 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOME-3: High-Order Momentum Estimator with Third-Power Gradient for Convex and Smooth Nonconvex Optimization
May 16, 2025Momentum-based gradients are essential for optimizing advanced machine learning models, as they not only accelerate convergence but also advance optimizers to escape stationary points. While most state-of-the-art momentum techniques utilize lower-order gradients, such as the squared first-order gradient, there has been limited exploration of higher-order gradients, particularly those raised to powers greater than two. In this work, we introduce the concept of high-order momentum, where momentum is constructed using higher-power gradients, with a focus on the third-power of the first-order gradient as a representative case. Our research offers both theoretical and empirical support for this approach. Theoretically, we demonstrate that incorporating third-power gradients can improve the convergence bounds of gradient-based optimizers for both convex and smooth nonconvex problems. Empirically, we validate these findings through extensive experiments across convex, smooth nonconvex, and nonsmooth nonconvex optimization tasks. Across all cases, high-order momentum consistently outperforms conventional low-order momentum methods, showcasing superior performance in various optimization problems.
Permutation Randomization on Nonsmooth Nonconvex Optimization: A Theoretical and Experimental Study
May 16, 2025While gradient-based optimizers that incorporate randomization often showcase superior performance on complex optimization, the theoretical foundations underlying this superiority remain insufficiently understood. A particularly pressing question has emerged: What is the role of randomization in dimension-free nonsmooth nonconvex optimization? To address this gap, we investigate the theoretical and empirical impact of permutation randomization within gradient-based optimization frameworks, using it as a representative case to explore broader implications. From a theoretical perspective, our analyses reveal that permutation randomization disrupts the shrinkage behavior of gradient-based optimizers, facilitating continuous convergence toward the global optimum given a sufficiently large number of iterations. Additionally, we prove that permutation randomization can preserve the convergence rate of the underlying optimizer. On the empirical side, we conduct extensive numerical experiments comparing permutation-randomized optimizer against three baseline methods. These experiments span tasks such as training deep neural networks with stacked architectures and optimizing noisy objective functions. The results not only corroborate our theoretical insights but also highlight the practical benefits of permutation randomization. In summary, this work delivers both rigorous theoretical justification and compelling empirical evidence for the effectiveness of permutation randomization. Our findings and evidence lay a foundation for extending analytics to encompass a wide array of randomization.
Unveiling the Mathematical Reasoning in DeepSeek Models: A Comparative Study of Large Language Models
Mar 13, 2025



With the rapid evolution of Artificial Intelligence (AI), Large Language Models (LLMs) have reshaped the frontiers of various fields, spanning healthcare, public health, engineering, science, agriculture, education, arts, humanities, and mathematical reasoning. Among these advancements, DeepSeek models have emerged as noteworthy contenders, demonstrating promising capabilities that set them apart from their peers. While previous studies have conducted comparative analyses of LLMs, few have delivered a comprehensive evaluation of mathematical reasoning across a broad spectrum of LLMs. In this work, we aim to bridge this gap by conducting an in-depth comparative study, focusing on the strengths and limitations of DeepSeek models in relation to their leading counterparts. In particular, our study systematically evaluates the mathematical reasoning performance of two DeepSeek models alongside five prominent LLMs across three independent benchmark datasets. The findings reveal several key insights: 1). DeepSeek-R1 consistently achieved the highest accuracy on two of the three datasets, demonstrating strong mathematical reasoning capabilities. 2). The distilled variant of LLMs significantly underperformed compared to its peers, highlighting potential drawbacks in using distillation techniques. 3). In terms of response time, Gemini 2.0 Flash demonstrated the fastest processing speed, outperforming other models in efficiency, which is a crucial factor for real-time applications. Beyond these quantitative assessments, we delve into how architecture, training, and optimization impact LLMs' mathematical reasoning. Moreover, our study goes beyond mere performance comparison by identifying key areas for future advancements in LLM-driven mathematical reasoning. This research enhances our understanding of LLMs' mathematical reasoning and lays the groundwork for future advancements
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024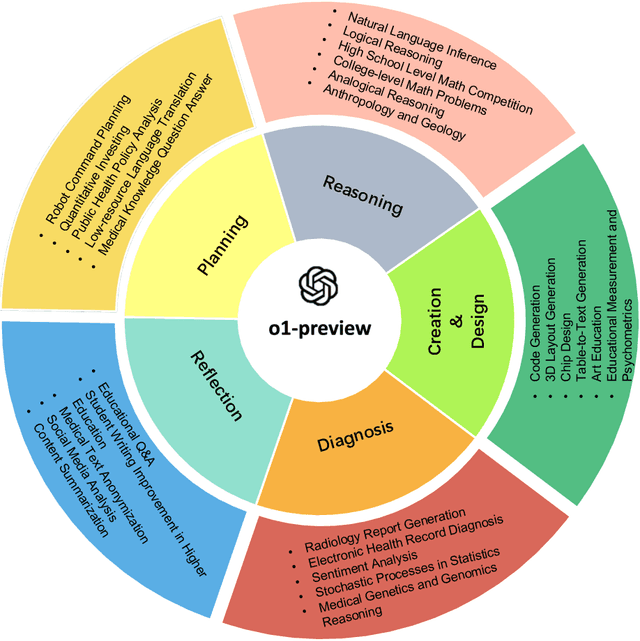


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.