 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models: A Comprehensive Survey of Architectures, Methodologies, Reasoning Paradigms, and Applications
May 28, 2026World models, internal simulators that learn the structure and dynamics of an environment, have emerged as a central paradigm in the pursuit of artificial general intelligence, enabling agents to predict, plan, and reason within learned representations. Despite rapid progress across reinforcement learning, robotics, autonomous driving, and video generation, the field lacks a unified framework integrating its diverse architectural choices, training methods, reasoning mechanisms, and application settings. This survey addresses that gap with a multi-axis taxonomy organized along four dimensions: (i) architecture, encompassing representation format, dynamics formulation, input modality, learning paradigm, and downstream application; (ii) methodological family, including state-space and recurrent approaches, transformer-based models, diffusion-based generators, physics-informed networks, and language-augmented multimodal systems; (iii) reasoning strategy, covering imagination-based planning, latent policy learning, counterfactual reasoning, and planning under uncertainty; and (iv) application domain, spanning robotics, autonomous driving, video prediction, multimodal agents, reinforcement learning, scientific modeling, medical imaging, educational measurement, and business and finance. Tracing the field from early cognitive-science foundations to milestone systems such as PlaNet, the Dreamer family, MuZero, Sora, Cosmos, and Genie, we examine how these dimensions interact and highlight the recent convergence of chain-of-thought reasoning with world-model imagination. We review evaluation protocols and benchmarks, identify persistent challenges such as compounding prediction errors, sim-to-real transfer, and fragmented evaluation, and outline future directions toward unified multimodal world models, foundation-scale interactive simulators, and safe deployment in safety-critical domains.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Aug 26, 2025



While Mixture of Experts (MoE) models achieve remarkable efficiency by activating only subsets of parameters, they suffer from high memory access costs during inference. Memory-layer architectures offer an appealing alternative with very few memory access, but previous attempts like UltraMem have only matched the performance of 2-expert MoE models, falling significantly short of state-of-the-art 8-expert configurations. We present UltraMemV2, a redesigned memory-layer architecture that closes this performance gap. Our approach introduces five key improvements: integrating memory layers into every transformer block, simplifying value expansion with single linear projections, adopting FFN-based value processing from PEER, implementing principled parameter initialization, and rebalancing memory-to-FFN computation ratios. Through extensive evaluation, we demonstrate that UltraMemV2 achieves performance parity with 8-expert MoE models under same computation and parameters but significantly low memory access. Notably, UltraMemV2 shows superior performance on memory-intensive tasks, with improvements of +1.6 points on long-context memorization, +6.2 points on multi-round memorization, and +7.9 points on in-context learning. We validate our approach at scale with models up to 2.5B activated parameters from 120B total parameters, and establish that activation density has greater impact on performance than total sparse parameter count. Our work brings memory-layer architectures to performance parity with state-of-the-art MoE models, presenting a compelling alternative for efficient sparse computation.
DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
Aug 20, 2025We present DuPO, a dual learning-based preference optimization framework that generates annotation-free feedback via a generalized duality. DuPO addresses two key limitations: Reinforcement Learning with Verifiable Rewards (RLVR)'s reliance on costly labels and applicability restricted to verifiable tasks, and traditional dual learning's restriction to strictly dual task pairs (e.g., translation and back-translation). Specifically, DuPO decomposes a primal task's input into known and unknown components, then constructs its dual task to reconstruct the unknown part using the primal output and known information (e.g., reversing math solutions to recover hidden variables), broadening applicability to non-invertible tasks. The quality of this reconstruction serves as a self-supervised reward to optimize the primal task, synergizing with LLMs' ability to instantiate both tasks via a single model. Empirically, DuPO achieves substantial gains across diverse tasks: it enhances the average translation quality by 2.13 COMET over 756 directions, boosts the mathematical reasoning accuracy by an average of 6.4 points on three challenge benchmarks, and enhances performance by 9.3 points as an inference-time reranker (trading computation for accuracy). These results position DuPO as a scalable, general, and annotation-free paradigm for LLM optimization.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
HOME-3: High-Order Momentum Estimator with Third-Power Gradient for Convex and Smooth Nonconvex Optimization
May 16, 2025Momentum-based gradients are essential for optimizing advanced machine learning models, as they not only accelerate convergence but also advance optimizers to escape stationary points. While most state-of-the-art momentum techniques utilize lower-order gradients, such as the squared first-order gradient, there has been limited exploration of higher-order gradients, particularly those raised to powers greater than two. In this work, we introduce the concept of high-order momentum, where momentum is constructed using higher-power gradients, with a focus on the third-power of the first-order gradient as a representative case. Our research offers both theoretical and empirical support for this approach. Theoretically, we demonstrate that incorporating third-power gradients can improve the convergence bounds of gradient-based optimizers for both convex and smooth nonconvex problems. Empirically, we validate these findings through extensive experiments across convex, smooth nonconvex, and nonsmooth nonconvex optimization tasks. Across all cases, high-order momentum consistently outperforms conventional low-order momentum methods, showcasing superior performance in various optimization problems.
Permutation Randomization on Nonsmooth Nonconvex Optimization: A Theoretical and Experimental Study
May 16, 2025While gradient-based optimizers that incorporate randomization often showcase superior performance on complex optimization, the theoretical foundations underlying this superiority remain insufficiently understood. A particularly pressing question has emerged: What is the role of randomization in dimension-free nonsmooth nonconvex optimization? To address this gap, we investigate the theoretical and empirical impact of permutation randomization within gradient-based optimization frameworks, using it as a representative case to explore broader implications. From a theoretical perspective, our analyses reveal that permutation randomization disrupts the shrinkage behavior of gradient-based optimizers, facilitating continuous convergence toward the global optimum given a sufficiently large number of iterations. Additionally, we prove that permutation randomization can preserve the convergence rate of the underlying optimizer. On the empirical side, we conduct extensive numerical experiments comparing permutation-randomized optimizer against three baseline methods. These experiments span tasks such as training deep neural networks with stacked architectures and optimizing noisy objective functions. The results not only corroborate our theoretical insights but also highlight the practical benefits of permutation randomization. In summary, this work delivers both rigorous theoretical justification and compelling empirical evidence for the effectiveness of permutation randomization. Our findings and evidence lay a foundation for extending analytics to encompass a wide array of randomization.
Trans-Zero: Self-Play Incentivizes Large Language Models for Multilingual Translation Without Parallel Data
Apr 20, 2025The rise of Large Language Models (LLMs) has reshaped machine translation (MT), but multilingual MT still relies heavily on parallel data for supervised fine-tuning (SFT), facing challenges like data scarcity for low-resource languages and catastrophic forgetting. To address these issues, we propose TRANS-ZERO, a self-play framework that leverages only monolingual data and the intrinsic multilingual knowledge of LLM. TRANS-ZERO combines Genetic Monte-Carlo Tree Search (G-MCTS) with preference optimization, achieving strong translation performance that rivals supervised methods. Experiments demonstrate that this approach not only matches the performance of models trained on large-scale parallel data but also excels in non-English translation directions. Further analysis reveals that G-MCTS itself significantly enhances translation quality by exploring semantically consistent candidates through iterative translations, providing a robust foundation for the framework's succuss.
Unveiling the Mathematical Reasoning in DeepSeek Models: A Comparative Study of Large Language Models
Mar 13, 2025



With the rapid evolution of Artificial Intelligence (AI), Large Language Models (LLMs) have reshaped the frontiers of various fields, spanning healthcare, public health, engineering, science, agriculture, education, arts, humanities, and mathematical reasoning. Among these advancements, DeepSeek models have emerged as noteworthy contenders, demonstrating promising capabilities that set them apart from their peers. While previous studies have conducted comparative analyses of LLMs, few have delivered a comprehensive evaluation of mathematical reasoning across a broad spectrum of LLMs. In this work, we aim to bridge this gap by conducting an in-depth comparative study, focusing on the strengths and limitations of DeepSeek models in relation to their leading counterparts. In particular, our study systematically evaluates the mathematical reasoning performance of two DeepSeek models alongside five prominent LLMs across three independent benchmark datasets. The findings reveal several key insights: 1). DeepSeek-R1 consistently achieved the highest accuracy on two of the three datasets, demonstrating strong mathematical reasoning capabilities. 2). The distilled variant of LLMs significantly underperformed compared to its peers, highlighting potential drawbacks in using distillation techniques. 3). In terms of response time, Gemini 2.0 Flash demonstrated the fastest processing speed, outperforming other models in efficiency, which is a crucial factor for real-time applications. Beyond these quantitative assessments, we delve into how architecture, training, and optimization impact LLMs' mathematical reasoning. Moreover, our study goes beyond mere performance comparison by identifying key areas for future advancements in LLM-driven mathematical reasoning. This research enhances our understanding of LLMs' mathematical reasoning and lays the groundwork for future advancements
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024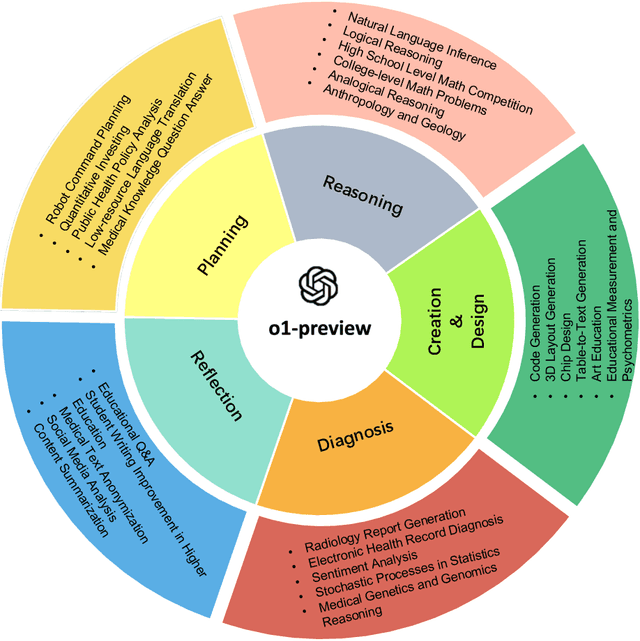


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.