-lingual context retrieval is a fundamental aspect of cross-lingual alignment of large language models (LLMs), where the model extracts context information in one language based on requests in another language. Despite its importance in real-life applications, this ability has not been adequately investigated for state-of-the-art models. In this paper, we evaluate the cross-lingual context retrieval ability of over 40 LLMs across 12 languages to understand the source of this ability, using cross-lingual machine reading comprehension (xMRC) as a representative scenario. Our results show that several small, post-trained open LLMs show strong cross-lingual context retrieval ability, comparable to closed-source LLMs such as GPT-4o, and their estimated oracle performances greatly improve after post-training. Our interpretability analysis shows that the cross-lingual context retrieval process can be divided into two main phases: question encoding and answer retrieval, which are formed in pre-training and post-training, respectively. The phasing stability correlates with xMRC performance, and the xMRC bottleneck lies at the last model layers in the second phase, where the effect of post-training can be evidently observed. Our results also indicate that larger-scale pretraining cannot improve the xMRC performance. Instead, larger LLMs need further multilingual post-training to fully unlock their cross-lingual context retrieval potential. Our code and is available at https://github.com/NJUNLP/Cross-Lingual-Context-Retrieval