 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDADP: Domain Adaptive Diffusion Policy
Feb 03, 2026Learning domain adaptive policies that can generalize to unseen transition dynamics, remains a fundamental challenge in learning-based control. Substantial progress has been made through domain representation learning to capture domain-specific information, thus enabling domain-aware decision making. We analyze the process of learning domain representations through dynamical prediction and find that selecting contexts adjacent to the current step causes the learned representations to entangle static domain information with varying dynamical properties. Such mixture can confuse the conditioned policy, thereby constraining zero-shot adaptation. To tackle the challenge, we propose DADP (Domain Adaptive Diffusion Policy), which achieves robust adaptation through unsupervised disentanglement and domain-aware diffusion injection. First, we introduce Lagged Context Dynamical Prediction, a strategy that conditions future state estimation on a historical offset context; by increasing this temporal gap, we unsupervisedly disentangle static domain representations by filtering out transient properties. Second, we integrate the learned domain representations directly into the generative process by biasing the prior distribution and reformulating the diffusion target. Extensive experiments on challenging benchmarks across locomotion and manipulation demonstrate the superior performance, and the generalizability of DADP over prior methods. More visualization results are available on the https://outsider86.github.io/DomainAdaptiveDiffusionPolicy/.
Jump-Start Reinforcement Learning with Self-Evolving Priors for Extreme Monopedal Locomotion
Jul 01, 2025Reinforcement learning (RL) has shown great potential in enabling quadruped robots to perform agile locomotion. However, directly training policies to simultaneously handle dual extreme challenges, i.e., extreme underactuation and extreme terrains, as in monopedal hopping tasks, remains highly challenging due to unstable early-stage interactions and unreliable reward feedback. To address this, we propose JumpER (jump-start reinforcement learning via self-evolving priors), an RL training framework that structures policy learning into multiple stages of increasing complexity. By dynamically generating self-evolving priors through iterative bootstrapping of previously learned policies, JumpER progressively refines and enhances guidance, thereby stabilizing exploration and policy optimization without relying on external expert priors or handcrafted reward shaping. Specifically, when integrated with a structured three-stage curriculum that incrementally evolves action modality, observation space, and task objective, JumpER enables quadruped robots to achieve robust monopedal hopping on unpredictable terrains for the first time. Remarkably, the resulting policy effectively handles challenging scenarios that traditional methods struggle to conquer, including wide gaps up to 60 cm, irregularly spaced stairs, and stepping stones with distances varying from 15 cm to 35 cm. JumpER thus provides a principled and scalable approach for addressing locomotion tasks under the dual challenges of extreme underactuation and extreme terrains.
Enhanced DACER Algorithm with High Diffusion Efficiency
May 29, 2025Due to their expressive capacity, diffusion models have shown great promise in offline RL and imitation learning. Diffusion Actor-Critic with Entropy Regulator (DACER) extended this capability to online RL by using the reverse diffusion process as a policy approximator, trained end-to-end with policy gradient methods, achieving strong performance. However, this comes at the cost of requiring many diffusion steps, which significantly hampers training efficiency, while directly reducing the steps leads to noticeable performance degradation. Critically, the lack of inference efficiency becomes a significant bottleneck for applying diffusion policies in real-time online RL settings. To improve training and inference efficiency while maintaining or even enhancing performance, we propose a Q-gradient field objective as an auxiliary optimization target to guide the denoising process at each diffusion step. Nonetheless, we observe that the independence of the Q-gradient field from the diffusion time step negatively impacts the performance of the diffusion policy. To address this, we introduce a temporal weighting mechanism that enables the model to efficiently eliminate large-scale noise in the early stages and refine actions in the later stages. Experimental results on MuJoCo benchmarks and several multimodal tasks demonstrate that the DACER2 algorithm achieves state-of-the-art performance in most MuJoCo control tasks with only five diffusion steps, while also exhibiting stronger multimodality compared to DACER.
Predictive Lagrangian Optimization for Constrained Reinforcement Learning
Jan 25, 2025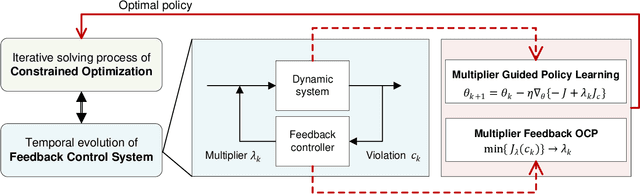
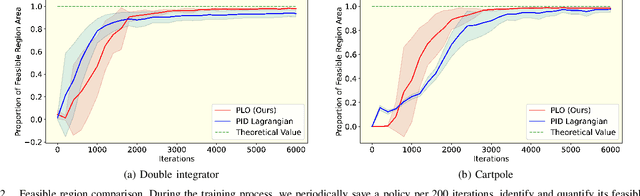
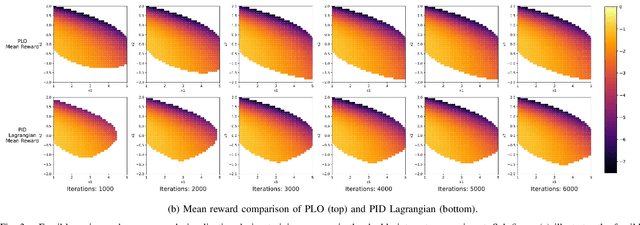

Constrained optimization is popularly seen in reinforcement learning for addressing complex control tasks. From the perspective of dynamic system, iteratively solving a constrained optimization problem can be framed as the temporal evolution of a feedback control system. Classical constrained optimization methods, such as penalty and Lagrangian approaches, inherently use proportional and integral feedback controllers. In this paper, we propose a more generic equivalence framework to build the connection between constrained optimization and feedback control system, for the purpose of developing more effective constrained RL algorithms. Firstly, we define that each step of the system evolution determines the Lagrange multiplier by solving a multiplier feedback optimal control problem (MFOCP). In this problem, the control input is multiplier, the state is policy parameters, the dynamics is described by policy gradient descent, and the objective is to minimize constraint violations. Then, we introduce a multiplier guided policy learning (MGPL) module to perform policy parameters updating. And we prove that the resulting optimal policy, achieved through alternating MFOCP and MGPL, aligns with the solution of the primal constrained RL problem, thereby establishing our equivalence framework. Furthermore, we point out that the existing PID Lagrangian is merely one special case within our framework that utilizes a PID controller. We also accommodate the integration of other various feedback controllers, thereby facilitating the development of new algorithms. As a representative, we employ model predictive control (MPC) as the feedback controller and consequently propose a new algorithm called predictive Lagrangian optimization (PLO). Numerical experiments demonstrate its superiority over the PID Lagrangian method, achieving a larger feasible region up to 7.2% and a comparable average reward.
Rocket Landing Control with Random Annealing Jump Start Reinforcement Learning
Jul 21, 2024



Rocket recycling is a crucial pursuit in aerospace technology, aimed at reducing costs and environmental impact in space exploration. The primary focus centers on rocket landing control, involving the guidance of a nonlinear underactuated rocket with limited fuel in real-time. This challenging task prompts the application of reinforcement learning (RL), yet goal-oriented nature of the problem poses difficulties for standard RL algorithms due to the absence of intermediate reward signals. This paper, for the first time, significantly elevates the success rate of rocket landing control from 8% with a baseline controller to 97% on a high-fidelity rocket model using RL. Our approach, called Random Annealing Jump Start (RAJS), is tailored for real-world goal-oriented problems by leveraging prior feedback controllers as guide policy to facilitate environmental exploration and policy learning in RL. In each episode, the guide policy navigates the environment for the guide horizon, followed by the exploration policy taking charge to complete remaining steps. This jump-start strategy prunes exploration space, rendering the problem more tractable to RL algorithms. The guide horizon is sampled from a uniform distribution, with its upper bound annealing to zero based on performance metrics, mitigating distribution shift and mismatch issues in existing methods. Additional enhancements, including cascading jump start, refined reward and terminal condition, and action smoothness regulation, further improve policy performance and practical applicability. The proposed method is validated through extensive evaluation and Hardware-in-the-Loop testing, affirming the effectiveness, real-time feasibility, and smoothness of the proposed controller.
Canonical Form of Datatic Description in Control Systems
Mar 04, 2024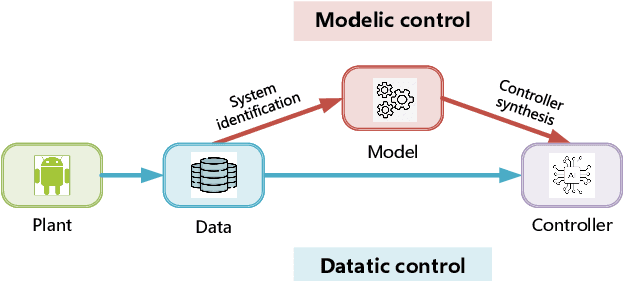
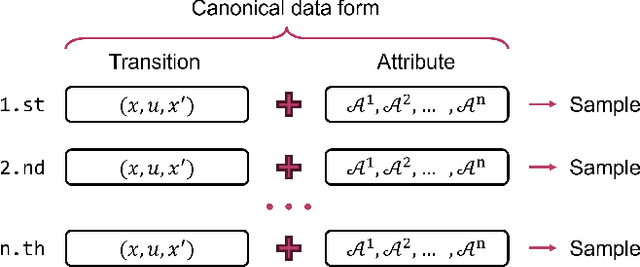

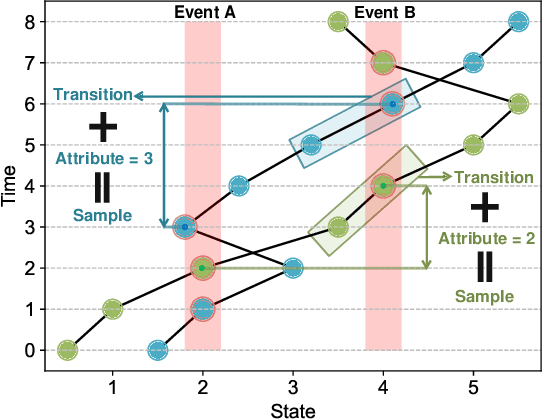
The design of feedback controllers is undergoing a paradigm shift from modelic (i.e., model-driven) control to datatic (i.e., data-driven) control. Canonical form of state space model is an important concept in modelic control systems, exemplified by Jordan form, controllable form and observable form, whose purpose is to facilitate system analysis and controller synthesis. In the realm of datatic control, there is a notable absence in the standardization of data-based system representation. This paper for the first time introduces the concept of canonical data form for the purpose of achieving more effective design of datatic controllers. In a control system, the data sample in canonical form consists of a transition component and an attribute component. The former encapsulates the plant dynamics at the sampling time independently, which is a tuple containing three elements: a state, an action and their corresponding next state. The latter describes one or some artificial characteristics of the current sample, whose calculation must be performed in an online manner. The attribute of each sample must adhere to two requirements: (1) causality, ensuring independence from any future samples; and (2) locality, allowing dependence on historical samples but constrained to a finite neighboring set. The purpose of adding attribute is to offer some kinds of benefits for controller design in terms of effectiveness and efficiency. To provide a more close-up illustration, we present two canonical data forms: temporal form and spatial form, and demonstrate their advantages in reducing instability and enhancing training efficiency in two datatic control systems.
Bridging the Gap between Newton-Raphson Method and Regularized Policy Iteration
Oct 11, 2023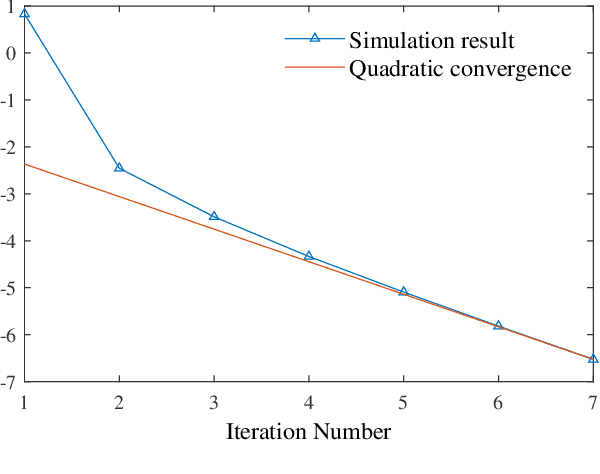
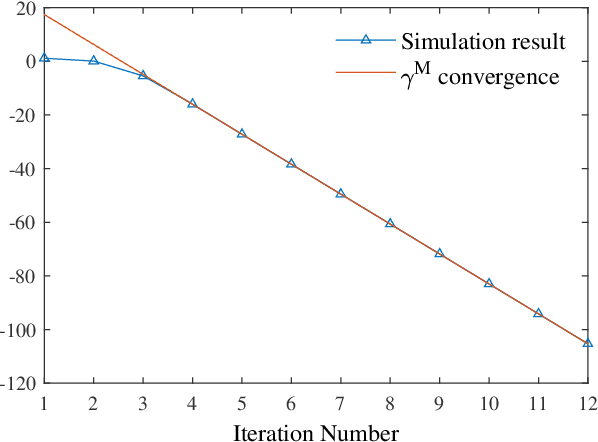
Regularization is one of the most important techniques in reinforcement learning algorithms. The well-known soft actor-critic algorithm is a special case of regularized policy iteration where the regularizer is chosen as Shannon entropy. Despite some empirical success of regularized policy iteration, its theoretical underpinnings remain unclear. This paper proves that regularized policy iteration is strictly equivalent to the standard Newton-Raphson method in the condition of smoothing out Bellman equation with strongly convex functions. This equivalence lays the foundation of a unified analysis for both global and local convergence behaviors of regularized policy iteration. We prove that regularized policy iteration has global linear convergence with the rate being $\gamma$ (discount factor). Furthermore, this algorithm converges quadratically once it enters a local region around the optimal value. We also show that a modified version of regularized policy iteration, i.e., with finite-step policy evaluation, is equivalent to inexact Newton method where the Newton iteration formula is solved with truncated iterations. We prove that the associated algorithm achieves an asymptotic linear convergence rate of $\gamma^M$ in which $M$ denotes the number of steps carried out in policy evaluation. Our results take a solid step towards a better understanding of the convergence properties of regularized policy iteration algorithms.
Improve Generalization of Driving Policy at Signalized Intersections with Adversarial Learning
Apr 09, 2022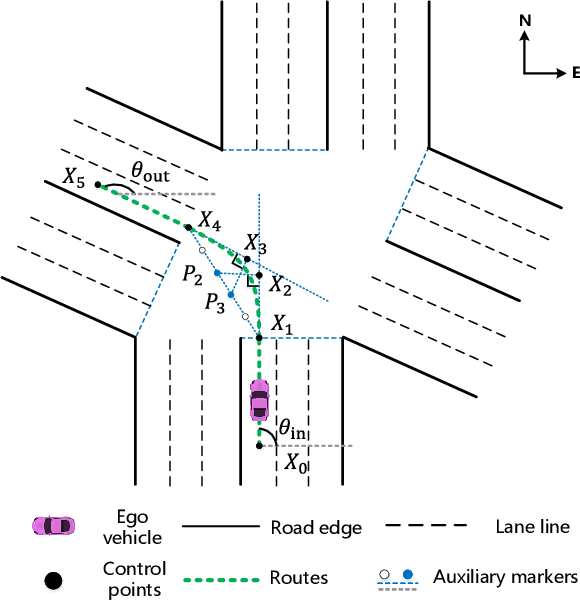
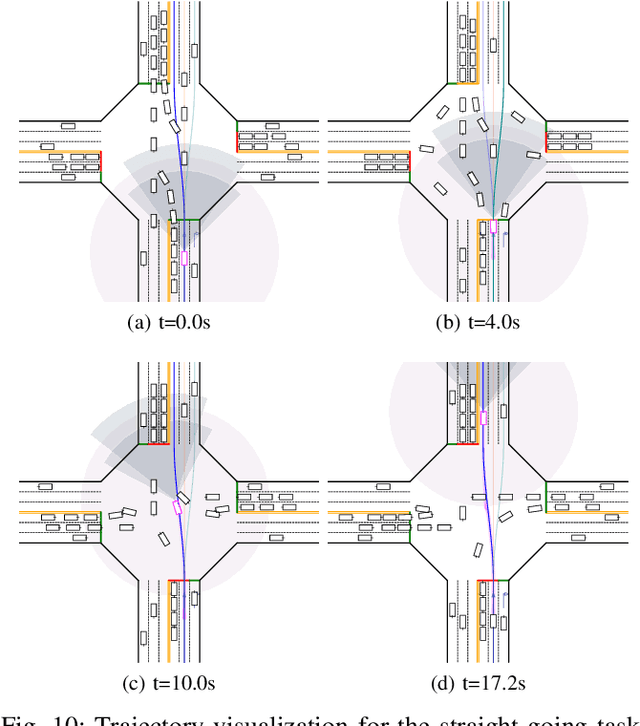
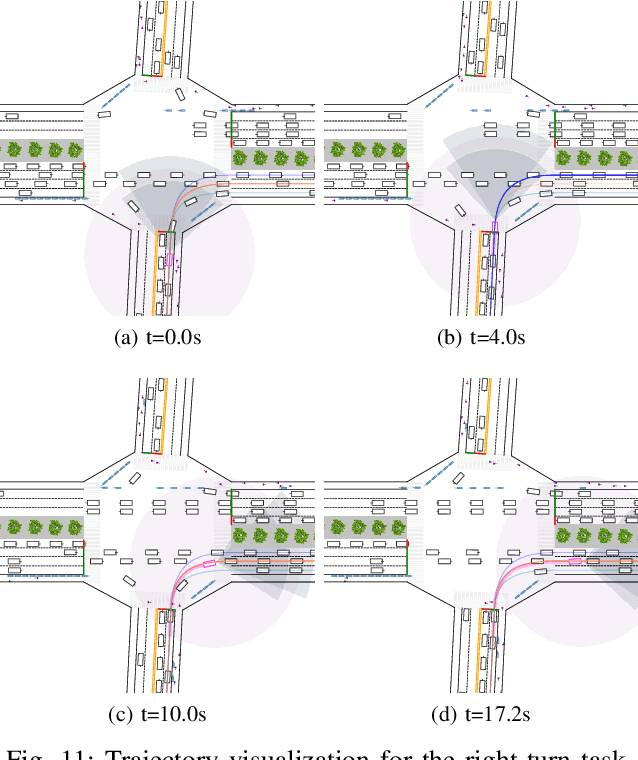
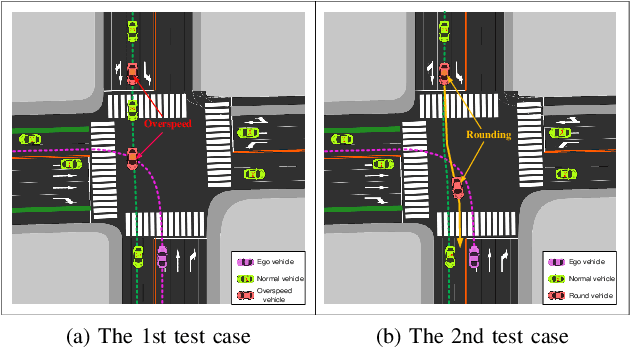
Intersections are quite challenging among various driving scenes wherein the interaction of signal lights and distinct traffic actors poses great difficulty to learn a wise and robust driving policy. Current research rarely considers the diversity of intersections and stochastic behaviors of traffic participants. For practical applications, the randomness usually leads to some devastating events, which should be the focus of autonomous driving. This paper introduces an adversarial learning paradigm to boost the intelligence and robustness of driving policy for signalized intersections with dense traffic flow. Firstly, we design a static path planner which is capable of generating trackable candidate paths for multiple intersections with diversified topology. Next, a constrained optimal control problem (COCP) is built based on these candidate paths wherein the bounded uncertainty of dynamic models is considered to capture the randomness of driving environment. We propose adversarial policy gradient (APG) to solve the COCP wherein the adversarial policy is introduced to provide disturbances by seeking the most severe uncertainty while the driving policy learns to handle this situation by competition. Finally, a comprehensive system is established to conduct training and testing wherein the perception module is introduced and the human experience is incorporated to solve the yellow light dilemma. Experiments indicate that the trained policy can handle the signal lights flexibly meanwhile realizing the smooth and efficient passing with a humanoid paradigm. Besides, APG enables a large-margin improvement of the resistance to the abnormal behaviors and thus ensures a high safety level for the autonomous vehicle.