 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow does Alignment Enhance LLMs' Multilingual Capabilities? A Language Neurons Perspective
May 27, 2025Multilingual Alignment is an effective and representative paradigm to enhance LLMs' multilingual capabilities, which transfers the capabilities from the high-resource languages to the low-resource languages. Meanwhile, some researches on language-specific neurons reveal that there are language-specific neurons that are selectively activated in LLMs when processing different languages. This provides a new perspective to analyze and understand LLMs' mechanisms more specifically in multilingual scenarios. In this work, we propose a new finer-grained neuron identification algorithm, which detects language neurons~(including language-specific neurons and language-related neurons) and language-agnostic neurons. Furthermore, based on the distributional characteristics of different types of neurons, we divide the LLMs' internal process for multilingual inference into four parts: (1) multilingual understanding, (2) shared semantic space reasoning, (3) multilingual output space transformation, and (4) vocabulary space outputting. Additionally, we systematically analyze the models before and after alignment with a focus on different types of neurons. We also analyze the phenomenon of ''Spontaneous Multilingual Alignment''. Overall, our work conducts a comprehensive investigation based on different types of neurons, providing empirical results and valuable insights for better understanding multilingual alignment and multilingual capabilities of LLMs.
PATS: Process-Level Adaptive Thinking Mode Switching
May 25, 2025Current large-language models (LLMs) typically adopt a fixed reasoning strategy, either simple or complex, for all questions, regardless of their difficulty. This neglect of variation in task and reasoning process complexity leads to an imbalance between performance and efficiency. Existing methods attempt to implement training-free fast-slow thinking system switching to handle problems of varying difficulty, but are limited by coarse-grained solution-level strategy adjustments. To address this issue, we propose a novel reasoning paradigm: Process-Level Adaptive Thinking Mode Switching (PATS), which enables LLMs to dynamically adjust their reasoning strategy based on the difficulty of each step, optimizing the balance between accuracy and computational efficiency. Our approach integrates Process Reward Models (PRMs) with Beam Search, incorporating progressive mode switching and bad-step penalty mechanisms. Experiments on diverse mathematical benchmarks demonstrate that our methodology achieves high accuracy while maintaining moderate token usage. This study emphasizes the significance of process-level, difficulty-aware reasoning strategy adaptation, offering valuable insights into efficient inference for LLMs.
Process-based Self-Rewarding Language Models
Mar 05, 2025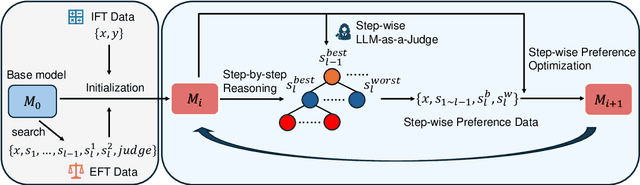
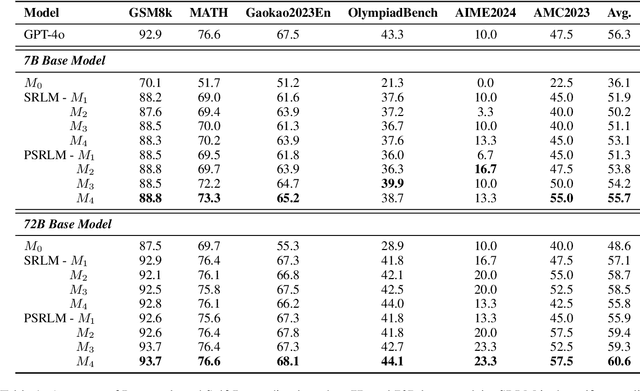

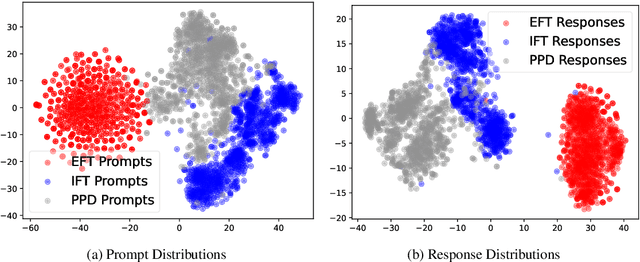
Large Language Models have demonstrated outstanding performance across various downstream tasks and have been widely applied in multiple scenarios. Human-annotated preference data is used for training to further improve LLMs' performance, which is constrained by the upper limit of human performance. Therefore, Self-Rewarding method has been proposed, where LLMs generate training data by rewarding their own outputs. However, the existing self-rewarding paradigm is not effective in mathematical reasoning scenarios and may even lead to a decline in performance. In this work, we propose the Process-based Self-Rewarding pipeline for language models, which introduces long-thought reasoning, step-wise LLM-as-a-Judge, and step-wise preference optimization within the self-rewarding paradigm. Our new paradigm successfully enhances the performance of LLMs on multiple mathematical reasoning benchmarks through iterative Process-based Self-Rewarding, demonstrating the immense potential of self-rewarding to achieve LLM reasoning that may surpass human capabilities.
Large Language Models are Good Spontaneous Multilingual Learners: Is the Multilingual Annotated Data Necessary?
May 22, 2024



Recently, Large Language Models (LLMs) have shown impressive language capabilities. However, most of the existing LLMs are all English-centric, which have very unstable and unbalanced performance across different languages. Multilingual alignment is an effective method to enhance the LLMs' multilingual capabilities. In this work, we explore the multilingual alignment paradigm which utilizes translation data and comprehensively investigate the spontaneous multilingual improvement of LLMs. We find that LLMs only instruction-tuned on question translation data without annotated answers are able to get significant multilingual performance enhancement even across a wide range of languages unseen during instruction-tuning. Additionally, we utilize different settings and mechanistic interpretability methods to comprehensively analyze the LLM's performance in the multilingual scenario.
EDT: Improving Large Language Models' Generation by Entropy-based Dynamic Temperature Sampling
Mar 21, 2024



Recently, Large Language Models (LLMs) have demonstrated outstanding performance across a wide range of downstream language tasks. Temperature sampling is a commonly used decoding strategy for LLMs' generation process. However, a fixed temperature parameter is used in most cases, which may not always be an optimal choice for balancing generation quality and diversity. In this paper, we propose an effective Entropy-based Dynamic Temperature (EDT) Sampling method, to achieve a more balanced performance in terms of both generation quality and diversity by dynamically selecting the temperature parameter. Additionally, we also show model performance and comprehensive analyses for 4 different generation benchmarks. Our experiments show that EDT significantly outperforms the existing strategies across different tasks.