 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounselReflect: A Toolkit for Auditing Mental-Health Dialogues
Mar 31, 2026Mental-health support is increasingly mediated by conversational systems (e.g., LLM-based tools), but users often lack structured ways to audit the quality and potential risks of the support they receive. We introduce CounselReflect, an end-to-end toolkit for auditing mental-health support dialogues. Rather than producing a single opaque quality score, CounselReflect provides structured, multi-dimensional reports with session-level summaries, turn-level scores, and evidence-linked excerpts to support transparent inspection. The system integrates two families of evaluation signals: (i) 12 model-based metrics produced by task-specific predictors, and (ii) rubric-based metrics that extend coverage via a literature-derived library (69 metrics) and user-defined custom metrics, operationalized with configurable LLM judges. CounselReflect is available as a web application, browser extension, and command-line interface (CLI), enabling use in real-time settings as well as at scale. Human evaluation includes a user study with 20 participants and an expert review with 6 mental-health professionals, suggesting that CounselReflect supports understandable, usable, and trustworthy auditing. A demo video and full source code are also provided.
Reverse Flow Matching: A Unified Framework for Online Reinforcement Learning with Diffusion and Flow Policies
Jan 13, 2026Diffusion and flow policies are gaining prominence in online reinforcement learning (RL) due to their expressive power, yet training them efficiently remains a critical challenge. A fundamental difficulty in online RL is the lack of direct samples from the target distribution; instead, the target is an unnormalized Boltzmann distribution defined by the Q-function. To address this, two seemingly distinct families of methods have been proposed for diffusion policies: a noise-expectation family, which utilizes a weighted average of noise as the training target, and a gradient-expectation family, which employs a weighted average of Q-function gradients. Yet, it remains unclear how these objectives relate formally or if they can be synthesized into a more general formulation. In this paper, we propose a unified framework, reverse flow matching (RFM), which rigorously addresses the problem of training diffusion and flow models without direct target samples. By adopting a reverse inferential perspective, we formulate the training target as a posterior mean estimation problem given an intermediate noisy sample. Crucially, we introduce Langevin Stein operators to construct zero-mean control variates, deriving a general class of estimators that effectively reduce importance sampling variance. We show that existing noise-expectation and gradient-expectation methods are two specific instances within this broader class. This unified view yields two key advancements: it extends the capability of targeting Boltzmann distributions from diffusion to flow policies, and enables the principled combination of Q-value and Q-gradient information to derive an optimal, minimum-variance estimator, thereby improving training efficiency and stability. We instantiate RFM to train a flow policy in online RL, and demonstrate improved performance on continuous-control benchmarks compared to diffusion policy baselines.
HardFlow: Hard-Constrained Sampling for Flow-Matching Models via Trajectory Optimization
Nov 11, 2025Diffusion and flow-matching have emerged as powerful methodologies for generative modeling, with remarkable success in capturing complex data distributions and enabling flexible guidance at inference time. Many downstream applications, however, demand enforcing hard constraints on generated samples (for example, robot trajectories must avoid obstacles), a requirement that goes beyond simple guidance. Prevailing projection-based approaches constrain the entire sampling path to the constraint manifold, which is overly restrictive and degrades sample quality. In this paper, we introduce a novel framework that reformulates hard-constrained sampling as a trajectory optimization problem. Our key insight is to leverage numerical optimal control to steer the sampling trajectory so that constraints are satisfied precisely at the terminal time. By exploiting the underlying structure of flow-matching models and adopting techniques from model predictive control, we transform this otherwise complex constrained optimization problem into a tractable surrogate that can be solved efficiently and effectively. Furthermore, this trajectory optimization perspective offers significant flexibility beyond mere constraint satisfaction, allowing for the inclusion of integral costs to minimize distribution shift and terminal objectives to further enhance sample quality, all within a unified framework. We provide a control-theoretic analysis of our method, establishing bounds on the approximation error between our tractable surrogate and the ideal formulation. Extensive experiments across diverse domains, including robotics (planning), partial differential equations (boundary control), and vision (text-guided image editing), demonstrate that our algorithm, which we name $\textit{HardFlow}$, substantially outperforms existing methods in both constraint satisfaction and sample quality.
Automatic Paper Reviewing with Heterogeneous Graph Reasoning over LLM-Simulated Reviewer-Author Debates
Nov 11, 2025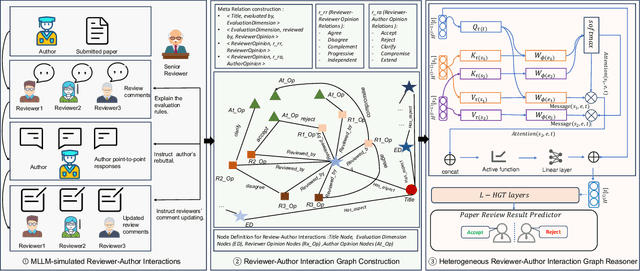
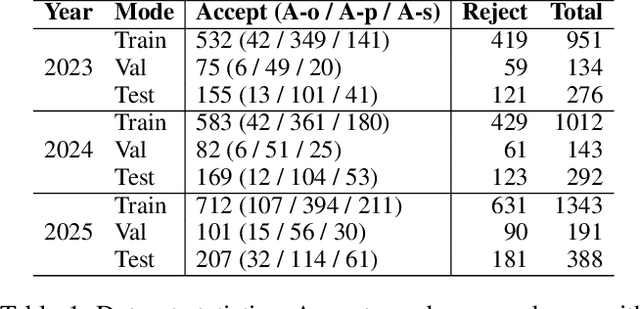
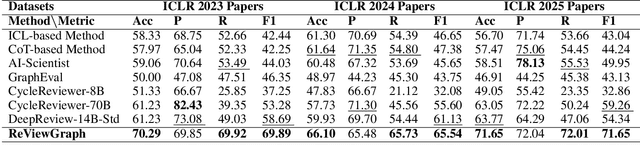
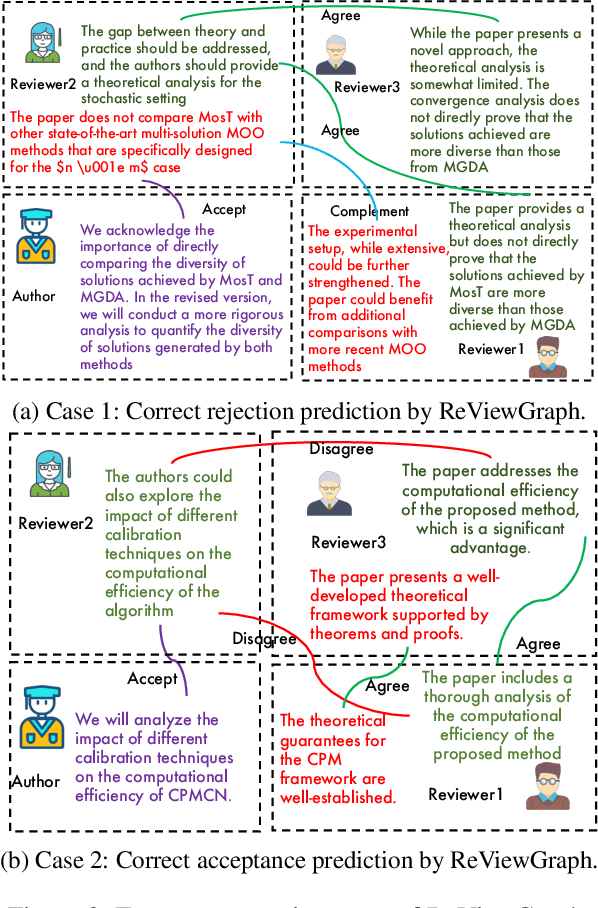
Existing paper review methods often rely on superficial manuscript features or directly on large language models (LLMs), which are prone to hallucinations, biased scoring, and limited reasoning capabilities. Moreover, these methods often fail to capture the complex argumentative reasoning and negotiation dynamics inherent in reviewer-author interactions. To address these limitations, we propose ReViewGraph (Reviewer-Author Debates Graph Reasoner), a novel framework that performs heterogeneous graph reasoning over LLM-simulated multi-round reviewer-author debates. In our approach, reviewer-author exchanges are simulated through LLM-based multi-agent collaboration. Diverse opinion relations (e.g., acceptance, rejection, clarification, and compromise) are then explicitly extracted and encoded as typed edges within a heterogeneous interaction graph. By applying graph neural networks to reason over these structured debate graphs, ReViewGraph captures fine-grained argumentative dynamics and enables more informed review decisions. Extensive experiments on three datasets demonstrate that ReViewGraph outperforms strong baselines with an average relative improvement of 15.73%, underscoring the value of modeling detailed reviewer-author debate structures.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
Channel-Aware Constellation Design for Digital OTA Computation
Jan 24, 2025



Over-the-air (OTA) computation has emerged as a promising technique for efficiently aggregating data from massive numbers of wireless devices. OTA computations can be performed by analog or digital communications. Analog OTA systems are often constrained by limited function adaptability and their reliance on analog amplitude modulation. On the other hand, digital OTA systems may face limitations such as high computational complexity and limited adaptability to varying network configurations. To address these challenges, this paper proposes a novel digital OTA computation system with a channel-aware constellation design for demodulation mappers. The proposed system dynamically adjusts the constellation based on the channel conditions of participating nodes, enabling reliable computation of various functions. By incorporating channel randomness into the constellation design, the system prevent overlap of constellation points, reduces computational complexity, and mitigates excessive transmit power consumption under poor channel conditions. Numerical results demonstrate that the system achieves reliable NMSE performance across a range of scenarios, offering valuable insights into the choice of signal processing methods and weighting strategies under varying computation point configurations, node counts, and quantization levels. This work advances the state of digital OTA computation by addressing critical challenges in scalability, transmit power consumption, and function adaptability.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Learning Predictive Safety Filter via Decomposition of Robust Invariant Set
Nov 12, 2023


Ensuring safety of nonlinear systems under model uncertainty and external disturbances is crucial, especially for real-world control tasks. Predictive methods such as robust model predictive control (RMPC) require solving nonconvex optimization problems online, which leads to high computational burden and poor scalability. Reinforcement learning (RL) works well with complex systems, but pays the price of losing rigorous safety guarantee. This paper presents a theoretical framework that bridges the advantages of both RMPC and RL to synthesize safety filters for nonlinear systems with state- and action-dependent uncertainty. We decompose the robust invariant set (RIS) into two parts: a target set that aligns with terminal region design of RMPC, and a reach-avoid set that accounts for the rest of RIS. We propose a policy iteration approach for robust reach-avoid problems and establish its monotone convergence. This method sets the stage for an adversarial actor-critic deep RL algorithm, which simultaneously synthesizes a reach-avoid policy network, a disturbance policy network, and a reach-avoid value network. The learned reach-avoid policy network is utilized to generate nominal trajectories for online verification, which filters potentially unsafe actions that may drive the system into unsafe regions when worst-case disturbances are applied. We formulate a second-order cone programming (SOCP) approach for online verification using system level synthesis, which optimizes for the worst-case reach-avoid value of any possible trajectories. The proposed safety filter requires much lower computational complexity than RMPC and still enjoys persistent robust safety guarantee. The effectiveness of our method is illustrated through a numerical example.
Robust Safe Reinforcement Learning under Adversarial Disturbances
Oct 11, 2023



Safety is a primary concern when applying reinforcement learning to real-world control tasks, especially in the presence of external disturbances. However, existing safe reinforcement learning algorithms rarely account for external disturbances, limiting their applicability and robustness in practice. To address this challenge, this paper proposes a robust safe reinforcement learning framework that tackles worst-case disturbances. First, this paper presents a policy iteration scheme to solve for the robust invariant set, i.e., a subset of the safe set, where persistent safety is only possible for states within. The key idea is to establish a two-player zero-sum game by leveraging the safety value function in Hamilton-Jacobi reachability analysis, in which the protagonist (i.e., control inputs) aims to maintain safety and the adversary (i.e., external disturbances) tries to break down safety. This paper proves that the proposed policy iteration algorithm converges monotonically to the maximal robust invariant set. Second, this paper integrates the proposed policy iteration scheme into a constrained reinforcement learning algorithm that simultaneously synthesizes the robust invariant set and uses it for constrained policy optimization. This algorithm tackles both optimality and safety, i.e., learning a policy that attains high rewards while maintaining safety under worst-case disturbances. Experiments on classic control tasks show that the proposed method achieves zero constraint violation with learned worst-case adversarial disturbances, while other baseline algorithms violate the safety constraints substantially. Our proposed method also attains comparable performance as the baselines even in the absence of the adversary.
Bridging the Gap between Newton-Raphson Method and Regularized Policy Iteration
Oct 11, 2023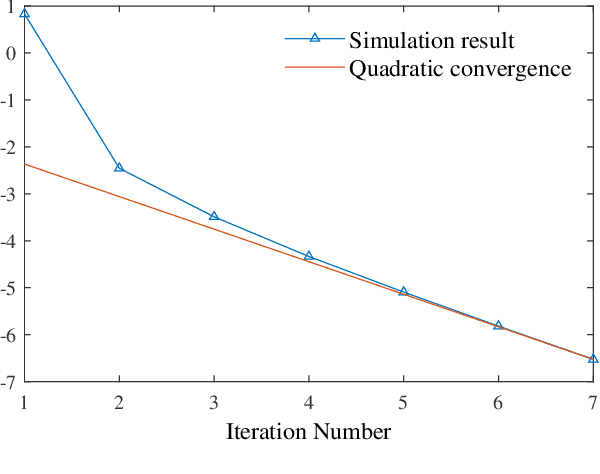
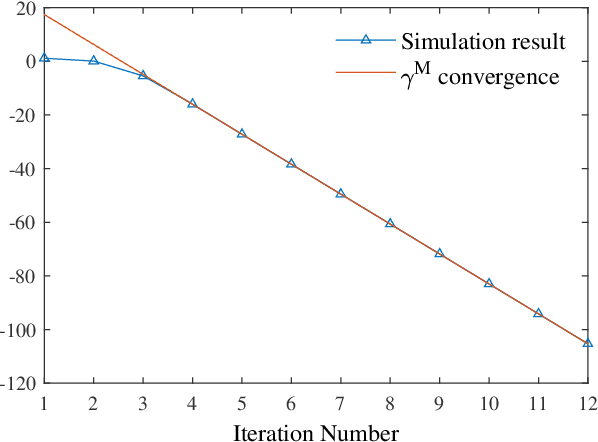
Regularization is one of the most important techniques in reinforcement learning algorithms. The well-known soft actor-critic algorithm is a special case of regularized policy iteration where the regularizer is chosen as Shannon entropy. Despite some empirical success of regularized policy iteration, its theoretical underpinnings remain unclear. This paper proves that regularized policy iteration is strictly equivalent to the standard Newton-Raphson method in the condition of smoothing out Bellman equation with strongly convex functions. This equivalence lays the foundation of a unified analysis for both global and local convergence behaviors of regularized policy iteration. We prove that regularized policy iteration has global linear convergence with the rate being $\gamma$ (discount factor). Furthermore, this algorithm converges quadratically once it enters a local region around the optimal value. We also show that a modified version of regularized policy iteration, i.e., with finite-step policy evaluation, is equivalent to inexact Newton method where the Newton iteration formula is solved with truncated iterations. We prove that the associated algorithm achieves an asymptotic linear convergence rate of $\gamma^M$ in which $M$ denotes the number of steps carried out in policy evaluation. Our results take a solid step towards a better understanding of the convergence properties of regularized policy iteration algorithms.